
- 1智能聊天机器人的技术综述_智能语音聊天机器人的工作原理
- 2基于java的网上订餐管理系统设计与实现_基于java的订餐管理系统
- 3手机接收短信验证码_csdn 手机接收验证码
- 4服务端高并发分布式架构演进之路(建议收藏)
- 5通俗易懂,十分钟读懂DES,详解DES加密算法原理,DES攻击手段以及3DES原理_des算法
- 6一张图弄懂gl,glu,glut,glew,glfw......之间关系_gl glu glut glef
- 7NLP数据预处理与词嵌入_nlp英文数据预处理
- 8老黄现场演示与游戏NPC聊天!大模型开口建议玩家去找犯罪头目,网友:西部世界成真...
- 9前端简单理解MVC、MVP、MVVM框架_mvc框架是前后端分离吗
- 10NLP自然语言处理学习笔记_nlpqi
EMNLP2023 | 让模型学会将提示插入到合适的中间层
赞
踩

深度学习自然语言处理 原创
作者:cola
现有的提示微调方法基本是人工选择提示层,而人工选择将提示插入到哪些层次并非一定合理,这导致了很大程度上限制提示微调发挥潜能。我们的模型(SPT)可以让模型自己学习应该在哪些中间层插入提示,从而最大化地发挥提示微调的作用。
论文:
Improving Prompt Tuning with Learned Prompting Layers地址:
https://arxiv.org/pdf/2310.20127
背景介绍
预训练语言模型(PLMs)在大多数NLP任务上实现了SOTA的性能,通常结合全参数微调发挥作用。但是全参数微调的方法需要针对每个下游任务更新全部模型参数,这使得GPU内存和存储成本很大,因此参数高效微调(PETuning)+PLMs的范式出现了。该类方法可以微调较小的参数量来降低训练成本。
提示调优便是一种PETuning的方法,它在输入序列前添加一系列软提示,并只针对新增提示进行调优,一定程度上提升了参数效率,但仍有性能较低和收敛速度较慢等劣势;有研究人员提出在所有隐藏层都添加软提示来提升微调的性能,但这种方法需要大量的训练步骤才能使模型具有竞争力;另有一些研究通过提示生成器生成实例感知的软提示,并将提示新增到模型的中间层来提升微调的性能。但是上述方法都是基于启发式的策略来确定插入提示的位置。
我们首先进行了一个试点实验,以证明提示符插入策略进行简单修改可以获得比可调参数的基线更好的性能。因此,我们提出了选择性提示调优(SPT)框架,它自动学习将提示插入预训练模型(PTMs)的最佳策略。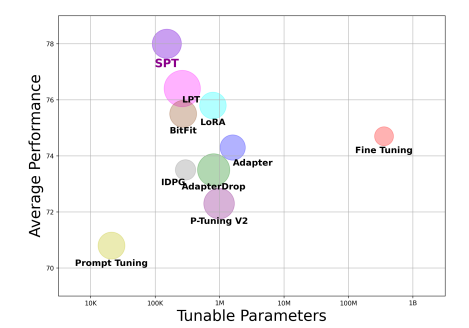 如图为各个模型的表现。横轴为训练参数量,纵轴为平均表现。
如图为各个模型的表现。横轴为训练参数量,纵轴为平均表现。
问题定义
对于PTM全参数微调,如果输入是单个句子,则输入样本通常被重新表述为,如果输入是句子对,则变为。在PTM对输入进行编码后,将使用的最终隐藏状态来预测分类标签。在提示微调中,下游任务被重新表述为掩码语言模型任务,以缩小预训练和微调之间的差距。具体来说,我们在词嵌入中插入随机初始化的软提示符,使用不同的人工设计模板修改原始输入,并使用进行任务适应。例如,在单句任务中,输入将被转换为模板: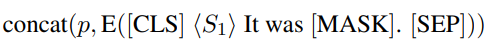 然后,我们将源标签映射到的词汇表中的一些标签词,然后最终的隐藏状态输入到掩码语言模型(MLM)来预测标签词。下游任务中PTM和MLM是冻结的,只有软提示会改变。我们针对是在词嵌入还是在某些中间层插入实力感知的提示进行了研究。为方便起见,将词嵌入层称为PTM的第0层,将新插入提示的层称为提示层(PLs),在提示层,我们用提示生成器从第层给定输入隐藏状态来生成提示。
然后,我们将源标签映射到的词汇表中的一些标签词,然后最终的隐藏状态输入到掩码语言模型(MLM)来预测标签词。下游任务中PTM和MLM是冻结的,只有软提示会改变。我们针对是在词嵌入还是在某些中间层插入实力感知的提示进行了研究。为方便起见,将词嵌入层称为PTM的第0层,将新插入提示的层称为提示层(PLs),在提示层,我们用提示生成器从第层给定输入隐藏状态来生成提示。
方法
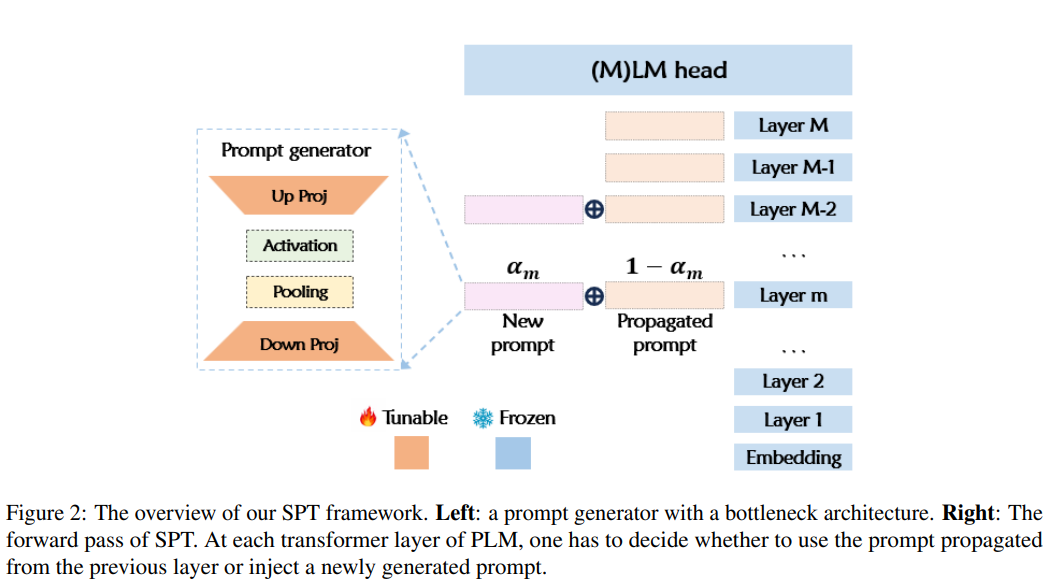
提示生成器
提示生成器是一个具有瓶颈架构的简单前馈层。它首先通过线性层将PTM的隐藏状态从维映射到维。然后通过平均池化操作得到长度为的提示符。池化后的提示将通过激活函数,并通过另一个线性层向上投影回维度。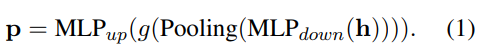 我们使用参数超复杂乘法(PHM)层来减少和的参数。PHM将线性层的权重矩阵替换为Kronecker积的和,因此参数复杂度为,使投影层的参数最多减少。
我们使用参数超复杂乘法(PHM)层来减少和的参数。PHM将线性层的权重矩阵替换为Kronecker积的和,因此参数复杂度为,使投影层的参数最多减少。
提示超网络
假设参数预算允许个提示层。由于并非所有提示层对性能的贡献都相同,因此应该只选择一小部分提示层作为提示层,以避免可调参数的冗余。因此,我们初始化了一个提示超网络,其中嵌入层和所有中间层都有一个由可学习概率门控制的提示生成层。引入零初始化的可学习参数,第层的可学习门为: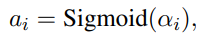 其中可看作第层激活提示生成器的概率。超网络的每一层,提示符由前一层传播的提示符和第层提示符生成器生成的提示符组成:
其中可看作第层激活提示生成器的概率。超网络的每一层,提示符由前一层传播的提示符和第层提示符生成器生成的提示符组成: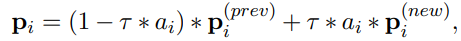 其中是一个超参数,决定在第层生成新提示时是否丢弃前一层的提示。
其中是一个超参数,决定在第层生成新提示时是否丢弃前一层的提示。
通过优化,概率门的值将向0或1移动,作为提示层的重要性分数。将接收到概率门值最高的前层设置为满足参数预算的提示层。
优化提示超网络
我们将可学习概率门的所有参数视为结构参数,记为,并通过双级优化对其进行优化。将超网络的提示生成器参数表示为ω。双级优化以提示生成器的优化参数ω*为条件。在每个epoch,训练集被分成 and 。内部和外部的优化是在这两个单独的分割上进行的,以避免过度拟合。因此优化目标为: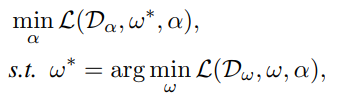 其中是给定下游任务的目标函数。用交替优化策略逼近上述双层优化问题。用来自的批量样本计算提示生成器的梯度,在上计算的梯度。
其中是给定下游任务的目标函数。用交替优化策略逼近上述双层优化问题。用来自的批量样本计算提示生成器的梯度,在上计算的梯度。
虽然DART被广泛应用,但已知会产生不稳定的梯度和次优性能。因此,我们提出了两种改进结构参数优化的新技术。
重参数化概率门
DART的优化没有明确地考虑不同层之间的权衡,因此我们给引入一个重参数化步骤: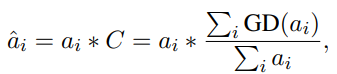 其中将参数从计算图中分离出来,并且参数永远不会有梯度。上面的等式不会改变的值,因为的值是1,则:
其中将参数从计算图中分离出来,并且参数永远不会有梯度。上面的等式不会改变的值,因为的值是1,则: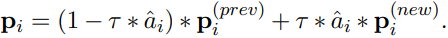 现在的梯度由下式给出:
现在的梯度由下式给出: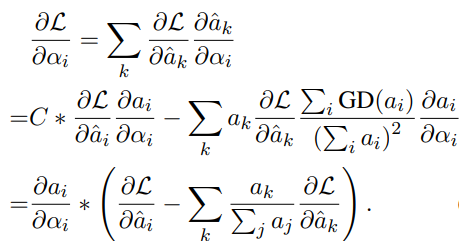
架构一致性学习
由于我们想要的最终优化模型是稀疏的,大多数层的提示生成器都被修剪了。为了缩小超网络与最终模型之间的差距,我们为每个可学习的概率门分配一个均值的伯努利分布随机掩码。因此有: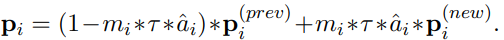 现在,我们要求相同的输入经过两次前向传递,一次是应用了架构掩码,一次是关闭了架构掩码,导致输入样本的隐藏表示和不同。除了任务的目标函数之外,我们现在还引入了一个一致性正则化目标:
现在,我们要求相同的输入经过两次前向传递,一次是应用了架构掩码,一次是关闭了架构掩码,导致输入样本的隐藏表示和不同。除了任务的目标函数之外,我们现在还引入了一个一致性正则化目标: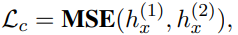 其中MSE是均方误差损失函数。
其中MSE是均方误差损失函数。
我们运用一致性学习的思想来增强可学习概率门的优化过程。直观地说,当不同的提示生成器集合被修剪时,这个正则化项鼓励超级网络输出一致的隐藏状态。它确保了每个提示生成器都经过良好的训练,并在超网络和最终离散SPT模型之间架起了桥梁。因此,的优化可以更好地反映每个提示生成器的贡献,从而最终学习到的模型将获得更好的性能。
实验
小样本场景
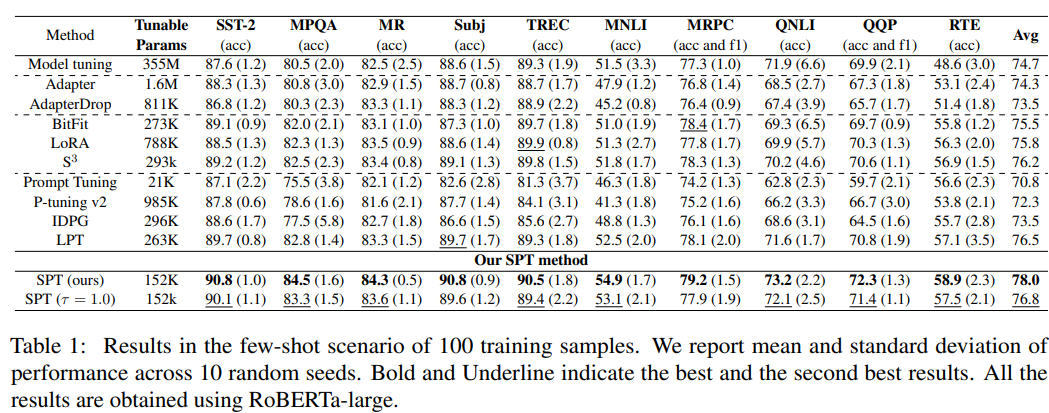
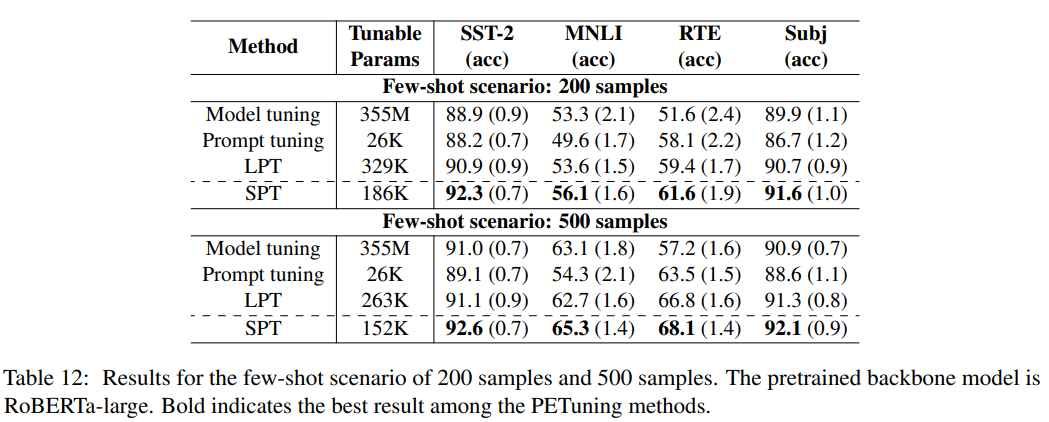
全数据场景
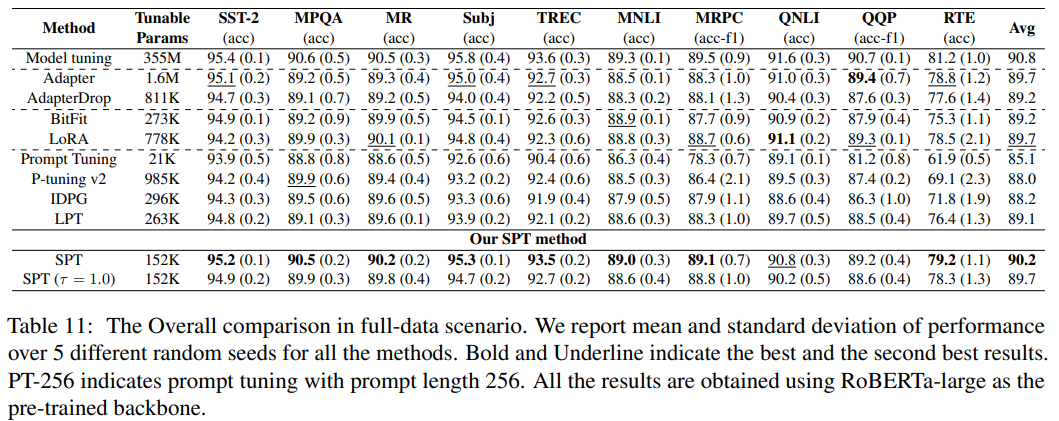
分析和消融学习
 发现
发现
图3表明:(a)所有任务都决定在嵌入层(第0层)和前四个transformer层之后插入提示符。(b)RoBERTa-large的第10~19层经常被选为提示层。(c)SPT丢弃最后四层。
提示层数的影响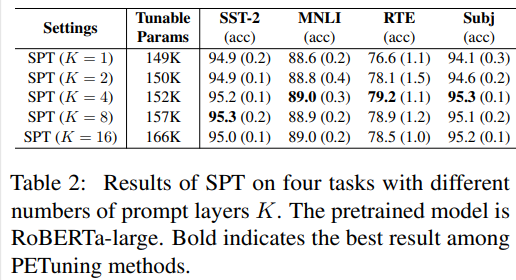 提示长度的影响
提示长度的影响 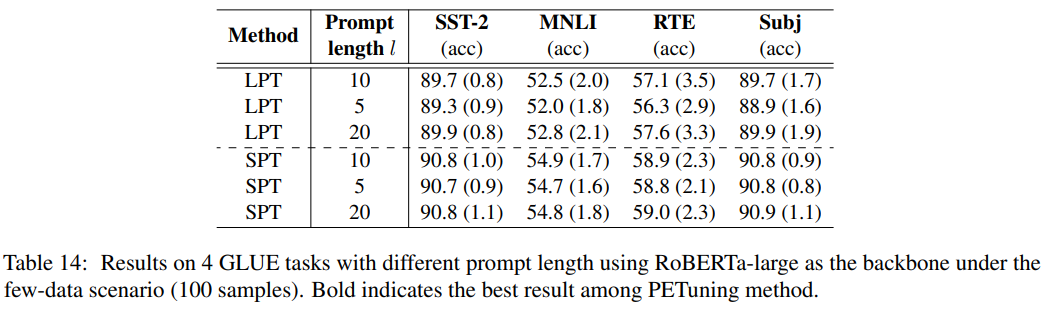 消融实验
消融实验 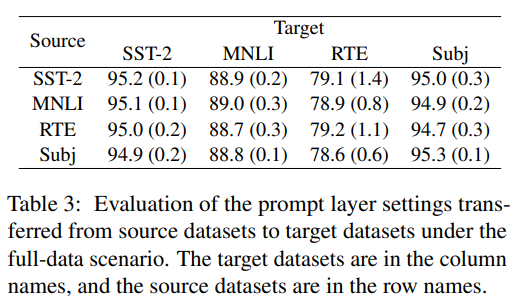
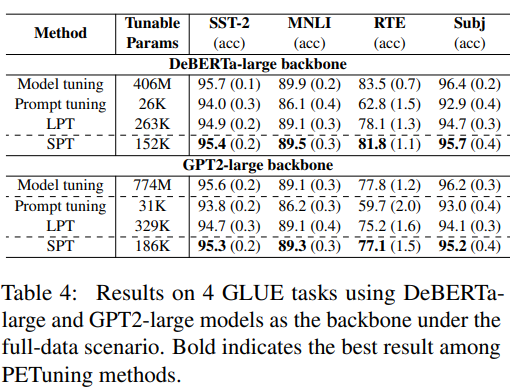
大语言模型上实验结果
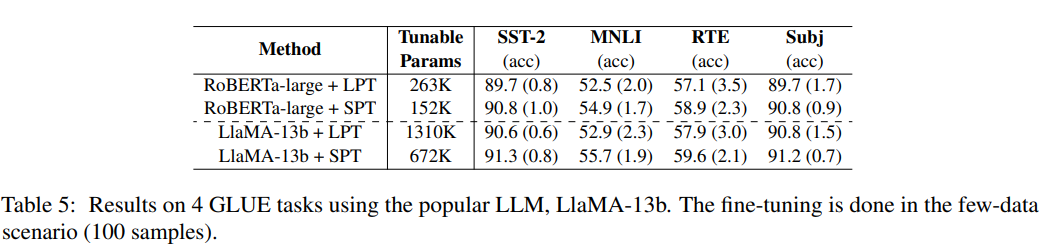
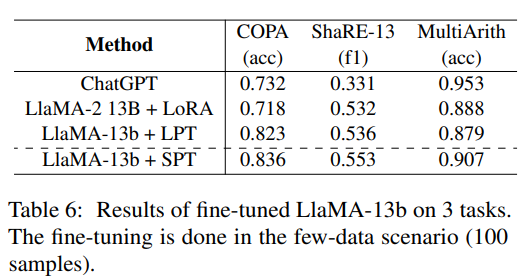
这篇文章工作量较大,有一些实验结果并未列出,如读者有兴趣请阅读原文。
总结
主要贡献如下:
提出了SPT框架,该框架自动学习在适当的预训练模型中间层插入实例感知提示。
提出了包含两种新技术的SPT-DARTS来改进提示超网络的优化过程。
在10个基准文本分类任务和3个不同预训练模型框架的全数据和小样本场景中验证了SPT框架的有效性。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


