- 1经典面试题:TopK问题(一种思路,两种优化,最终优化到极致)_topk 优化
- 2Android模拟器识别检测技术_antifakerandroidchecker
- 3cvc-complex-type.2.4.a: 发现了以元素 ‘base-extension‘ 开头的无效内容。应以 ‘{layoutlib}‘ 之一开头_cvc-complex-type.2.4.a: 发现了以元素 'extension-level' 开
- 4Android 布局视图生成图片_android视图树生成图片
- 5线程切换的开销
- 6ssm基于安卓的健身appcgua5【独家源码】计算机毕业设计问题的解决方案与方法_基于ssm个性化健身助手平台选题背景
- 7一个安全圈跑龙套的自白-上
- 8wpf chartcontrol 绑定数据_WPF界面开发:你真知道如何将数据绑定到Chart3D中吗?
- 9微带线的ABCD矩阵的推导、转换与级联-Matlab计算实例_s参数db转换成abcd矩阵
- 10keras之模拟线性回归(一)_# 用训练好的模型预测测试集 y_pred = classifier.predict(x_test)
李宏毅LLM——大模型+大资料的神奇力量_李宏毅 大模型
赞
踩

对应视频P12-P14
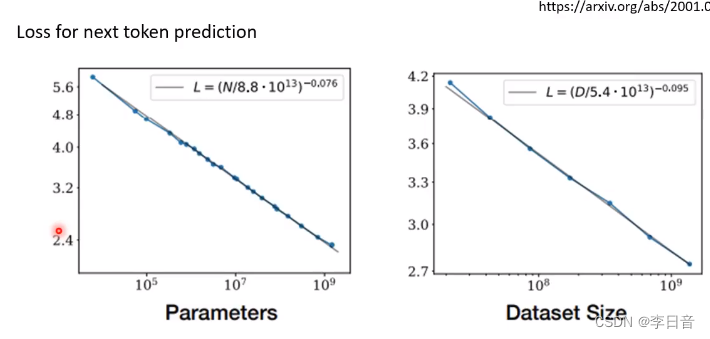
大模型的重要性
模型参数和数据集越大,文字接龙的错误率越低
顿悟时刻

当模型超过10B-20B时,会突然顿悟
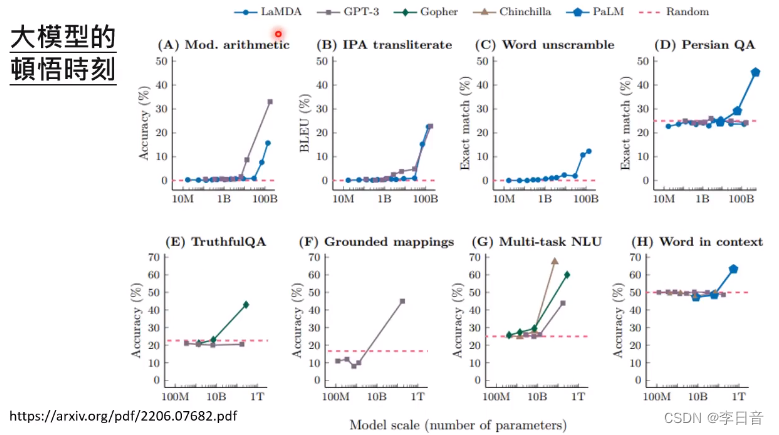
启示:不能只看最终结果。要看推理过程的提升
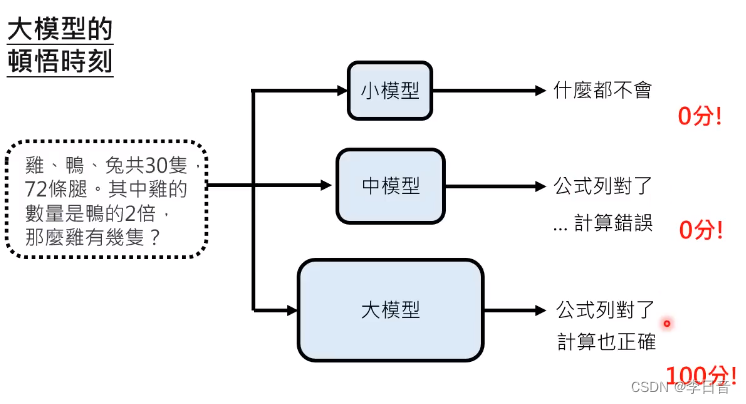
chain of thoughut、instruction tuning 只有在大模型才能起作用

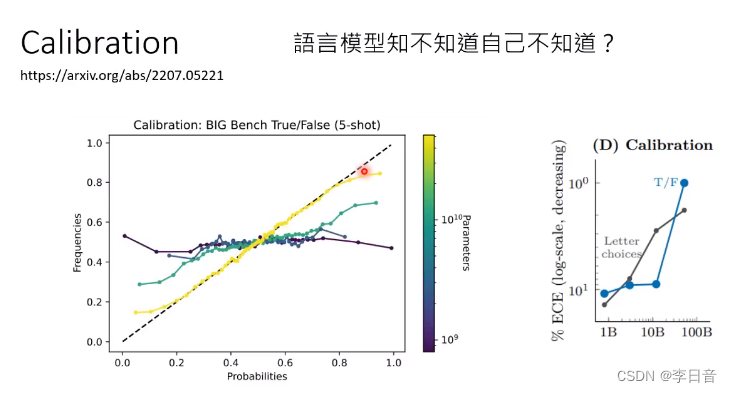
语言模型知不知道自己心虚呢?
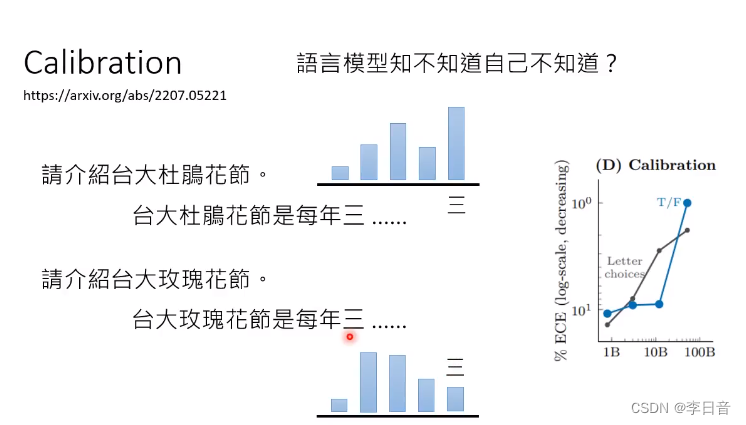
瞎掰的时候是心虚的
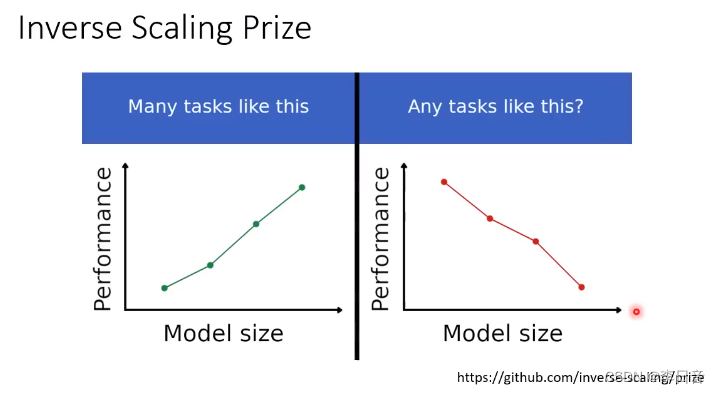
在某些任务上,有没有可能模型越大,结果越差呢?
变差只是所谓的“大模型”还不够大
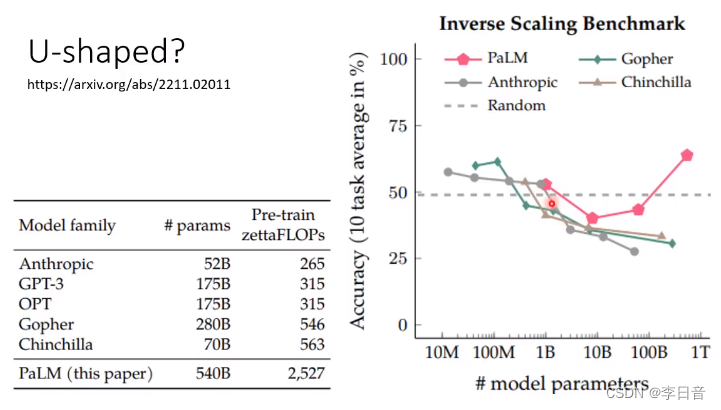
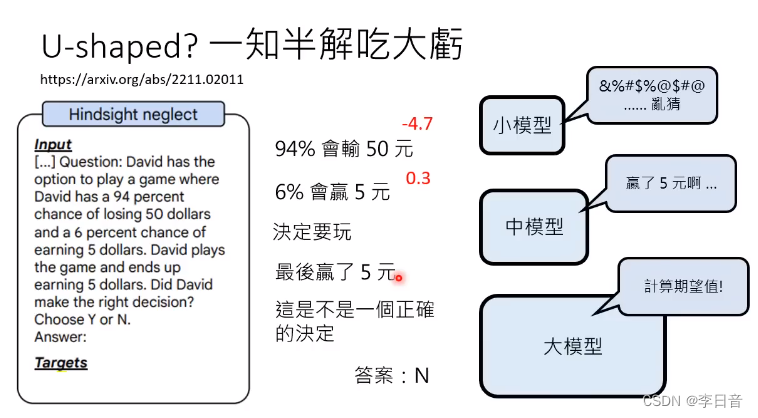
但是U型曲线怎么出现的呢?
小模型:随机乱编
中模型:一知半解
大模型:计算期望
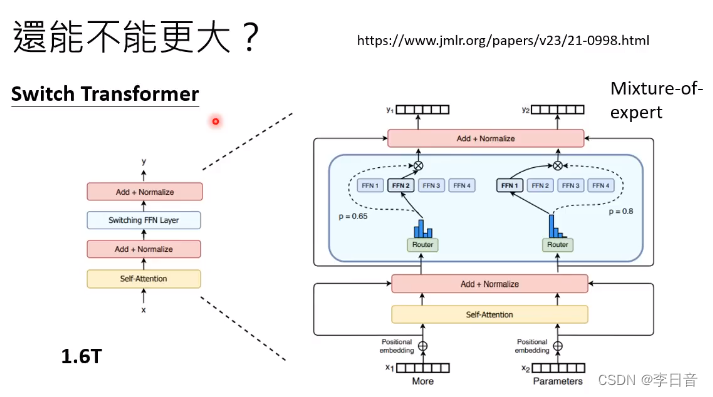
模型还能不能更大呢?
包含很多模组,但是只调用其中一部分模组
大资料的重要性
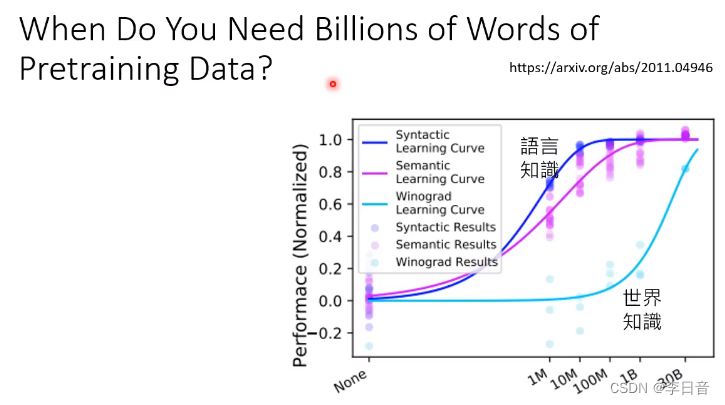
需要多少资料才能让大模型学到东西呢?
两个能力:文法用词和对世界的理解
数据预处理
内容过滤:谷歌的安全搜索,去除有害内容
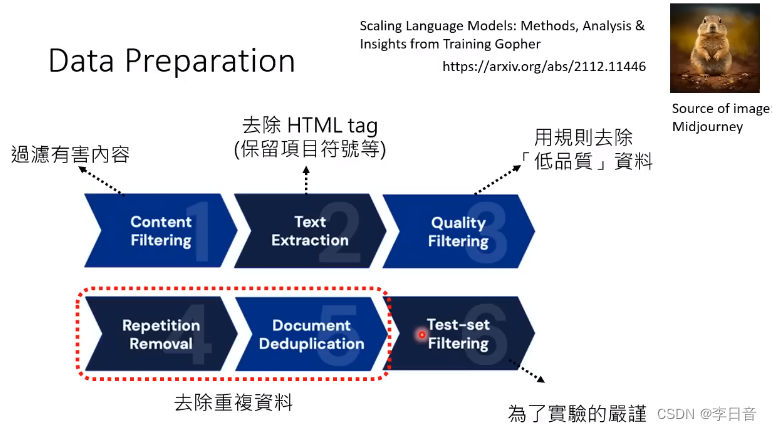
去除重复资料
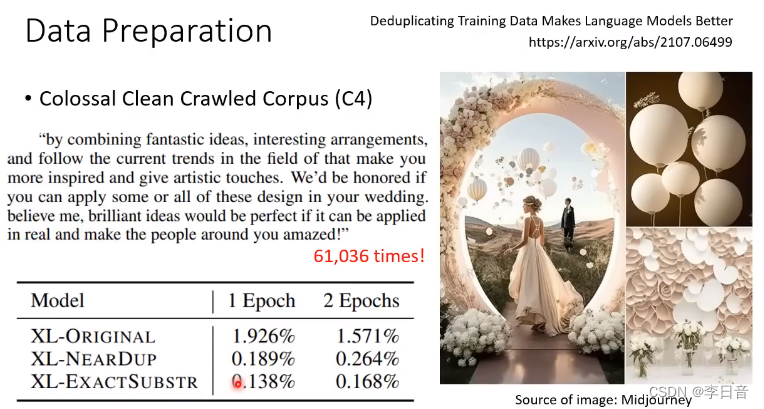
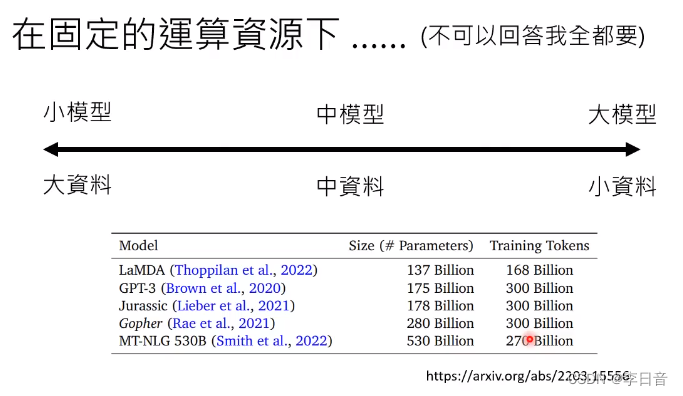
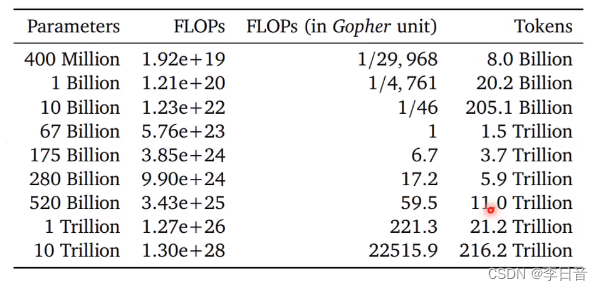
固定运算资源下,要大模型还是大资料?怎么找到平衡点?
目前的趋势是发展更大模型,但这是明智的选择吗?
固定的运算资源下,性能测试
都是U型曲线
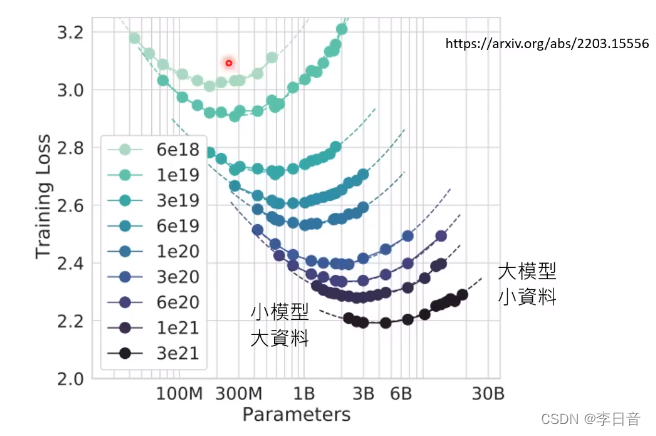
标出最低点,找出最优曲线
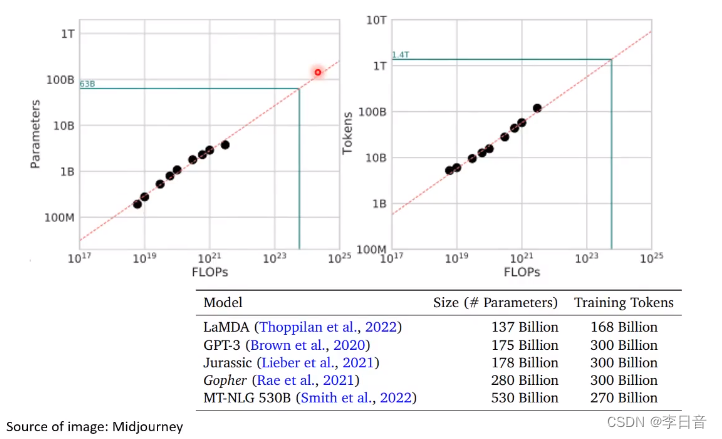
小模型大资料相较于大模型小资料更优
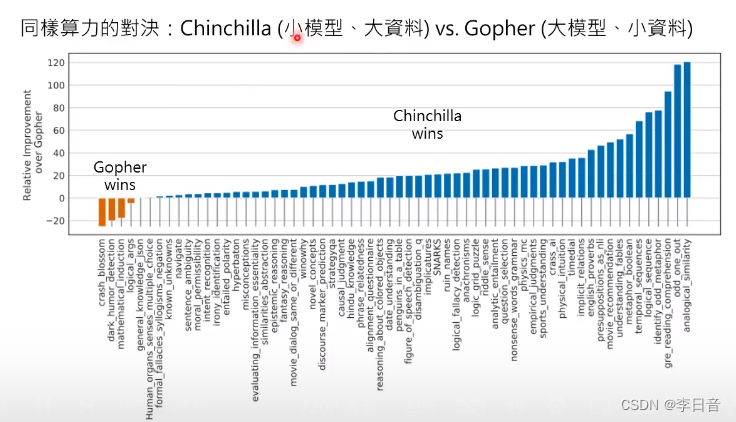
结论:现在更需要的是大资料
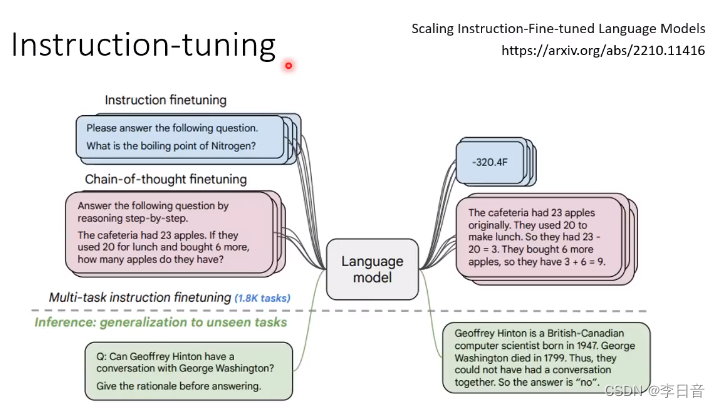
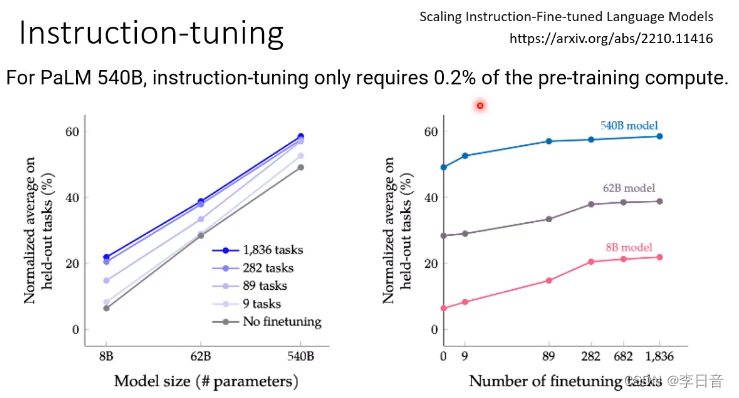
快速让模型变强,文字接龙的正确率并不代表结果,Instruction-tuning可以帮助我们得到更好的结果
花费很少的运算资源就可以达到很显著的提升
例子:如果不做Instruction-tuning,大模型会以为我们需要更多的数学题,而做了Instruction-tuning后,大模型就会知道我们需要的是正确的答案

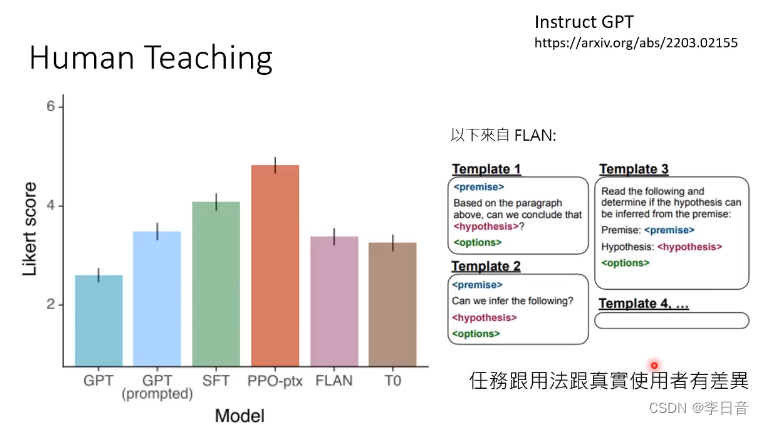
对决:小模型经过人类老师的训练可以打败不经过训练的大模型
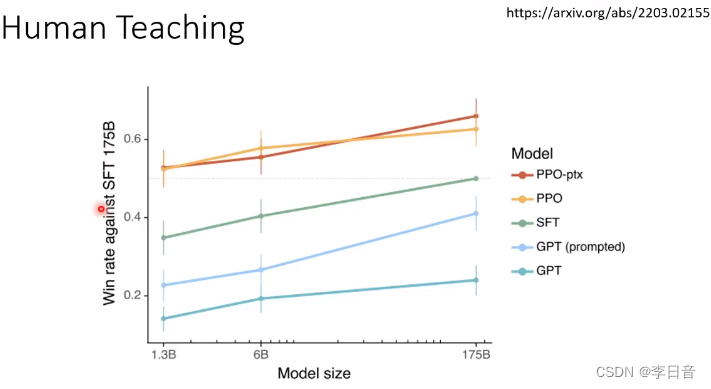
应该根据人类的使用来调整模型
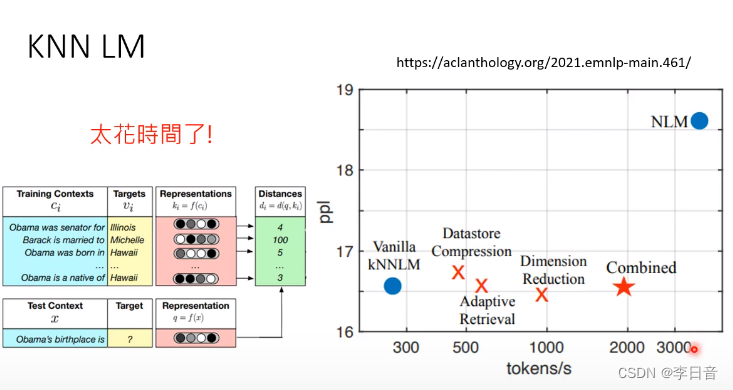
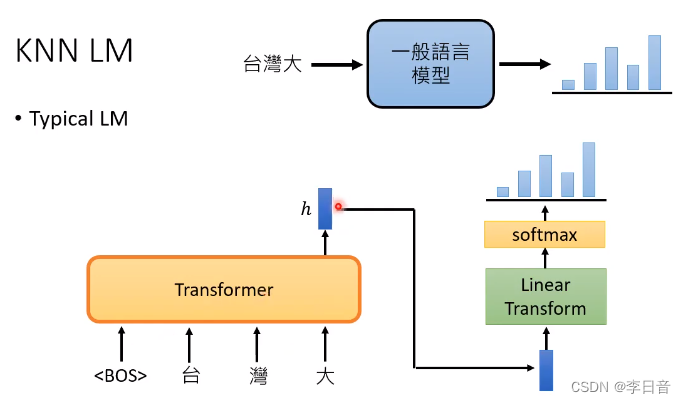
不一样的做法:KNN LM
一般的LM的方式:
KNN LM的做法:
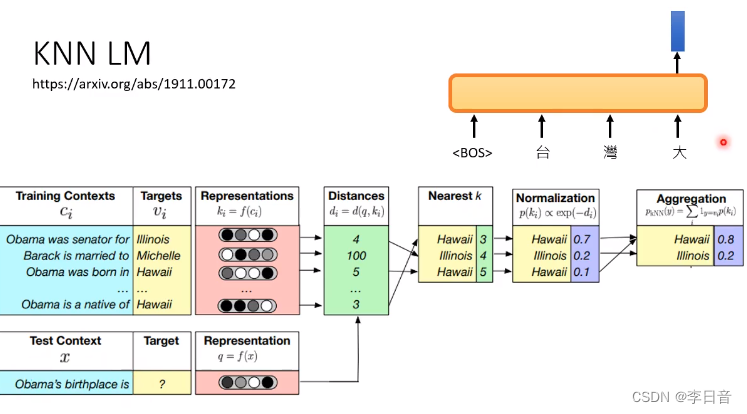
100M资料+外加3B资料,可以比3B资料结果更好。
KNN-LM不能单独使用,需要和LM结合。
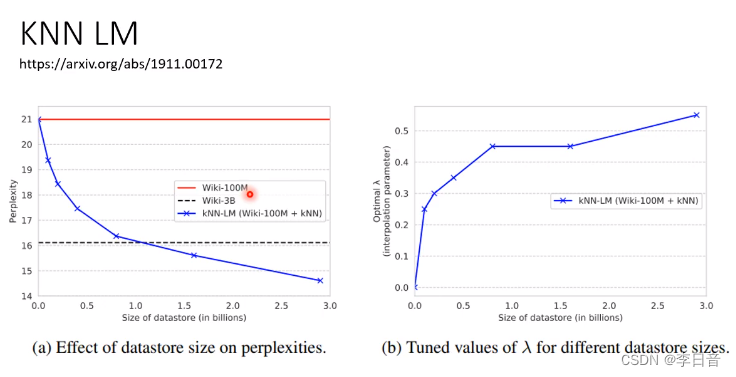
为什么KNN LM没有流行?
计算距离花费太多时间,是一般LM速度的十分之一