
- 1为了实现零丢包,数据中心网络到底有多拼?
- 2基于云计算的身份认证系统设计与实现 开题报告
- 3解决3d力导向图刷新问题
- 4动手学PaddlePaddle(5):迁移学习_paddle冻结参数
- 5vue3+ts+vite+elementPlus实现文件上传导入excle给后端,并且清空上传文件后的列表,以及formData变成[object FormData]的解决方法_vue上传文件到后端
- 6点云分割方法综述_对于密度不均匀的点云分割算法
- 7数据结构: 可持久化线段树(主席树)入门_可持久化线段树java版本
- 8小程序使用web-view无法打开该H5页面不支持打开的解决方法_小程序 web-view 体验版无法打开该页面
- 9在 Unity 中获取 Object 对象的编辑器对象_unity jobject怎么取值
- 10微信小程序开发的OA会议之首页搭建
GAN详细介绍。_diminished gradient
赞
踩
目录:
- 新手村
1.1. 应用
1.2. GAN的问题
1.2.1. Mode collapse(模式坍塌)
1.2.2. Diminished gradient (梯度衰退)
1.2.3. Non-convergence(不收敛)
1.3 评价指标(IS 和FID) - 各种各样的GAN(按照创新方向分类GAN)
2.1. 网络设计
2.1.1. DCGAN
2.1.2. CGAN
2.1.3. Stacked or progressive GAN
2.2. Cost function
2.2.1. 添加新的成分(penalty)到cost function 来对特定信息进行惩罚。
2.2.2. 使用一个tips 来防止过拟合。
2.2.3. 重新设计cost function 来保证梯度不消失(non-vanishing)不爆炸(non-exploding)。
2.2.3.1. Feature matching
2.2.3.2. LSGAN
2.2.3.3. WGAN & WGAN-GP
2.2.3.4. Energy based GAN (EBGAN) & Boundary Equilibrium GAN (BEGAN)
2.2.3.5. 小总结一下loss function
一, 新手村
从2016年底,GAN已经能生成非常清晰的人脸图像,不仅如此他还能任意调节人脸的年龄,性别等特征。比我下面我们看到的styleGAN,它可以轻易的生成1024*1024的人脸高清图。

是不是很NB,一定很难对不对,我们其实可以一步一步来,要不然怎么能带你入门,带你放弃(狗头。。)

让我们从 generator(生成器)开始。
generator 是一个Generative model。一个初始的generator(weight 为随机值)只能输出随机噪声。为了让这个模型收敛,我们需要一个loss function。如果选定了一个合适的loss function 而且 模型效果还不错,那恭喜你,你就不需要GAN了。为什么呢?这是因为通常来说,这个loss function 是很难选的。loss function 无论是 l1, l2 or others,都是认为设计的,这和现实生活中未知的loss有所不同,就好比,你能否设计一个loss来计算xbox和switch之间的相似度?我想这一定很难,且很复杂,于是我们在想能不能来让另一个模型来帮我们呢?于是我们引入了discriminator来自动学习loss function。

于是我们就有了GAN的最基本的形式:generator + discriminator
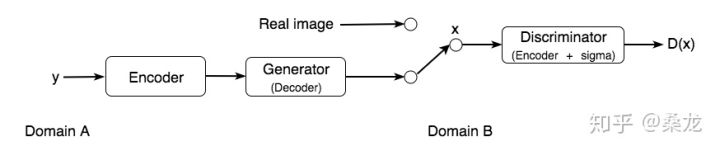
早期的GAN研究侧重于图像生成,但它已经扩展到其他领域,如动画人物、音乐视频等等。另一个流行的扩展是跨域GAN,它将数据从一类信息(比如音频)转换为另一类(图像)。

在上面的例子中,我们添加了一个 encoder 来提取音频的特征,然后是一个generator 来创建图像。真实和生成的图像被输入一个discriminator (又称编码器,后面跟着一个sigma函数),以识别它是否是真实的。
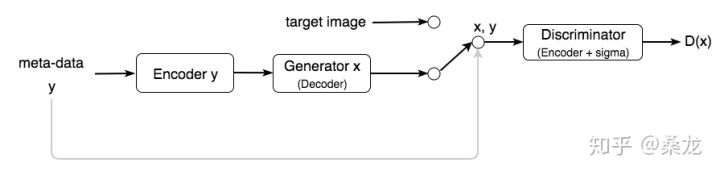
GAN也可以用 meta-data(元数据:就是关键的属性信息)来生成图像,例如通过轮廓来生成图像。

我们将meta-data输入到encoder以生成图像。我们还将原始图像(或有时是元数据)作为附加输入传递给 discriminator 以区分图像。
好吧,到现在为止,你应该知道了这些GAN的常见应用场景,你也对GAN有了一个大体的理解。是不是很神奇?那我们来看一些GAN的缺点吧。
二、GAN的问题
GAN就像它的发音,简单粗暴,但是现实不是你想gan, 想gan就能gan。GAN网络因为很多的问题,所以没有大范围使用 (排列分先后,越前越长见):
- Mode collapse(模式坍塌):generator 生成的图像都特别像。
- Diminished gradient (梯度衰退):因为discriminator太成功了,以至于gradients vanish(梯度消失)让 generator 学不到新东西。后面我们会提到WGAN,就是为了解决这事。
- Non-convergence(不收敛):模型参数振荡、不稳定且永不收敛。经常过拟合,对hyperparameter超敏感
1、模式坍塌:

其实,完全坍塌不常见,但是有一半的图像很像还是会经常遇到的。我们对这个问题的研究时期还是有限的,总体来说可以缓解,但是治标不治本。
2、梯度衰退
大家都知道deep learning 或者说CNN结构都是由梯度的反向传播来更新每层的权重值。就像你站在悬崖边,圆润的滚下去你就会达到山底,但是如果中间你被树挡住了,你就不能达到渴望的谷底,于是你就很失望,模型也就训练失败了。
3、不收敛:
下图为学习率(x轴)和FID(一种评价指标,值越高越好)关系,我们可以看到,不同参数差别较大,主要他还没规律,你说急不急。

没有合理的评价指标,以至于训练成了纯炼丹。
早期的评价指标比较原始,就是直接看图像生成的好坏,到后来这个指标就不再有用了,为什么?一是因为很多方法足够优秀,生成的图肉眼很难看出差别,另外一个原因就是这是炼丹,很多人的方法你复现不了,不是每次都成功,于是我急需一个指标。
Inception Score (IS): Inception network是一个常见的预训练好的分类模型,我们假设如果我们生成的图像骗过了这个分类器,让他给出了相应的分类,例如我们生成的人脸被分类模型也被分成了人脸,那么我们就认为我们生成的成功,这个人脸的信度就是我们IS的分数。IS主要考虑两类信息:生成图片质量和图片多样性。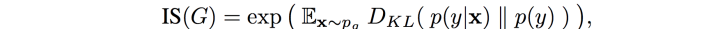
其中P(y|x)体现的是图像质量,由Inception network的分类结果决定的,值越小越好,说明这个样本越清晰。P(y)体现的图片多样性,如果生成的图片多样,y的分布应是高熵的(例如均匀分布)值越大越好,说明生成的样本在各类上分布越平均。IS的主要问题是,没办法对小批次的样本进行准确的评判,除此以外,不能反应过拟合,对参数敏感,有时候数据很好,图片很差,所以,IS指标很少用了。
Fréchet Inception Distance (FID): 也是通过Inception network 来测量真实图像和生成图像的特征差值,FID越小越好,为什么需要这个呢?因为IS不能包含所有的物体种类,可能真实图像通过Inception networks也不一定能得到较准确的分类。用差值更能体现GAN的性能。同时FID对小批次也有效。但是FID也有问题, 比如比较两个真实图片,理想的结果是为0,但是现实是非0的,这和理论相佐。
三,各种各样的GAN
GAN的设计其实有很多很trick的事情,不过作为新手的我们,如果想水一篇论文,我们主要讨论一下三个方面创新。
1. 网络设计
(1)DCGAN
DCGAN是最有名的GAN网络

技术要点:
- 将
max-pooling替换为卷积层,保住了spatial information,提升了image quality。 - 用
transposed convolution(逆卷积)来进行upsampling上采样。 - 全面消除全连接层。
- 全面采用
batch normalization(BN)
(2)CGAN
原本GAN网络的输入时一个N*1 维的高斯噪声,每一维经过映射能控制生成的什么信息,只有玉皇大帝才知道。于是,有人就像把其中一个维度不在输入噪声,而是训练数据的label信息,这样通过这个label值我们就能生成不同种类的图像了,这就是 Conditional GAN (CGAN)。
(3)Stacked or progressive GAN
如同传统boosting 检测器,你训练一个大而全的分类器很困难,但是你可以分别训练很多小的分类器,然后把他们组合在一起,就会得到一个更好的模型,训练难度也小很多。
Stacked GAN就是这个思路,他把一个GAN分离成3个GAN

progressive GAN 是另一个思路,并在超分辨率领域有很好的效果。我们先生成一个22的图片,然后44,然后越来越大。

这个三个GAN非常适合起步,也能解决大多数问题,后边的GAN大多数实在这三个GAN上做修改
2. Cost function
cost function 是GAN主要的研究方向,也是魔改GAN的重灾区,可能有的工作性能有限,不过不乏好的GAN。总结起来,无非三个方向:
一、添加新的成分(penalty)到cost function 来对特定信息进行惩罚。
在深度学习中,我们会增加一个额外的cost来满足我们希望某一特性收敛的需求。对于GAN来说,更多的研究者想用这个方法来解决mode collapse的问题。
1、Minibatch discrimination:由这种思想指导出来最有用的方法就是 Minibatch discrimination。我们将生成的图像和真实的图像划入到一个一个的batch中。对于同一batch下的不同sample(图像),我们会计算它和其他图像的似然度,并将这类信息添加到 discriminator 的 cost function 中。当mode collapse 发生时,图片的相似度上升,于是cost 也就增加了,从而惩罚generator。
二、使用一个tips 来防止过拟合。
毕竟GAN也是深度学习的结构,我们也能用深度学习的方法来进行改良。比如,One-sided label smoothing,通俗来说,原始GAN的训练过程中中,我们希望对于真实图像,discriminator能输出1。对于生成图像,discriminator能输出0。但是!discriminator 训练的太好,就会mode collapse 和 梯度消失,同时你也不能保证自己的真实图像一定不含误差(训练数据把屁股标成了脸)。所以,我们退而求其次,希望真实数据的discriminator输出不再是1,而是0.9,生成图像不再为0而是0.1。做人留一线,‘日后’好相见。
这样做可以很好的缓解mode collapse,但是治标不治本,它经常只是将坍塌的时间往后延,该塌的时间长了还是会塌。
三、重新设计cost function 来保证梯度不消失(non-vanishing)不爆炸(non-exploding)
打南边来了一个generator,打北边来了一个discriminator。generator 想骗过discriminator,但是discriminator不想被generator骗。于是,generator 没骗过,发生了gradient vanish。
从新设计coss function 就是设计一个更好的cost,来协助generator 来骗过discriminator。那为什么在原始的GAN中,generator 这么劣势呢?我们来看一下原始cost。
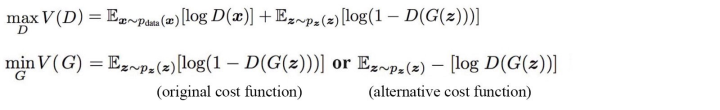
在原始的GAN中,我们有两个cost,一个是Distriminator的cost, 另一个generator的cost。我们的目的是尽可能把真实图片标记为真,生成图片标记为假。为了衡量这个loss,我们选用cross-entropy。其实GAN的训练过程就是一个minimax的游戏,G希望尽可能的减小V,D希望尽可能的增大V。在训练过程中,实在交叉梯度下降完成的,首先经generator 的参数固定住,然后训练一次discriminator(输入一个batch)。 然后固定discriminator,训练一次generator。交替往复。直到generator能骗过discriminator。他的流程图为:

原始的cost存在梯度消失的问题。为什么会消失,我们后面会说。
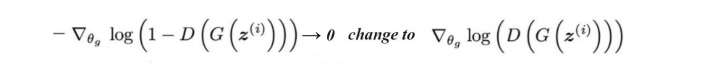
我们这里主要先梳理一下历史。
(1)、Feature matching
这里主要改良generator的loss。希望生成的图像概率分布和真实图像重合(似乎是废话。。。)。例如,我们计算真实图像和生成图像在minibatch中的特征(feature)的均值。然后我们用l2 loss来计算这两个均值的差值。缩小这个差值,我们就能得到两个均值相同的分布(睁一眼闭一眼他就是一个两个一样的分布)。所以,cost就变成了
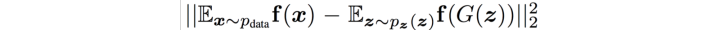
(2)、LSGAN
原始的GAN采用的JS divergency,那我们就换成别的divergency,第一个就是f-divergency。
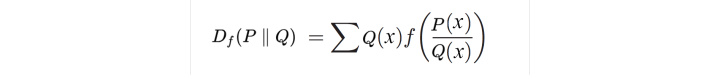
于是loss就变成了
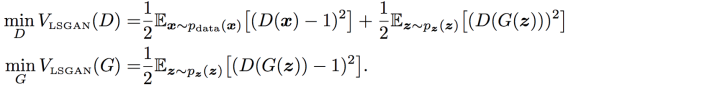
一下把一个复杂的log问题拉成我们熟悉的。
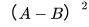
(3)、WGAN & WGAN-GP
WGAN的思想就是应用Wasserstein distance 来代替JS divergency测量两个分布的区别(你可能想了,为什么测量两个分布区别的量度,这么多?没错就是这么多,别说两个分布,两个点的距离都不只有欧式距离这一个量度,所以有很多量度是很正常的,总有一款适合你)。 那wasserstein 距离又是代表什么呢?让我们来几个例子。
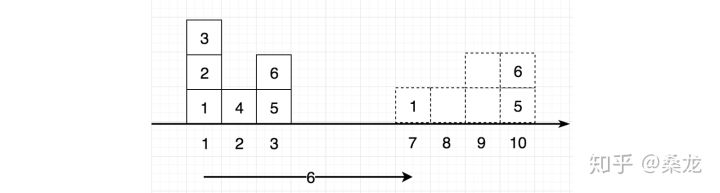
我们的目的是将左边的分布(盒子)变成右边的分布(盒子)。Wasserstein distance的核心思想就是尽量少的搬运盒子。但是如何才是最少的方法呢?我们拿一个网络来学习一下吧,于是就有了critic, 其实就是一个加强版的discriminator。为了方便起见,我们还是用D表示吧。
下面我们来看一下,在cost function 的体现。我们希望建立一个平滑的,处处可导的cost function。在下图中,蓝色为真实分布,绿色为生成数据的分布。红色为discriminator的cost function,我们发现虽然discriminator有效的区分了两个分布,但是当蓝绿两个分布没有交集时,在大量的点上的cost function为常数值,于是就猴子的哥哥狒狒(废废)了,梯度为0,generator 不能更新了。这是我们看一下wasserstein 距离,它体现为那个草绿色的线,它平滑,可导这就是我们要寻找的cost function。

它的数学定义式为:
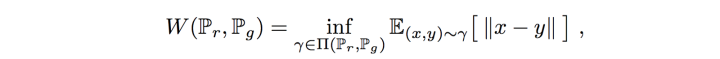
我们来对比一下GAN 和 WGAN

这里的D不再是输出0 和 1 了,而是输出一个评价指标,来评价生成的图片质量。虽然wgan看似完美,但是D必须是一个1-Lipschitz(如果不是的话,function就不再是凸函数了,你就不知道收敛到哪了)
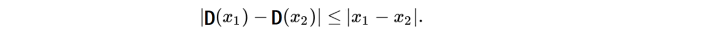
因为这个概念,wgan引入了另一个改良,权重修剪。通入来说,有时候呀weight更新来快了,高于正常值。怎么解决呢?weight变化值设一个阈值,变化太多砍了!就像老板规定,你加班加工资,但是工资有个上线,你休想通过春节加班来实现switch 自由。数学表达式为:
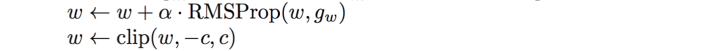
c就是这个阈值,通常为0.01,但是新的问题又来了,c的值很玄学。。。太小了,梯度消失,太大了,梯度爆照。为了让我们的炼丹更稳定一点,我们再cost function 加一个penalty (惩罚项),这就是wgan-GP。
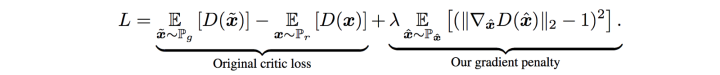
好了,具体的数学推到,我们在后边再仔细说一下。
(4)、Energy based GAN (EBGAN) & Boundary Equilibrium GAN (BEGAN)
许多GAN由 encoder 和decoder组成,并增加cost penalty 以让encoder捕获重要特性。
EBGAN:就是将 discriminator 替换为一个autoencoder (encoder + decoder)。这个新的discriminator用 reconstruction cost (MSE) 来作为cost function。通俗来说我们不再区分真实图像和生成图像,我们只是单纯得认为如果生成图像能很好被decoder还原,那么我们就认为这个图像合格。

于是我们得到cost function:
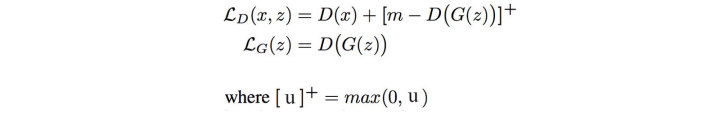
BEGAN: 和EBGAN类似,也是结合了autoencoder,但是cost function不同。它采用一个近似法来测量Wasserstein distance。
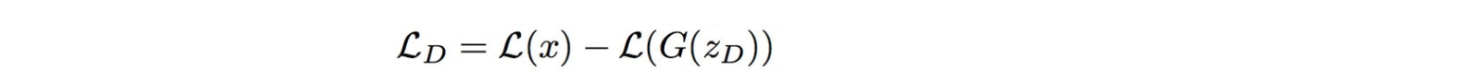
其中L为 autoencoder 的输出。
小总结一下loss function
loss function 千千万,哪个是最好的?Google Brain的有位大佬说过,loss function的贡献不如调参,虽然大家都跨wgan,说实在的在我的使用过程中经常遇见它的performance 还不如DCGAN。所以很多时候,都是仁者见仁智者见智的。不过,cost function 还是有一些明显的发展趋势。
1、discriminator 不再输出 0 和 1。而是,输出一个评价指标,这样我们就不用去考虑FID,省时省力。
2、discriminator 的输入应为生成图片+真实图片。这样的结果,让discriminator 着重于区分两幅图片这个根本的问题。于是,就有了RGAN 和 RaGAN。好了还是不挖坑了。。。
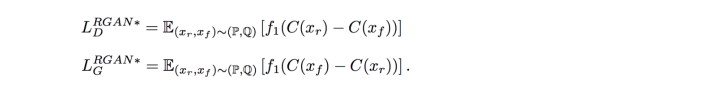
最后,我们把常见GAN的loss function 列出来,大家自己选吧,我不背锅。。。


