知识图谱用于细粒度大模型幻觉评估:兼论Langchain-RAG问答中的问题改写范式
赞
踩
来自:老刘说NLP
我们在之前的文章中有说过,Langchain作为当前RAG和AGENT的一个明星框架,已经为大家所熟知,而随着应用人数的增加,在技术层面上也出现了许多的问题和对应的优化方案。
例如,一般RAG通常将文档分割成块,嵌入其中,并检索与用户问题语义相似度高的文档块。但是,这也带来了一些问题:文档块可能包含不相关的内容,从而降低了检索效率;用户问题的措辞可能不适合检索;可能需要根据用户问题生成结构化查询(例如,用于查询带有元数据过滤功能的向量存储或SQL数据库)。
Langchain技术社区中提到RAG中的QUERY改写query-transformations,从中可以看看到QUERY的额一些可做的工作,我们先来看看这个。
知识图谱用于大模型评估也是一个很有趣的话题,之前有KOLA用于大模型性能评估的工作(https://arxiv.org/pdf/2306.09296.pdf),但其前提是需要有一个知识图谱存在,最近一个新的工作BSChecker提出了一个新的评估框架,我们再来看看这个,其知识图谱进行幻觉评估、量化和论据定位的工作,都很有趣。
供大家一起思考。
一、RAG中的QUERY改写query-transformations
Langchain技术社区(https://blog.langchain.dev/)中,列举出许多实践的思路,很有启发意义。大家可以看看。
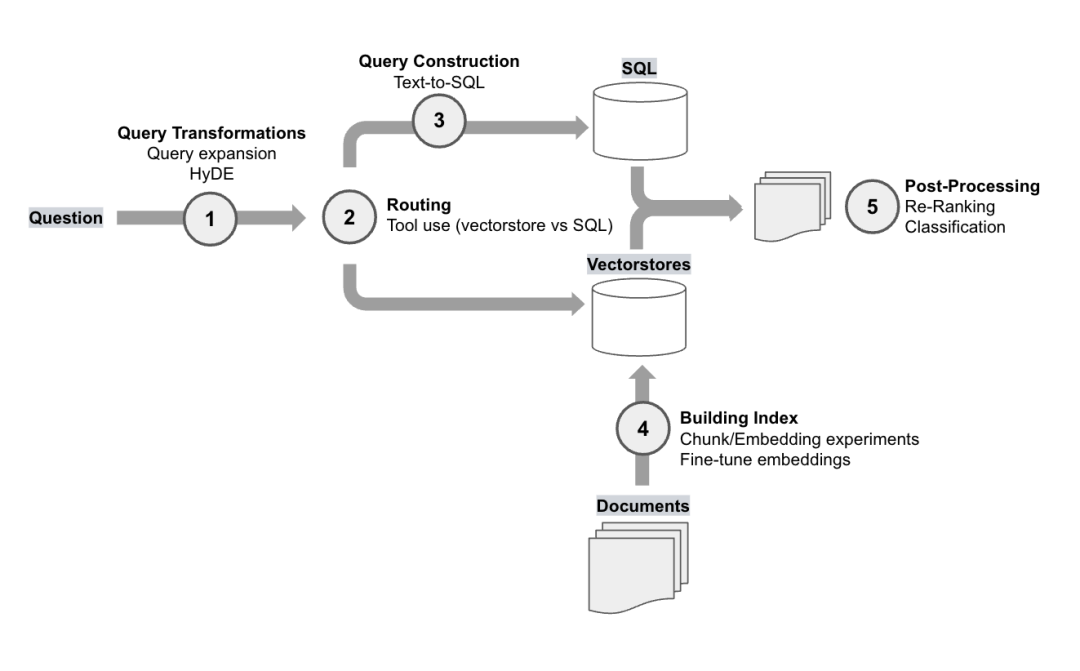
用户提出的问题在检索时可能措辞不当。有很多方法可以重写和/或扩展(扇形扩展为多个子问题)问题,从而最大限度地提高检索到相关文档的概率。
地址:https://blog.langchain.dev/query-transformations/
例如,论文(https://arxiv.org/pdf/2305.14283.pdf)使用LLM重写用户查询,而不是直接使用原始用户查询进行检索。
因为对于LLM 而言,原始查询不可能总是最佳检索结果,可以让LLM重写查询。
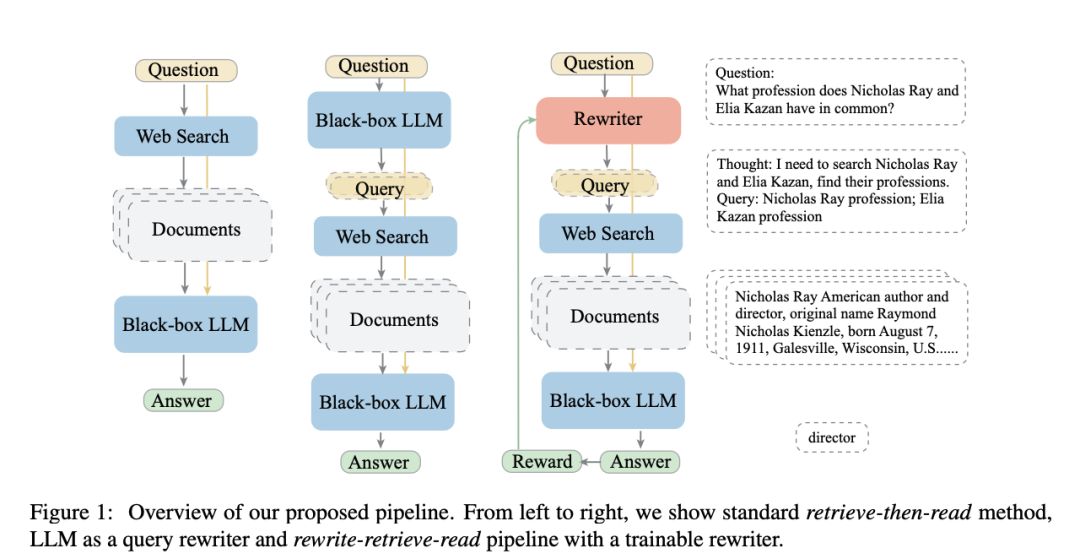
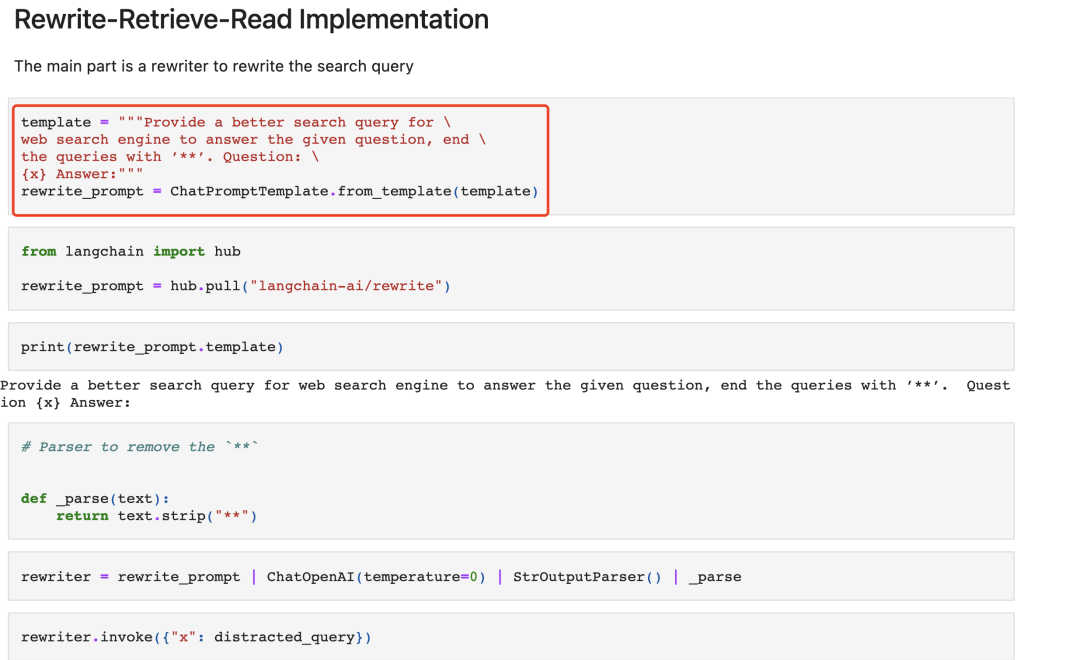
地址:https://github.com/langchain-ai/langchain/blob/master/cookbook/rewrite.ipynb中提供了实现,对应的核心Prompt如下:
又如,工作(https://arxiv.org/pdf/2310.06117.pdf)使用退一步提示,使用LLM生成"后退"(Step back prompting)问题。
这可以在有检索或无检索的情况下使用,使用检索时,"后退"问题和原始问题都会被用来进行检索,然后这两个结果都会被用来作为语言模型回复的基础。
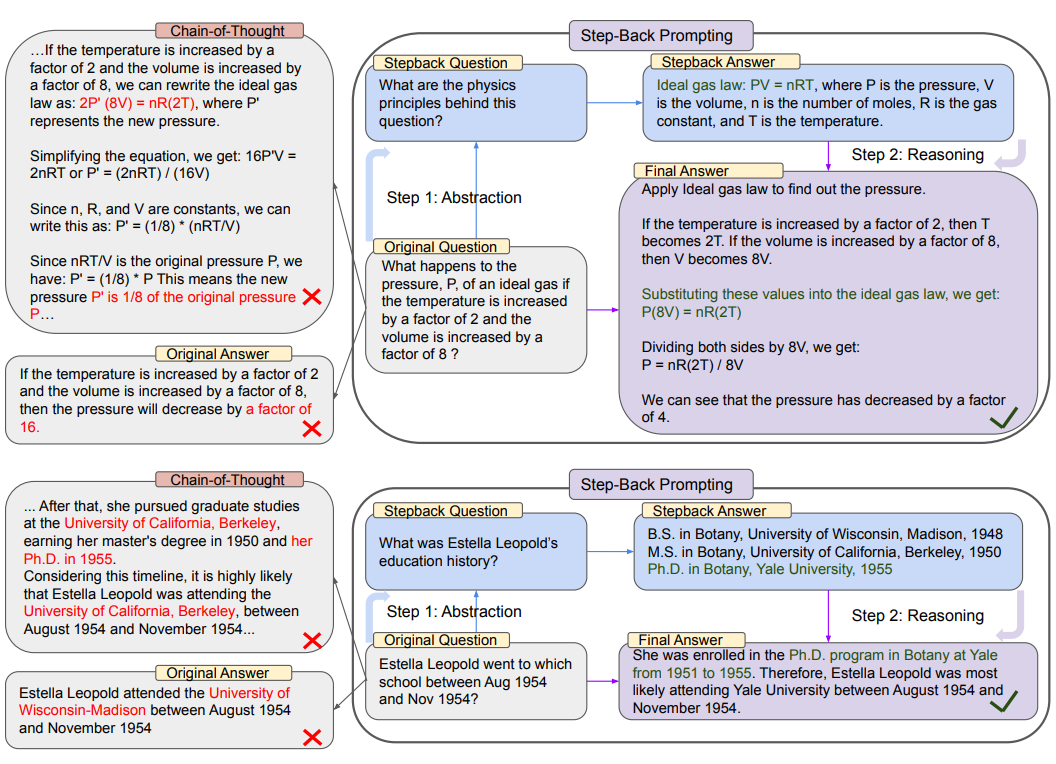
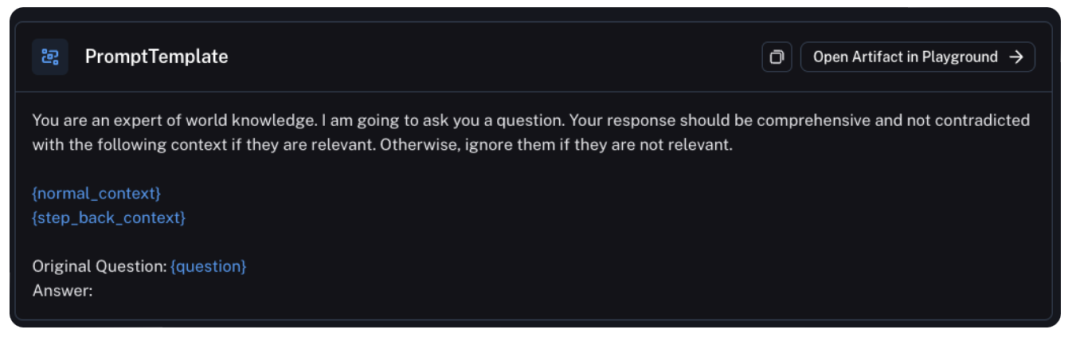
地址:https://github.com/langchain-ai/langchain/blob/master/cookbook/stepback-qa.ipynb中也提供了核心实现,对应的核心PROMPT如下:
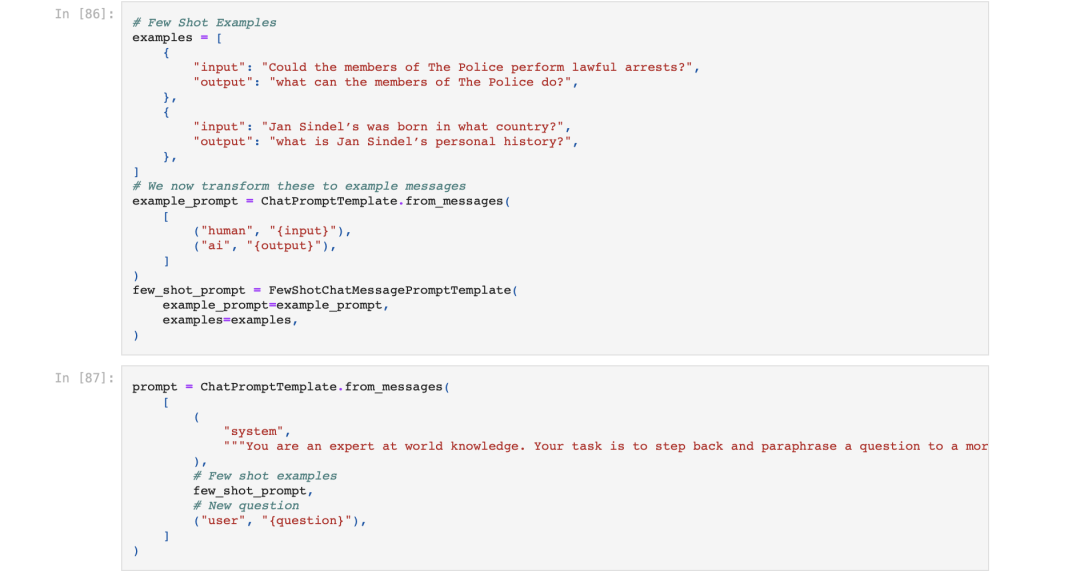
又如多重查询检索,LLM被用来生成多个搜索查询。然后并行执行这些搜索查询,并将检索结果一并传递。当一个问题可能依赖于多个子问题时。

但其中带来另一个问题,即多个召回结果之间如何进行合并排序,这个问题,通常会使用RAG的方案加以解决。
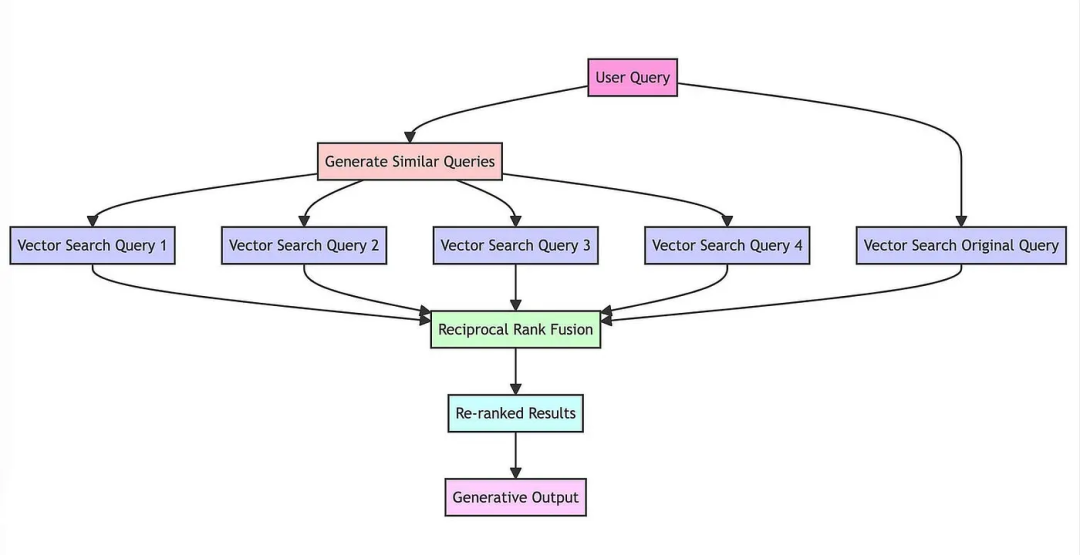
地址:https://github.com/langchain-ai/langchain/blob/master/cookbook/rag_fusion.ipynb给出了具体实现:
- "def reciprocal_rank_fusion(results: list[list], k=60):\n",
- " fused_scores = {}\n",
- " for docs in results:\n",
- " # Assumes the docs are returned in sorted order of relevance\n",
- " for rank, doc in enumerate(docs):\n",
- " doc_str = dumps(doc)\n",
- " if doc_str not in fused_scores:\n",
- " fused_scores[doc_str] = 0\n",
- " previous_score = fused_scores[doc_str]\n",
- " fused_scores[doc_str] += 1 / (rank + k)\n",
- "\n",
- " reranked_results = [\n",
- " (loads(doc), score)\n",
- " for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)\n",
- " ]\n",
- " return reranked_results"

最后是多轮问题,多轮问题通过给定已有的对话上下文,然后生成一个对应的新查询。 对应的PROMPT如下:
- Given the following conversation and a follow up question, rephrase the follow up \
- question to be a standalone question.
-
- Chat History:
- {chat_history}
- Follow Up Input: {question}
- Standalone Question:
二、知识图谱如何融合到幻觉评估BSChecker
关于大模型幻觉如何评估,我们在之前已经介绍过很多,如领域的幻觉问题,而细粒度的幻觉问题如何处理,最近读到一个亚马逊的工作《BSChecker for Fine-grained Hallucination Detection》(https://github.com/amazon-science/bschecker-for-fine-grained-hallucination-detection),也值得参考。
幻觉评估的核心问题是评估的对象以及评估的方法,评估的对象可以是段落和句子,也可以是命题,例如,有使用输出文本中的句子作为声明的(SelfCheckGPT),也有使用模型从输出文本中抽取更短的子句作为声明的(FActScore,FACTOOL)。
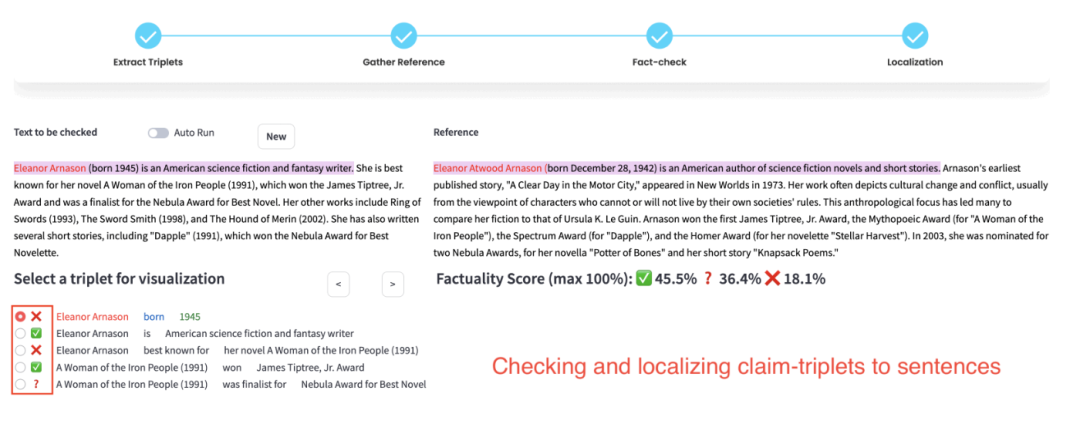
BSChecker其思想在于,与传统的段落或句子级别的分析方法不同,将大模型的输出文本分解成知识三元组,该工作将幻觉检测的最小单元称为一个声明(claim),使用知识三元组表示声明的方法,这个想法受到知识图谱的启发,在知识图谱中三元组被用来封装事实和知识单元。
此外,在计算方式上,不同于传统幻觉检测方法将整个输出文本分类为是否存在幻觉这两种类别标签,BSChecker对输出文本中的每一个声明都进行幻觉检测并分类。
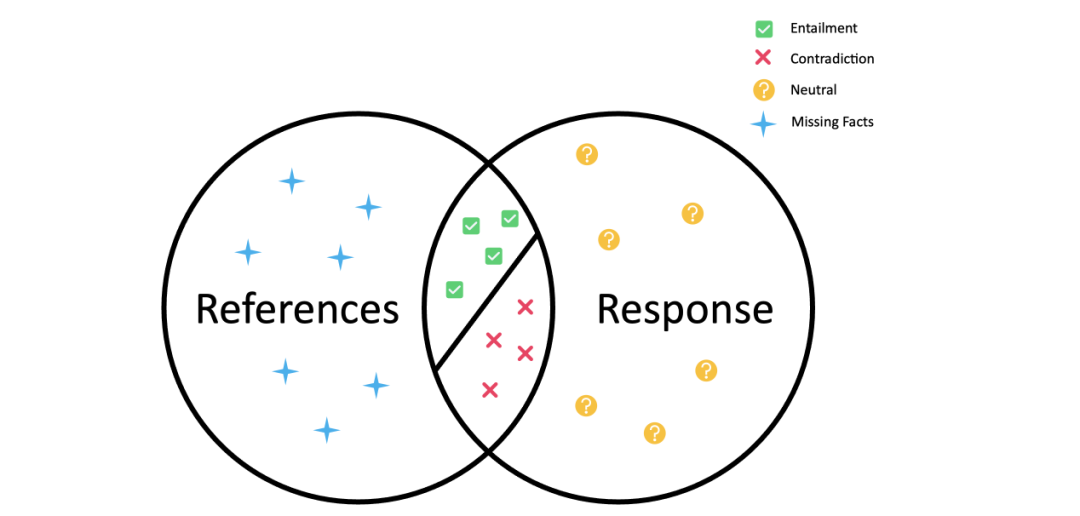
如上图所示,输出文本和其相应的参考文本之间的关系可以分成蕴涵(Entailment,图中绿勾✅)和矛盾(Contradiction,图中红叉❌)以及中立(图中的问号)
其也推出了排行榜:https://huggingface.co/spaces/xiangkun/BSChecker-Leaderboard
1、评估数据集
在评估数据集上,包括包括300个示例,每种场景对应100个示例。
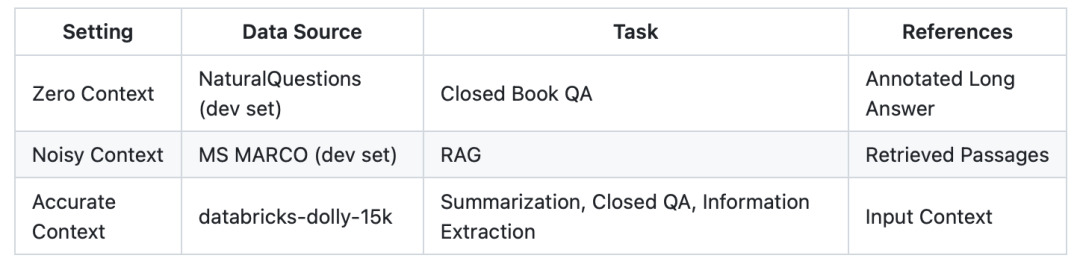
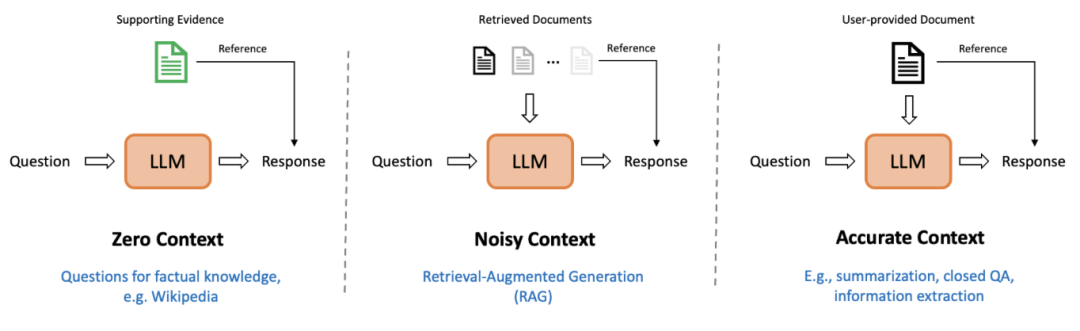
BSChecker根据输入大模型的上下文的数量和质量,设定了无上下文(如开放性问答任务),带噪声的上下文(如检索增强生成任务)和准确上下文(如文本摘要、信息抽取任务)。
2、评估指标
在评估指标上,使用每个幻觉标签出现的频率进行评估。例如,如果在某个特定的回复中,10个标签中有3个"幻觉"、5个"中性"和2个"矛盾",则该回复中"幻觉"、"中性"和"矛盾"的比率分别为0.3、0.5和0.2。将基准中所有回复中每个标签的总比率取平均值,得出最终的评估指标。
另外,也可以根据一些规则在回复级别上进行汇总,其中最激进的规则是,如果回复中至少包含一个幻觉三元组,则将其归类为幻觉。
有时,LLM通过生成诸如"对不起,没有更多的上下文,我无法提供准确的答案"这样的回复来拒绝回答问题。您能提供更多信息吗?出现这种情况时,声明提取器就无法从这些回答中提取三元组。
因此,引入了一个名为"弃权"的新标签来处理这种情况。我们将这些回复视为单个主张,在这种情况下,该特定回复的弃权率为1。如果声明提取器提取器没有为某个回复提供任何三元组,就将该回复视为弃权。
3、评估思想与实现
BSChecker具有模块化的工作流程,分为声明抽取器E,幻觉检测器C,以及聚合规则τ,将输入文本分解成一组知识三元组。每个三元组都要经过......验证。随后,根据预定义的规则,汇总各个结果,以确定给定文本的整体幻觉标签。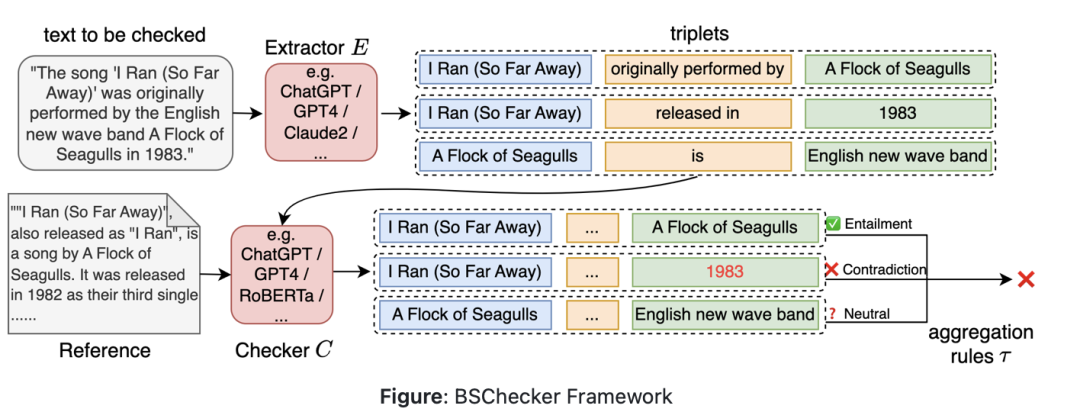
其中:
声明抽取器E使用GPT-4和Claude 2作为声明抽取器,对应prompt如下:
地址:https://github.com/amazon-science/bschecker-for-fine-grained-hallucination-detection/tree/main/bschecker/extractor
- >>> from bschecker.extractor import Claude2Extractor
-
- >>> response = (
- "Optimus (or Tesla Bot) is a robotic humanoid under development by Tesla, Inc. "
- "It was announced at the company's Artificial Intelligence (AI) Day event on "
- "August 19, 2021"
- )
- >>> extractor = Claude2Extractor()
- >>> triplets = extractor.extract(response)
- >>> print(triplets)
- """
- [['Optimus', 'is', 'robotic humanoid'], ['Optimus', 'under development by', 'Tesla, Inc.'], ['Optimus', 'also known as', 'Tesla Bot'], ['Tesla, Inc.', 'announced', 'Optimus'], ['Announcement of Optimus', 'occurred at', 'Artificial Intelligence (AI) Day event'], ['Artificial Intelligence (AI) Day event', 'held on', 'August 19, 2021'], ['Artificial Intelligence (AI) Day event', 'organized by', 'Tesla, Inc.']]
- """
在检测器上,有了为给定文本提取的三元组,第二阶段的检查器需要对所有提取的三元组预测幻觉标签。可以使用大量现有的ZERO-SHOT校验器,而无需额外的训练,主要考虑两种类型:基于LLM的检查器和基于NLI的检查器。
这一块可以查看:https://github.com/amazon-science/bschecker-for-fine-grained-hallucination-detection/tree/main/bschecker/checker
基于NLI的校验器采用更小的预训练语言模型(如RoBERTa)来执行文本分类。
- >>> from bschecker.checker import NLIChecker
-
- >>> checker = NLIChecker()
- >>> reference = (
- "`` I Dreamed a Dream '' is a song from the musical Les Mis\u00e9rables . "
- "It is a solo that is sung by the character Fantine during the first act . "
- "The music is by Claude - Michel Sch\u00f6nberg , with orchestrations by "
- "John Cameron . The English lyrics are by Neil Diamond And Herbert Kretzmer ,"
- " based on the original French libretto by Alain Boublil and Jean - Marc "
- "Natel from the original French production ."
- )
- >>> checker.check(
- ["I Dreamed a Dream", "originally from", "the stage musical Les Mis\u00e9rables"],
- reference
- ) # Entailment
- >>> checker.check(
- ["I Dreamed a Dream", "written by", "Claude-Michel Sch\u00f6nberg and Alain Boublil"],
- reference
- ) # Contradiction
- >>> checker.check(
- ["Anne Hathaway", "sang I Dreamed a Dream in", "the 2012 film adaptation of Les Mis\u00e9rables"],
- reference
- ) # Neutral
基于LLM的校验器通过查询LLM来获得预测结果:
- I have a claim that made by a language model to a question, please help me for checking whether the claim can be entailed according to the provided reference which is related to the question.
- The reference is a list of passages, and the claim is represented as a triplet formatted with ("subject", "predicate", "object").
-
- If the claim is supported by ANY passage in the reference, answer 'Entailment'.
- If the claim is contradicted with the reference, answer 'Contradiction'.
- If the reference is not relevant to the claim or DOES NOT contain information to verify the claim, answer 'Neutral'.
-
- Please DO NOT use your own knowledge for the judgement, just compare the reference and the claim to get the answer.
-
- ### Question:
- {question}
-
- ### Reference:
- {reference}
-
- ### Claim:
- {claim}
-
- Your answer should be only a single word in ['Entailment', 'Neutral', 'Contradiction']
在汇总阶段,得到整个输入文本的整体幻觉标签。根据三个类别的定义,在工作中定义并应用了以下直观而严格的聚合规则。
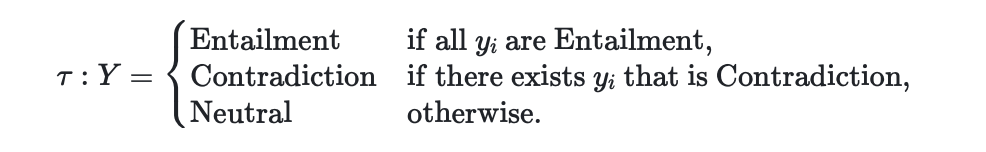
聚合阶段还有很多其他选择,如计算 "中性 "和 "矛盾 "三元组的数量,然后将比例超过预定阈值的三元组识别为幻觉反应。
在证据定位上,幻觉检测结果可以从参考文献中的某些文本span中推断出来,这就是"证据"。当获得三元组的幻觉预测后,在参考文献和被检文本中找到相应的证据和三元组很有意义,比如说作为对检查结果的解释,它们为幻觉缓解方案提供了信号。
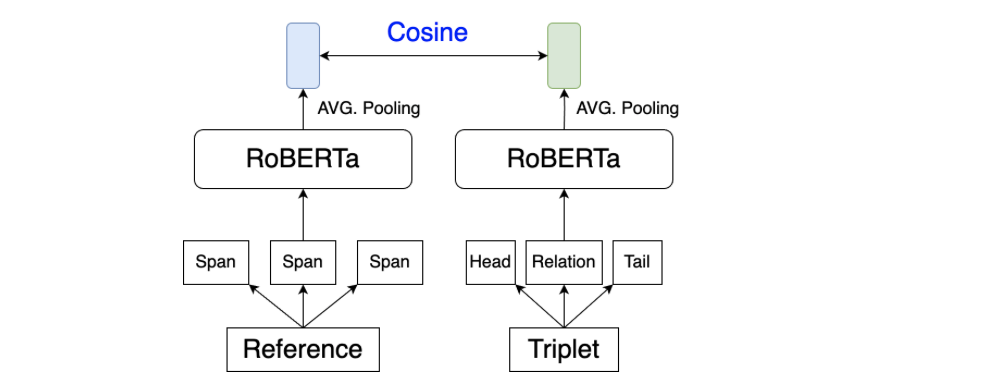
如上图所示,其实现很简单,其使用基于嵌入的简单方法将它们定位为特定的文本span,具体的,其将参考文献或被检查的文本分割成若干个SPAN,然后比较它们与三元组中元素的相似性。对于三元组中的SPAN或元素,通过RoBERTa模型获得相应的嵌入。然后,通过计算嵌入之间的余弦距离来计算成对相似度,与具有高相似度的三元组中的元素相匹配的span被视为本地化证据或三元组。
例如,可以在代码(https://github.com/amazon-science/bschecker-for-fine-grained-hallucination-detection/blob/main/bschecker/localizer/embed_localizer.py)中看到具体实现:
- if __name__ == "__main__":
- localizer = NaiveEmbedLocalizer()
- text = """Eleanor Arnason (born 1945) is an American science fiction and fantasy writer. She is best known for her novel A Woman of the Iron People (1991), which won the James Tiptree, Jr. Award and was a finalist for the Nebula Award for Best Novel. Her other works include Ring of Swords (1993), The Sword Smith (1998), and The Hound of Merin (2002). She has also written several short stories, including "Dapple" (1991), which won the Nebula Award for Best Novelette. """
- sents = [
- "Eleanor Arnason (born 1945) is an American science fiction and fantasy writer.",
- "She is best known for her novel A Woman of the Iron People (1991), which won the James Tiptree, Jr. Award and was a finalist for the Nebula Award for Best Novel.",
- "Her other works include Ring of Swords (1993), The Sword Smith (1998), and The Hound of Merin (2002).",
- ]
- triplets = [
- ["Eleanor Arnason", "born", "1945"],
- ["Eleanor Arnason", "is", "American science fiction and fantasy writer"],
- ["A Woman of the Iron People (1991)", "won", "James Tiptree, Jr. Award"]
- ]
- for triplet in triplets:
- for sent in sents:
- print(localizer.locate(sent, triplet))
最终得到的结果也很有趣,如下:

总结
本文主要介绍了三个工作,一个是RAG中的QUERY改写query-transformations,从中可以看看到QUERY的一些可做的工作,一个是引用知识图谱进行幻觉评估、量化和论据定位的工作,都很有趣。
但是,就再看知识图谱如何融合到幻觉评估BSChecker而言,整个评估缺点也很明显,例如定位是提取的反向问题,这与我们知识图谱中常说的远程监督本质上是一个问题,精度并不高,三元组可能与参考文献中的多个片段有关联或矛盾,做出判断的证据可能不仅依赖于明确的文本,还依赖于潜在的推理结构。
很有趣的工作,具体细节,大家可以进一步查看参考文献,有更多收获。
参考文献
1、https://blog.langchain.dev/query-transformations/
3、https://arxiv.org/pdf/2312.04808
3、https://github.com/amazon-science/bschecker-for-fine-grained-hallucination-detection
公众号后台回复aaai、acl、naacl直接进投稿群~
回复LLM进入技术交流群~
回复 nice 进入每周论文直播分享群~