
- 1CSS中常见选择器的用法
- 2使用shell脚本查询服务器的cpu、内存、磁盘的使用率_zxshell脚本查询cpu总数
- 3【联邦学习】联邦平均(FedAvg)_附pytorch代码实现_fedavg复现csdn
- 4Linux Netlink的使用方法_linux4.9 netlink 例程
- 5C++面试知识点总结
- 6【宝塔面板Linux】Docker阿里云盘Webdav协议并挂载本地_webdav挂载到本地
- 7独特视角解读JVM内存模型
- 8linux和windows中安装emqx消息服务器_windows安装emqx
- 9华为防火墙用CRT管理_使用crt软件如何访问华为6307防火墙
- 10使用python实现路径规划算法_python 二维路径规划
BS1065-基于数据分析+推荐算法+数据可视化的特征新闻推荐系统
赞
踩
本基于数据分析+推荐算法+数据可视化的特征新闻推荐系统,系统主要采用java,echarts,springboot,mysql,mybatis,新闻推荐算法,数据分析存储技术,实现基于互联网新闻实现针对用户阅读推荐,
系统提供新闻网站前台,系统运行后端管理系统,以及采用大数据分析可视化针对系统内部新闻及用户历史阅读实现分析展示等功能。
系统前台网站主要包含:用户登录注册,新闻推荐,用户浏览,新闻分类,个人中心,新闻详情等模块
系统后台管理主要包含:用户管理,新闻管理,浏览管理,新闻聚类,新闻数据分析可视化等。
程序设计
本基于数据分析+推荐算法+数据可视化的特征新闻推荐系统,主要内容涉及:
主要功能模块:用户登录注册,新闻推荐,用户浏览,用户历史,新闻分类,数据可视化,新闻数据聚类计算,关系图谱分析,新闻详情等模块。
主要包含技术:java,echarts,springboot,mysql,mybatis,javascript,数据分析存储技术,数据关键词提取,IK分词,协同过滤计算,kmeans,TF-IDF计算等
主要包含算法:协同过滤推荐算法,数据分析计算等
代码实现
实现基于特征的新闻推荐算法需要以下步骤:
数据预处理:对收集到的新闻数据和用户行为数据进行清洗、去重、特征提取等预处理操作,将数据转换为适合机器学习的格式。
特征工程:根据新闻和用户行为数据,提取出相关的特征,例如新闻分类、标题关键词、发布时间、用户浏览时间等。
模型训练:使用机器学习算法对特征数据进行训练,建立新闻模型和用户兴趣模型,例如朴素贝叶斯分类器、支持向量机等。
特征转换:将新闻和用户特征转换为机器学习模型可以处理的格式,例如将文本特征转换为向量特征。
推荐算法:根据用户兴趣模型和新闻模型,选择合适的推荐算法进行新闻推荐,例如基于内容的推荐算法、基于协同过滤的推荐算法等。
系统实现:将训练好的模型和推荐算法集成到新闻推荐系统中,实现新闻推荐功能。
测试和优化:对系统进行测试和优化,提高推荐准确率和用户满意度。
在实现基于特征的新闻推荐算法时,需要注意以下几点:
特征提取要充分考虑新闻和用户的特点,提取的特征要具有代表性和可解释性。
选择适合的机器学习算法进行模型训练,不同的算法具有不同的优缺点,需要根据实际情况进行选择。
在进行特征转换时,需要考虑如何将文本特征转换为机器学习模型可以处理的格式,例如使用词袋模型、TF-IDF等方法将文本转换为向量特征。
在选择推荐算法时,需要根据实际情况进行选择,例如可以考虑使用基于内容的推荐算法、基于协同过滤的推荐算法等。
在实现系统时,需要考虑如何优化系统性能、如何处理新用户和新新闻等问题。同时,也需要不断更新和调整模型和算法,以适应不断变化的数据和用户需求。
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索和文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。<String, Map<String, Double>> tfidf;
public TFIDF(List<String> documents) { wordCount = new HashMap<>(); idf = new HashMap<>(); tfidf = new HashMap<>(); //} } for (String word : wordCount.keySet()) { double idfValue = Math.log10((double) documents.size() / wordCount.get(word)); idf.put(word, idfValue); } // 计算TF-IDF for (String document : documents) { Map<String, Double> documentTfIdf = new HashMap<>(); String[] words = document.split(" "); for (String word : words) { double tfValue = (double) wordCount.get(word) / words.length; double tfidfValue = tfValue * idf.get(word); documentTfIdf.put tfidf; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
类首先计算了每个单词在每篇文章中的词频(TF),然后乘以该单词的逆文档频率(IDF)。然后,将每个单词的TF-IDF值存储在一个HashMap需要注意的是,这个实现假设所有的输入文档都已经经过了预处理,去除了停用词等无关的词汇。
系统新闻管理主要采用前后端分离模式,针对新闻数据查询封装成JSON格式,完成数据下发至系统界面端渲染,系统界面端针对JSON解析后采用javascript完成页面展示。
private Page<WhzyInfoEntity> findSimilarUserBook(Map<String, Object> params) { String beanName = (String) params.get("paramKey"); String wid = (String) params.get("wid"); Wrapper<WhzyInfoEntity> qw = new EntityWrapper<WhzyInfoEntity>() .setSqlSelect("pid", "name", "xx", "zz", "zy", "version", "pn", "wn", "bsize", "paper", "mark", "tjrq", "ptime", "imgw", "content").eq("status", 1); String matchText; if (StringUtils.isNotEmpty(wid) && !"null".equalsIgnoreCase(wid)) {//基于文章内容推荐 WhzyInfoEntity entity = selectBookInfo(wid); if (null == entity) return null; matchText = entity.getContent(); qw.ne("pid", wid); } else {//基于关键词推荐 matchText = beanName; qw.like(StringUtils.isNotBlank(matchText), "name", matchText); } String finalMatchText = matchText; if (StringUtils.isEmpty(finalMatchText)) return null; List<WhzyInfoEntity> books = this.selectList(qw); List<CompletableFuture<WhzyInfoEntity>> collect = books.stream().map(item -> CompletableFuture.supplyAsync(() -> { double similarity = Cosine.getSimilarity(finalMatchText, item.getContent()); item.setTjd(Double.valueOf(String.format("%.3f", similarity))); return item; }, executorPool)).collect(Collectors.toList()); List<WhzyInfoEntity> resultList = collect.stream().map(c -> c.join()).sorted((o1, o2) -> { Double tjd1 = o1.getTjd(); Double tjd2 = o2.getTjd(); return tjd2.compareTo(tjd1); }).filter(it -> it.getTjd() > 0).collect(Collectors.toList()); Page<WhzyInfoEntity> page = new Page<>(); Integer limit = Integer.valueOf((String) params.get("limit")); Integer cpage = Integer.valueOf((String) params.get("page")); List<List<WhzyInfoEntity>> blists = ListCF.subList(resultList, limit); page.setRecords(cpage > blists.size() ? Lists.newArrayList() : blists.get(cpage - 1)); page.setTotal(resultList.size()); page.setSize(limit); page.setCurrent(cpage); if (StringUtils.isNotEmpty(beanName)) { page.getRecords().stream().forEach(item -> item.setName(item.getName().replace(beanName, "<span style='color: #ef0000'>" + beanName + "</span>"))); } return page; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
效果实现
系统首页
新闻图谱

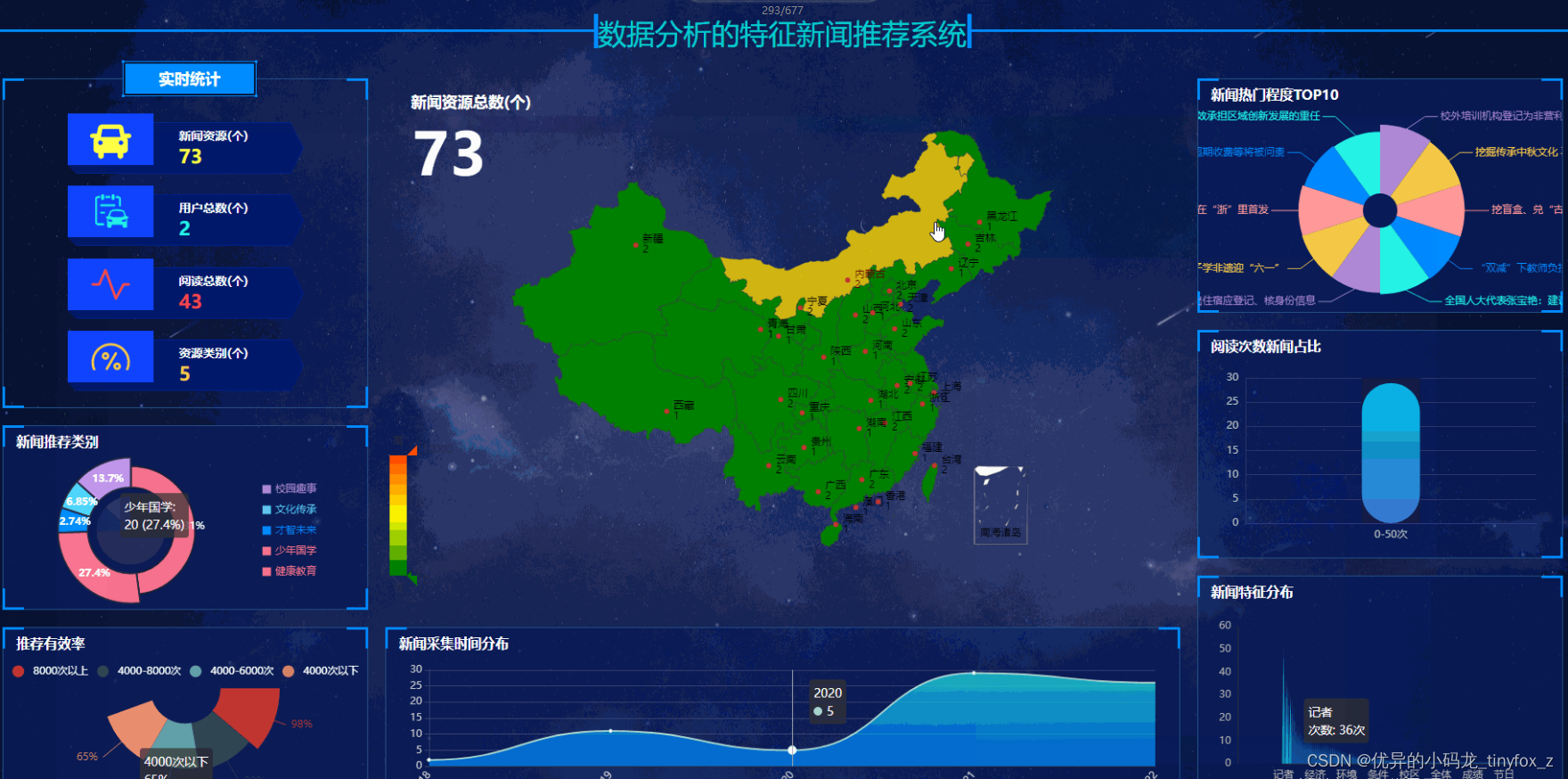
数据大屏
特征新闻推荐系统开发介绍
在当今信息过载的时代,如何高效地为用户推荐感兴趣的新闻成为了一个重要的问题。特征新闻推荐系统作为一种个性化的新闻推荐解决方案,能够根据用户的行为习惯、兴趣爱好等特征,为用户推荐感兴趣的新闻。本文将详细介绍特征新闻推荐系统的开发过程及相关技术。
特征新闻推荐系统在开发过程中涉及多种技术,包括用户行为分析、兴趣建模和推荐算法等。用户行为分析主要关注用户在新闻阅读过程中的行为,包括浏览、评论、点赞等操作。通过对这些行为进行分析,可以了解用户的兴趣爱好和需求类型。兴趣建模则是将用户行为分析的结果用模型进行表示,常用的方法有矩阵分解、神经网络等。推荐算法则是根据用户兴趣模型和新闻特征,为用户推荐感兴趣的新闻,常用的推荐算法有协同过滤、基于内容的推荐等。
在需求分析阶段,我们需要对目标用户进行深入的了解,包括他们的行为习惯、兴趣爱好、需求类型等。通过收集和分析大量用户数据,我们发现目标用户主要是年轻人,他们对科技、娱乐、社会热点等领域的新闻较为关注。此外,用户还希望系统能够提供个性化推荐,并且能够根据不同情境进行动态调整。
根据需求分析的结果,我们进行系统设计。系统采用基于Web的前后端分离架构,前端使用React框架进行开发,后端使用Spring Boot框架。系统主要分为三个模块:用户模块、推荐模块和新闻模块。用户模块主要负责用户管理和用户行为数据的收集;推荐模块根据用户兴趣模型和新闻特征进行个性化推荐;新闻模块则负责新闻的发布、更新和检索。
在实现与优化阶段,我们首先选择了合适的技术进行开发,包括Java、Python和JavaScript等编程语言,以及MySQL、Elasticsearch等数据库和搜索引擎。接下来,我们对采集到的用户行为数据进行清洗、分析和处理,提取出有用的特征信息。同时,我们采用多种推荐算法进行实验和对比,最终选择了一种效果最好的算法用于实际推荐。
此外,为了提高系统的性能和稳定性,我们还进行了大量的优化工作。例如,我们使用缓存技术来加速数据访问速度;使用负载均衡技术来分担系统负载;使用自动化测试和监控工具来及时发现和解决系统中的问题。最终,我们得到的特征新闻推荐系统具有良好的性能和稳定性,能够满足大量用户的需求。
总的来说,特征新闻推荐系统的开发和实现需要结合多种技术和方法,同时需要进行深入的需求分析、系统设计和优化工作。我们的特征新闻推荐系统已经成功上线并得到了良好的用户反馈。未来,我们将继续完善系统功能和技术水平,为用户提供更加优质的新闻推荐服务。

