
- 1【优选算法系列】【专题一双指针】第二节.202. 快乐数和11. 盛最多水的容器
- 2iframe嵌入本地视频或者http链接视频禁止自动播放_iframe 视频
- 3Git-常用功能_apply changes and mark resolved
- 4在银河麒麟系统上适配openGauss的具体实践_银河麒麟安装opengauss
- 5【深度学习】yolov5目标检测学习与调试
- 6【数组】【自定义排序】Leetcode 56. 合并区间
- 7FANUC机器人启动方式RSR和PNS的比较_rsr和pns的区别
- 8ES的嵌套文档的使用_es嵌套文档
- 9为什么要使用HTTP代理?(静态独享IP)
- 10android 手机远程助手,安卓远程桌面软件
通过搜索 API 增强 LLM 比较 4 种搜索 API,为 LLM 提供最新数据访问的 AI 代理_tavily search
赞
踩

人工智能开发领域不断进步,将可靠的搜索 API 与您的语言学习模型(LLM)结合使用,可以通过提供最新和相关的数据,显著增强您的 AI 代理的性能。
然而,在众多选择中,选择最合适的一个可能会有挑战。本文旨在通过使用 GPT-4 评估四种知名且新颖的搜索 API,协助您在决策过程中做出选择。
我们将迅速介绍各种服务,评估它们在信息详细程度、相关性、及时性、整体答案质量以及答案是否正确回答用户或代理的问题方面的效率。这种比较将帮助您确定最适合您的 LLM 项目的 API。
搜索 API
以下部分简要介绍我们将在后文评估或相互比较的搜索引擎服务。
You.com
图 1. You.com API 参考截图(作者提供的图片)。
You.com 专注于 LLM 应用场景,通过三个独特的端点提供实时网络数据:
- Web LLM:将 Web 搜索与 LLM 结合,以获得精细的响应
- Web Search:提供比传统搜索引擎(如必应和谷歌)更详细信息的扩展摘要
- News:类似 Web Search,但专注于最新事件
文档简单易懂,配有使用流行的 requests Python 包的代码片段。
当前速率限制为 每秒 20 次,默认调用的执行时间约为 1 秒。Web Search 返回的数据比常规搜索引擎 API 多得多,我建议使用具有大(即 32k)上下文窗口的 LLM。
Tavily Search

图 2. Tavily Search 截图(作者提供的图片)。
Tavily Search API 将复杂搜索简化为单个调用,为 AI 开发人员提供快速准确的结果。它结合了爬取和数据提取,每次请求访问 20 多个来源,以获得准确答案和全面研究。
Tavily 提供详细的文档和用户友好的 API 演示环境供测试。响应时间根据搜索深度和选择的字段而异(1-10 秒),可以选择访问原始搜索内容,尽管可能需要进行广告相关的清理。
我的请求的代码执行时间约为 1 秒。速率限制为 每分钟 20 次,相当严格。
Exa Search
图 3. Exa Search API 参考截图(作者提供的图片)。
Exa Search API(前身为 Metaphor)适用于 LLM 应用场景,使用基于嵌入的搜索来获取网络内容。作为知识 API,它为 LLM 提供了神经和关键字搜索功能,提供相关的网页和智能 RAG 模型突出显示的 HTML 内容,可能消除了对网页爬取的需求。
Exa.AI 展示了对用户体验的承诺,提供了交互式文档和在线演示环境。他们的 Python 包 exa-py 有助于轻松集成,但用户也可以使用经典的 requests Python 包。
执行速度快,约为 1 秒,有调整查询以获得更好结果的选项。然而,该服务有时会返回较旧的内容,这可能需要额外的参数来解决。当前速率限制为 每秒 10 次。
Perplexity AI
图 4. Perplexity AI API 参考截图(作者提供的图片)。
Perplexity AI 提供引用、研究和获取等服务,有助于进行广泛的查询和研究整合。
开发人员可以使用他们的 pplx-api 进行知识访问。提供的文档用户友好且易于理解。Perplexity AI 提供了开源语言模型和名为 Sonar 的在线模型。然而,目前通过 API 提供的在线模型不返回来源或引文,但这一功能计划在未来更新中实现。我的代码执行大约需要 1 秒。在线模型的当前速率限制为 每分钟 20 次,相当严格。
该模型的最新数据通常为 3 天前(我向模型询问了最新数据)。在线来源没有指示更新频率,因此可能会有一些延迟。
比较
方法
为了比较这些 API 及其结果,我将为每个开发一个工具。这个工具将提供给一个基于 GPT-4(gpt-4-0125-preview)的代理。
代理将得到四个关于当前事件或趋势的样本问题。随后,我将部署另一个基于 GPT-4 的链,评估代理提供的答案。
评估将基于以下标准进行:
- 答案中的详细程度(1-5)
- 答案中信息的相关性和及时性,考虑到来源的日期(如果提供)(1-5)
- 答案的整体质量(1-5)
- 答案是否正确回答了用户的问题,这将是一个简单的二元是或否。
最终,将为每个工具或服务计算每个类别的平均分数。这些分数将被可视化,以便轻松解释。
问题
- “2024 年的顶级营销趋势是什么?”
- “2024 年 2 月发生了哪些重要的地缘政治事件?”
- “您能总结一下人工智能研究和突破的最新进展吗?”
- “根据劳工统计局报告,美国最新的失业率是多少?
代码
注意:为了使本文更易读,我没有在下面的代码片段中显示导入语句。但是,您可以在这里找到完整的笔记本。
工具
注意:为了使结果更具可比性,我还将返回结果数量设置为 3。
为了确保我们的代理稍后可以利用每个介绍的服务,我们需要创建或包装每个工具,使用自定义工具装饰器,遵循 LangChain 的指南来定义自定义工具。
# YOU.COM API @tool def you_com_api(query: str) -> str: """使用此工具在互联网上搜索最新信息。""" headers = {"X-API-Key": "XXX"} params = {"query": query, "num_web_results": 3} results = requests.get( f"https://api.ydc-index.io/search", params=params, headers=headers, ).json() return json.dumps(results) # Exa Search API @tool def exa_search_api(query: str) -> str: """使用此工具在互联网上搜索最新信息。""" url = "https://api.exa.ai/search" payload = { "query": query, "contents": {"text": {"includeHtmlTags": False}}, "numResults": 3, } headers = { "accept": "application/json", "content-type": "application/json", "x-api-key": "XXX", } response = requests.post(url, json=payload, headers=headers) return response.text # Tavily Search @tool def tavily_search_api(query: str) -> str: """使用此工具在互联网上搜索最新信息。""" tavily = TavilyClient(api_key="XXX") result = tavily.search( query=query, search_depth="advanced", max_results=3, include_answer=True, include_raw_content=False, ) return json.dumps(result) # Perplexity AI @tool def perplexity_ai_api(query: str) -> str: """使用此工具在互联网上搜索最新信息。""" url = "https://api.perplexity.ai/chat/completions" payload = { "model": "sonar-medium-online", "messages": [ {"role": "system", "content": "Be precise and concise."}, {"role": "user", "content": query}, ], } headers = { "accept": "application/json", "content-type": "application/json", "authorization": "Bearer pplx-XXX", } response = requests.post(url, json=payload, headers=headers) return response.text

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
代理
一旦我们定义了所有工具,我们创建一个方法,其中包含一个基于 gpt-4-0125-preview 运行的 vanilla openai-tools-agent,温度为 0,以确保模型更具确定性。
# 准备代理 # 遵循 https://python.langchain.com/docs/modules/agents/agent_types/openai_tools prompt = hub.pull("hwchase17/openai-tools-agent") def ask_agent(query, tool): # 将工具绑定到代理 llm = ChatOpenAI(openai_api_key="XXX", model="gpt-4-0125-preview", temperature=0) llm_agent = llm.bind_tools([tool]) # 定义包含工具的适当提示 prompt = ChatPromptTemplate.from_messages( [ ( "system", """You are very powerful assistant, but don't know current events. Always try to list the sources your answer is based on. """, ), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ] ) # 组装 llm 和部件以获得代理 agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_tool_messages( x["intermediate_steps"] ), } | prompt | llm_agent | OpenAIToolsAgentOutputParser() ) agent_executor = AgentExecutor(agent=agent, tools=[tool], verbose=True) result = agent_executor.invoke({"input": query}) return result["output"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
评估
最后,我们需要编写评估逻辑。在这种情况下,我们利用一个简单的链条运行 GPT-4。您可以找到关于如何定义评估“逻辑”的说明。在这里重要的一点是提及向 GPT-4 提供关于当前年份的信息的必要性。否则,它可能会将过时的文章或来源(例如,2022年)评定为最新。
def eval_service(query: str, agent_answer: str) -> dict: output_parser = StrOutputParser() instruction = """ 当前年份是2024年。 # 任务: - 评估人工智能的回答是否充分解答了下面提供的用户查询。 # 说明: 1. 仔细阅读用户的查询。 2. 彻底审查人工智能的回应。 3. 根据 1 到 5 的等级评定答案的详细程度。 4. 根据 1 到 5 的等级评定答案中信息的最新程度,考虑到提供的来源的日期。 5. 根据 1 到 5 的等级评定答案的整体质量。 # 评估标准: - **详细程度:** 评估答案如何全面地解答了查询,考虑到所有相关方面。 - **信息最新性:** 评估答案中提供的信息的时效性和相关性,考虑到提供的来源的日期。 - **答案质量:** 评判回应的整体质量,包括准确性、连贯性和相关性。 # 选项: - 选择以下之一: - "YES": 如果人工智能的回应有效地解答了用户的查询,提供相关和准确的信息。 - "NO": 如果人工智能的回应没有充分解答用户的查询或不相关。 # 返回格式: - 以 JSON 格式提供您的答案,包括以下键: - "ANSWER": "YES" 或 "NO" - "DETAIL_RATING": (1-5) - "UP_TO_DATE_RATING": (1-5) - "QUALITY_RATING": (1-5) - "REASONING": 解释您对每个标准的评分。 # 用户查询: {query} # 人工智能回应: {model_answer} """ prompt = PromptTemplate( template=instruction, input_variables=["query", "model_answer"] ) gpt4 = ChatOpenAI(temperature=0, model="gpt-4", openai_api_key="XXX") chain = prompt | gpt4 | output_parser eval = chain.invoke({"query": query, "model_answer": agent_answer}) return json.loads(eval) questions = [ "2024年的主要营销趋势是什么?", "2024年2月发生了哪些重大地缘政治事件?", "能否总结人工智能研究和突破的最新进展?", "根据美国劳工统计局报告,美国最新的失业率是多少?", ] tools = [you_com_api, exa_search_api, tavily_search_api, perplexity_ai_api] ratings = {} for tool in tools: ratings[tool.get_name()] = {} for q in questions: try: tmp_answer = ask_agent(q, tool) if tmp_answer is not None: ratings[tool.get_name()][q] = eval_service(q, tmp_answer) except Exception as e: print(f"处理 {q} 时出现错误,使用 {tool}:{e}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
比较结果
评估结果如图 5 所示。有关 GPT-4 推理的更多细节可以在附录中找到。
总体而言,You.com API 在所有类别中处于领先地位,其次是 Perplexity.ai,而 Exa Search API 则始终排名最后。
You.com API 成功的一个因素可能是单次调用返回的大量数据。这显著帮助代理商制定详细、高质量的答案。然而,高数据量(需要在 GPT-4 模型中使用更大的上下文窗口)可能导致与其他服务相比更高的查询成本。
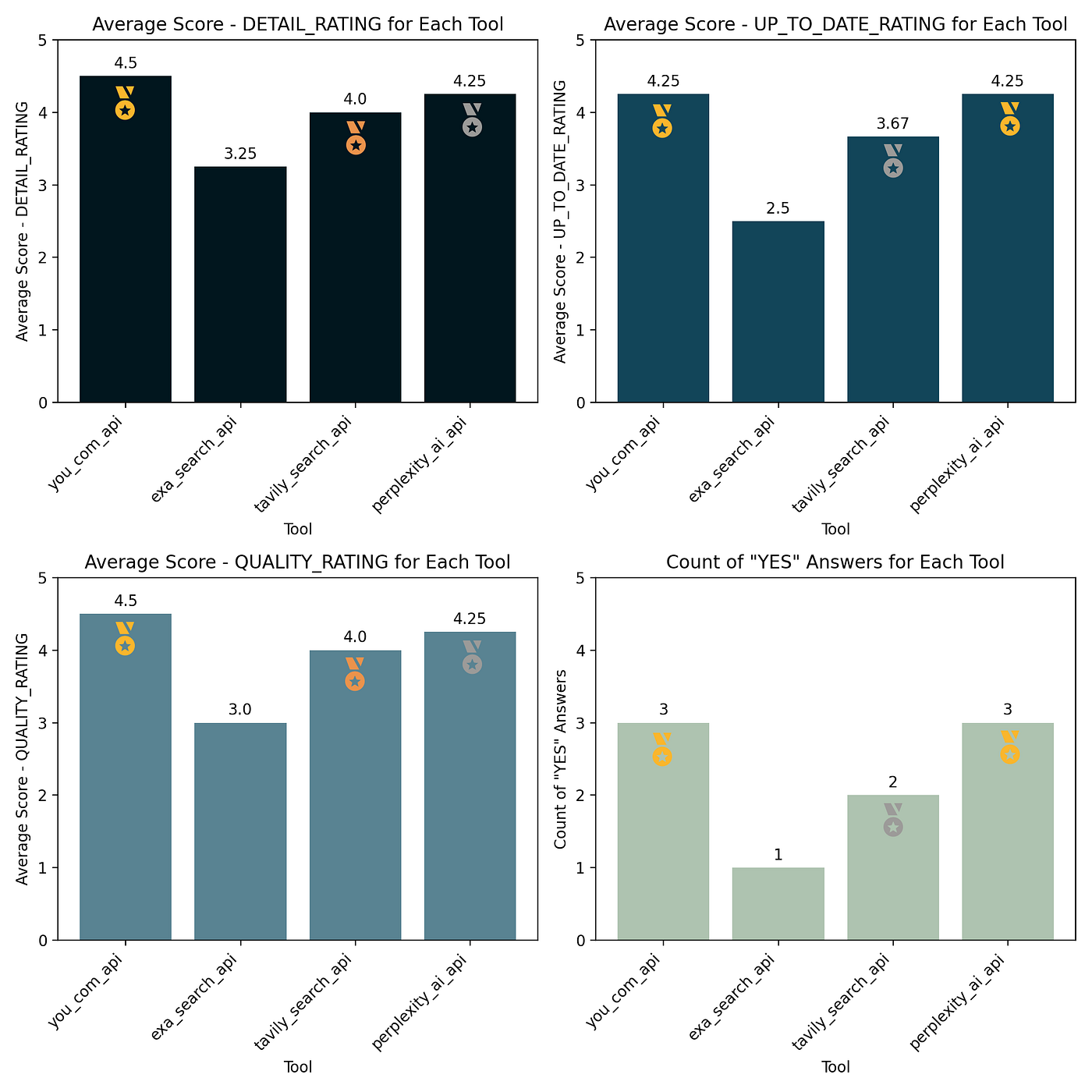
图 5. 评估结果(作者提供的图片)。
Perplexity.AI 在最新评级和肯定回答计数方面与 You.com 类似。它在其他类别上略逊一筹。然而,它的主要缺点是高速率限制和缺乏来源或引用。相比其他服务,Tavily 位于中间位置。
根据这些发现,You.com API 显然是最佳选择。
限制
像每次分析和比较一样,这次比较也有其局限性。它没有包括成本和响应时间的评估。正如所指出的,一些 API(如 You.com 或 Tavily)可能返回大量上下文,可能需要选择一个具有更大上下文窗口的更昂贵模型,或将分析拆分为多个调用。
此外,用于评估的问题数量(4 个)可能不够代表性。更全面的分析可能涉及提出更多问题并进行多次调用。
最后,虽然每个 API 可能都可以使用个别参数进行微调(例如,返回整个原始 HTML 内容),但这次比较旨在评估每个 API 的基本或“原始”版本。
结论
根据我们的比较和评估,You.com API 显然是保持 LLMs 最新数据的最有效工具。尽管由于其大量数据返回可能导致更高的查询成本,但其在所有评估类别中的表现无与伦比。
然而,重要的是要考虑此比较的局限性,包括成本和响应时间等因素,以及所使用的问题数量和性质。未来的分析可能涉及更广泛的问题范围、多次调用以及更详细地评估利用其 API 选项。

