
- 1【大数据毕设】基于Hadoop的音乐推荐系统的设计和实现(六)_大数据音乐推荐系统教程
- 2凌霄飞控添加灵活格式帧数据传输到上位机_凌霄飞控与openmv通信
- 3python flask 如何读取数据库数据并返回到html_flask查询数据库后返回信息
- 4代码随想录算法训练营day40
- 5Mybatis中实现批量更新的几种姿势,总有一款适合你_mybatis批量更新 sql
- 6Scala学习-函数至简原则_scala定义一个求两个数乘积的函数,并调用函数计算两个数的乘积
- 7Android:ADB各类错误_need apk file on command line
- 8[AIGC] 通过Stable Diffusion生成一致人脸的 5 种方法_dreamshaperxl_turbodpmppsde
- 9Airtable 在线数据库介绍
- 10数据结构——顺序表习题解(I)_求含n(n>1)个元素的顺序表l中的最大元素。要求实现顺序表l=(6,5,7,2,9)的最大
深度解读丨火爆全球的AI文生视频大模型Sora_文生视频 diffusion扩散模型
赞
踩
1.Sora概述
Sora是OpenAI于2024年2月发布的“文本到视频”生成式人工智能(AI)模型。
在视觉生成领域,Sora取得了技术上的突破。Sora模型独特之处在于,能够生成长达一分钟的符合用户文本指令的视频,同时保持较高的视觉质量和引人注目的视觉连贯性。与只能生成短视频片段的早期模型不同,Sora创作的一分钟长视频从第一帧到最后一帧都具有渐进感和视觉连贯性。

提示文本:一位时尚女性走在东京的街道上,街道上到处是温暖的霓虹灯和动画城市标志。她身穿黑色皮夹克、红色长裙和黑色靴子,手拿黑色钱包。她戴着太阳镜,涂着红色唇膏。她走起路来自信而随意。街道潮湿而反光,与五颜六色的灯光形成镜面效果。许多行人走来走去。
Sora的另一个特性是其对物理世界模拟的潜力。OpenAI声称通过教AI理解和模拟运动中的物理世界,训练出的Sora模型能根据“文本指令”生成逼真或富有想象力的场景视频,并展现出模拟物理世界的潜力。Sora能够生成包含多个角色、特定运动类型,以及主体和背景等准确细节的复杂场景。该模型不仅能理解用户在提示中提出的要求,还能理解这些事物在物理世界中是如何存在的。

提示文本:两艘海盗船在一杯咖啡中航行时的逼真特写视频。
Sora模型对语言有深刻理解,因此能准确解释提示,并生成能表达生动情感的引人注目的角色。Sora还能在单个生成的视频中创建多个镜头,准确地体现角色和视觉风格。这些进步显示了Sora作为世界模拟器的潜力,它可以提供对所描绘场景的物理和背景动态的细微洞察。

提示文本:几头巨大的长毛猛犸象在雪白的草地上漫步,它们长长的毛发随风轻扬,远处是白雪覆盖的树木和壮观的雪山,午后的光线伴着飘渺的云朵和远处高高挂起的太阳,营造出温暖的光晕,低机位拍摄的景色令人惊叹,捕捉到了大型毛茸茸的哺乳动物,摄影和景深都非常漂亮。
Sora还可以对视频编辑,我们还可以使用Sora在两个输入视频之间逐步插值,在主题和场景构成完全不同的视频之间创建无缝过渡。


在下面的示例中,将以上两个视频进行了视频插接。

作为一款模拟器,Sora目前还存在许多局限性。它可能难以准确模拟复杂场景中的物理现象,也可能无法理解具体的因果关系。如下面的示例中,玻璃碎裂并没有正确体现出来。

注:本章节中所有视频均来自于OpenAI官网
2.Sora技术报告摘要和统计
自从2019年OpenAI设立了“利润上限”部门并接受微软的投资后,OpenAI不再Open。虽然OpenAI产品力领先,但现在其核心模型(例如ChatGPT、GPT-4、Sora)不仅不再开源,论文也不再开放。因此我们只能基于OpenAI公开的技术报告,及一些相关的逆向工程,对Sora背后的相关技术进行探讨。
2.1 Sora技术报告摘要
以下摘自Sora技术报告原文,黑体加粗者特意使用英文原词,这些词汇明确说明了训练的细节和相关的技术。
我们在variable durations, resolutions and aspect ratios(不同时长、不同分辨率和不同长宽比)的视频和图像上联合训练text-conditional diffusion models。我们利用a transformer architecture,对视频和图像latent codes的spacetime patches进行操作。
我们将各种类型的视觉数据转化为a unified representation。
LLM 有文本tokens,而Sora有视觉patches,patches是一种高度可扩展且有效的表示方法。
在上层,我们首先将视频compress到低维latent space 中,然后将其分解为spacetime patches,从而将视频转化为patches。
Sora在此压缩latent space内进行训练并生成视频。我们还训练了一个相应的decoder model模型,将生成的latents映射回像素空间。
我们发现diffusion transformers作为视频模型也能有效scale。
Sora是一个diffusion model;给定输入的噪声patches(以及文本提示等调节信息),经过训练后,它可以预测原始的“干净” patches。
Sora是一个diffusion transformer。Transformers在语言建模、计算机视觉和图像生成等多个领域都表现出显著的scaling特性。
视频模型在经过大规模训练后,会表现出许多有趣的emergent(涌现)能力。
2.2 关键词汇统计
Sora技术报告正文中,Tranformer出现了7次,diffusion出现了6次,patch出现了14次,latent出现了6次,Scale(ing)出现了12次,compress出现了5次,emerge出现了三次。
2.3 引用论文
Sora技术报告一共引用了31篇论文,一篇DALL-E 3的技术报告(DALL-E 3作为OpenAI最新的文生图模型,只放了技术报告)。除去开篇历史介绍引用的三篇recurrent networks,四篇generative adversarial networks,2篇autoregressive transformers,3篇diffusion models相关的,其余20篇如下所示:
13.Attention is all you need.(Transformer开创性论文)
14.Language models are few-shot learners.(GPT-3)
15.An image is worth 16x16 words: Transformers for image recognition at scale.(ViT)
16.Vivit: A video vision transformer.
17.Masked autoencoders are scalable vision learners.
18.Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution.(NaViT)
19.High-resolution image synthesis with latent diffusion models(将diffusion应用于latent space)
20.Auto-encoding variational bayes.(VAE)
21.Deep unsupervised learning using nonequilibrium thermodynamics.( diffusion开创性论文)
22.Denoising diffusion probabilistic models.(DDPM)
23.Improved denoising diffusion probabilistic models.(IDDPM)
24.Diffusion Models Beat GANs on Image Synthesis.
25.Elucidating the design space of diffusion-based generative models.
26.Scalable diffusion models with transformers.
27.Generative pretraining from pixels.
28.Zero-shot text-to-image generation. (DALL·E)
29.Scaling autoregressive models for content-rich text-to-image generation.
30.Improving image generation with better captions.(DALL·E 3技术报告)
31.Hierarchical text-conditional image generation with clip latents.(DALL·E 2)
32.Sdedit: Guided image synthesis and editing with stochastic differential equations. (图像合成编辑)
这20篇论文或者技术报告分布如下,我们将会在下一章节就相关的关键词进行展开解读。
Transformer相关:13-16、26、27
Vision Transformer相关:15、16、27
Autoencodes相关:17、19、20、29、28
Diffusion相关:19、21-26、30-32
Patch相关:15、16、18
CLIP&DALL-E系列:30、31
3.Sora技术报告关键词解读
3.1 Tranformer
Transformer是Google Brain发表的论文《Attention Is All You Need》里提出的一种模型架构,Transformer基于Encoder-Decoder结构并加入了位置编码及Self-Attention机制。Transformer被广泛应用于NLP的各个领域,后续在NLP领域全面开花的语言模型如GPT系列、BERT等,都是基于Transformer。
3.2 Compress&latent space
首先我们介绍Autoencoder(AE)。AE是一个神经网络,以无监督的方式学习Identity Function,如下图所示:
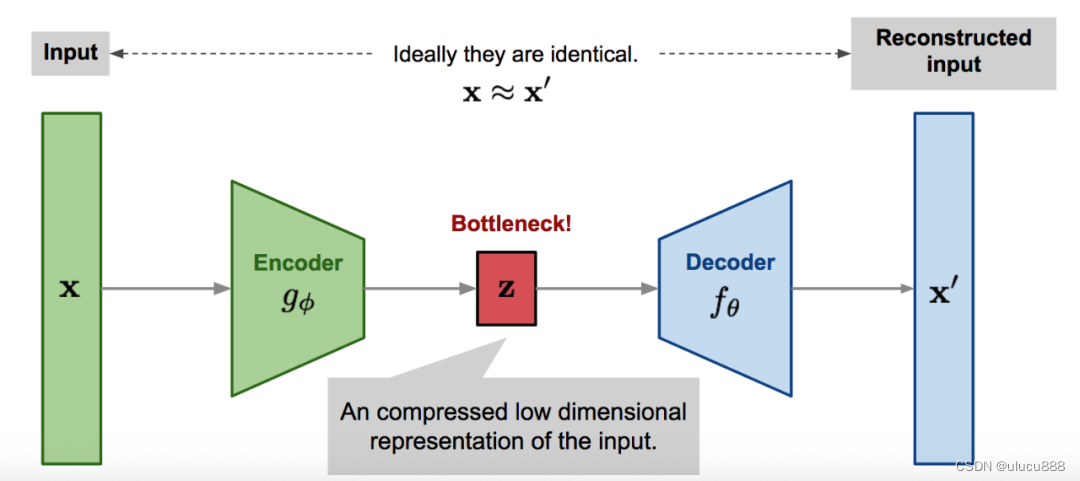
左边的Encoder用来压缩原始的高维输入数据x为低维数据z,右边的Decoder用来将z重构为高维数据x。这一方法起源于20世纪80年代,后来由Hinton和Salakhutdinov(2006 年)的开创性论文加以推广。
Encoder本质上完成了降维,也即图像的压缩(Compress)。上图中的z即是压缩后的数据,也即latent space。
AE的缺点在于,因为z为确定的数值code,在训练过程中,AE的训练目标是输入数据与重构数据之间的差异尽可能变小,这使得模型容易产生过拟合的现象。虽然后续出现了各种变体例如Denoising Autoencoder、Sparse Autoencoder等,但并没有本质上改变这种情况。
接下来我们介绍Variational Autoencoder(VAE)。VAE的主意出自2013年Kingma & Welling的论文《Auto-Encoding Variational Bayes》。VAE和AE的主要区别在于,AE把输入映射为一个固定的向量z,VAE则是将输入映射为一个分布。在实现上,AE的损失函数仅仅为重构误差,而VAE的损失函数中添加了latent space特征分布与标准正态分布的KL散度,通过对latent space的特征分布进行约束,这使得VAE能通过训练样本得到latent space的特征分布,再从该分布中采样得到编码code,即便该编码点未曾出现过在训练集中,也可根据该分布生成类似于其输入样本的新样本,这使得VAE具有较强的生成能力。
OpenAI最早的文生图模型DALL-E,对图像的预处理方式,就是基于VAE的一个拓展dVAE(discrete Variational AutoEncoder)把图片压缩为patches。我们所熟知的Stable Diffusion 中的初始化模型检查点,也是一个预训练 VAE 编码器。
3.3 Vision Transformer(ViT)&Native Resolution ViT(NaViT)
在BERT和GPT成功将Transformer架构应用于NLP之后,研究人员在CV领域也将Transformer架构与视觉组件相结合,使其能够应用于下游CV任务,如Vision Transformer (ViT)和Swin Transformer,从而进一步发展了这一概念。
ViT源自Google Brain的论文《AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》,ViT的结构如下图所示: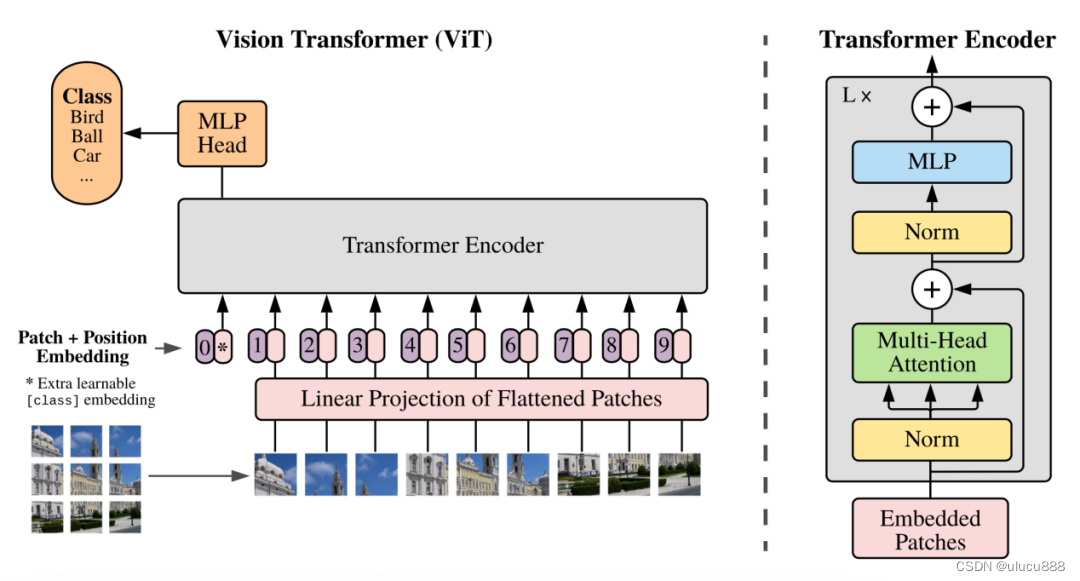
ViT将图像分割成固定大小的块(Patches),对每个Patch进行Linear Projection,再添加Position Embedding,然后将得到的向量序列送给标准Transformer Encoder。
Sora的一个显著特点是能够训练、理解和生成原始尺寸的视频和图像。在原始尺寸的数据上进行训练能显著改善生成视频的构图和框架。通过保持原始的长宽比,Sora可以获得更自然、更连贯的视觉叙事。Sora充分利用机器获取的特征,而非人类设计的特征,可以开发出更有效、更灵活的人工智能系统。

如上图所示,具体来说,Sora 首先通过将视频压缩到低维latent space,然后将representation分解为spacetime patches,从而对视频进行patchifies处理。
Sora的视频压缩网络(或称之为视觉编码器)建立在VAE 或矢量量化-VAE(VQ-VAE)的基础上,旨在降低输入数据(原始视频)的维度,并输出经过时间和空间压缩的latent representation。VAE要将任何大小的视觉数据映射到一个统一的固定大小的latent space是很有挑战性的。此时可以考虑这样两种方式:(1)先将视频帧转化为固定大小的patch,然后再将其编码到latent space中。随后,这些spatial token按时间顺序排列,形成spatial-temporal latent representation。鉴于训练视频的持续时间各不相同,可以对特定的帧数进行采样(对于更短的视频,可能需要填充或时间插值),或者定义一个通用的扩展(超长)输入长度。(2)囊括视频数据的空间和时间维度,提供全面的representation。这种技术不仅分析静态帧,还考虑帧间的移动和变化,从而捕捉视频的动态方面。利用三维卷积是实现这种整合比较直接而有效的方法。
压缩网络部分还有一个关键问题:在将patches投递给diffusion transformer的输入层之前,如何处理latent space 维度的变化(即不同视频类型的latent feature块数或patches数)。
根据Sora的技术报告和相应的参考文献,来自Google Deepmind的论文《Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution》所提出的NaViT应该就是解决方案。NaViT的核心是一种称为PNP(Patch n’ Pack)的方法。如下图所示,PNP将来自不同图像的多个patches打包在一个序列中。OpenAI很可能会使用超长的上下文窗口并打包视频中的所有标记,尽管这样做的计算成本很高。

3.4 扩散(Diffusion)模型& Diffusion Transformers
扩散一词来自于物理非平衡热力学。我们不妨想象一下,一滴墨水滴入盛满水的杯中逐渐扩散到整个水杯的情景。扩散模型(Diffusion Model)是一种基于这种思想的深度学习生成模型。

Diffusion模型提供了一个数学上的合理框架,通过神经网络来学习去噪的过程。传统的扩散模型主要利用包含下采样和上采样块的卷积U-Net作为去噪主干网,通过学习预测和减轻每一步的噪声,最终实现了将噪声转换成图像。Diffusion模型在图像和视频生成领域取得了显著进展。
然而,最近的研究表明,U-Net架构对扩散模型的良好性能并非至关重要。通过采用更灵活的Transformer架构,基于Transformer的扩散模型可以使用更多的训练数据和更大的模型参数。
沿着这一思路,DiTs(Diffusion Transformers)将视觉Transformer用于Latent Diffusion模型的作品。DiT如下图所示:与ViT一样,DiT也采用了Multi-Head Self-Attention层和Pointwise Feedforward网络,并与一些Layer Norm和Scale层交错在一起。
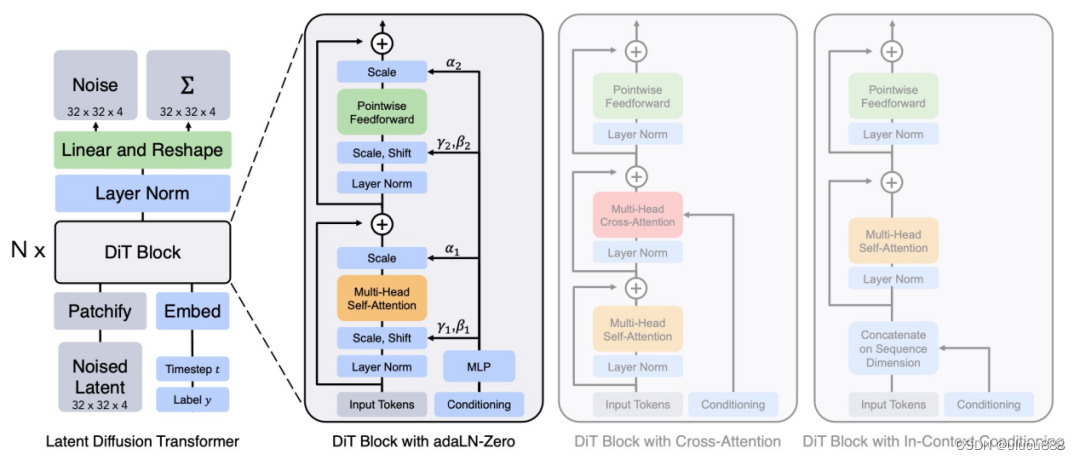 DiT架构
DiT架构
左图:条件Latent DiT模型。输入Latent被分解成多个patch,交由多个DiT块进行处理。
右图:DiT模块的细节。对标准Transformer的变体进行实验,这些变体通过adaptive layer norm、cross-attention和extra input tokens进行调节。adaptive layer norm效果是最好的。
DiT具有良好的可扩展性,可以训练到更高的分辨率和更大的模型容量。在ImageNet分类任务上,DiT取得了最先进的性能。
DiTs来自论文《Scalable Diffusion Models with Transformers》,该论文一作(第一作者)William(Bill) Peebles(https://www.wpeebles.com)当时是UC Berkeley的博士生,在Meta AI的FAIR团队实习。但是现在Bill Peebles已经是OpenAI的研究科学家,共同领导着Sora,在Sora技术报告的作者列表中,Bill Peebles是二作(第二作者),真是后生可畏。
3.5 规模法则(Scaling Laws)
2020年OpenAI发表的论文《Scaling Laws for Neural Language Models》探讨了LLM的规模法则。对于基于Transformer的语言模型,模型性能与模型深度和模型宽度等超参数的依赖性很弱,而与规模的关系最大。规模包括三个因素:模型参数量N(不包括embeddings)、数据集tokens数D和用于训练的计算量C。且大模型相对小模型来说,样本效率(sample-efficient)更高,只需要更少的优化步骤和更少的数据点,就能达到相同的性能级别。因此,适当扩大模型规模(即模型参数量N、数据集tokens数D、计算量C),即可平稳且可预测地提高语言模型的性能。
那么视觉模型的发展是否也遵循类似的规模法则呢?最近,Zhai等人证明,有足够训练数据的ViT模型的性能-计算前沿大致遵循(饱和)幂律(power-law)。在他们之后,Google Research提出了一种高效、稳定地训练22B参数ViT的方法。结果表明,使用frozon模型产生embeddings,然后在其基础上训练少量几层,可以实现很好的性能。Sora作为一个大型视觉模型(LVM),符合规模法则,在“文本到视频”的生成过程中发现了一些新能力。这一重大进步凸显了LVM取得与LLM类似进步的潜力。
3.6 涌现能力(Emergent)
LLM中的涌现能力是指在某些尺度上表现出来的复杂行为或功能(通常与模型参数的大小有关),而这些行为或功能并没有被开发者明确编程或预期。这些能力之所以被称为“涌现”能力,是因为它们是模型在不同数据集上经过全面训练,再加上大量参数计算后产生的。这种组合使模型能够形成联系并得出推论,超越了单纯的模式识别或死记硬背。通常情况下,从较小规模模型的性能推断,无法直接预测这些能力的出现。虽然许多LLM(如Chat- GPT和 GPT-4)都表现出了涌现能力,但在Sora出现之前,表现出类似能力的视觉模型却很少。根据Sora的技术报告,它是第一个展现出经证实的涌现能力的视觉模型,这是计算机视觉领域的一个重要里程碑。
3.7 CLIP& DALL-E系列
自2021年以来,人工智能的首要焦点是能够解释人类指令的生成式语言和视觉模型,即所谓的多模态模型。
CLIP(Contrastive Language-Image Pre-Training)来自于OpenAI的论文《Learning Transferable Visual Models From Natural Language Supervision》,CLIP是一个开创性的“视觉-语言”模型,它将Transformer架构与视觉元素相结合,促进了在大量文本和图像数据集上的训练。如下图所示,CLIP分别对多个“图像和文本对”分别进行Encoder,然后将这些Encode后的文本特征和图片特征进行对比学习,预训练网络的目标,就是最大化正样本对的余弦相似度,并最小化负样本的余弦相似度。

“zero-shot”的过程也很有意思,如上图(2)(3)所示,给定一堆标签,使用句子模板填入分类标签,然后获得多个句子,对这些句子分别进行编码得到多个句子特征。计算这些句子与输入图片的相似度,最高相似度的句子所对应的标签即是预测的分类结果。CLIP在ImageNet上“zero-shot”的性能与原始的ResNet50持平,这也是“zero-shot”在视觉领域取得的一个很好的成绩。
通过从一开始就整合到的视觉和语言知识,CLIP中的文本编码器和图像编码器可以被当作预训练模型在其他多模态生成框架内使用。
DALL-E是OpenAI最早的“文生图”的实现。DALL-E使用了一个预训练好的contrastive model来判断text和image匹配分数,这个模型其实就是CLIP中的模型。
DALL-E 2则是DALL-E的改进版本,主要改进是将CLIP与扩散模型结合起来。
DALL-E 3是OpenAI最新的文本到图像转换工具。作为OpenAI的核心产品,DALL-E 3也是只放出了技术报告。DALL-E 3主要研究了使用高可描述性合成的图像文本描述(caption)进行训练,能大幅提高“文生图”的prompt following(提示跟踪)能力,即生成的图像和输入的prompt的一致性。
4.Sora整体框架
美国Lehigh大学联合微软研究院发表的论文《Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models》对Sora的整体框架进行了逆向工程。如下图所示,Sora的核心本质是一个具有灵活采样维度的diffusion transformer。它由三部分组成:(1)一个time-space compressor首先将原始视频映射到latent空间。(2) 然后,一个ViT处理标记化的latent representation,然后输出denoised latent representation。(3) 一个类似CLIP的调节装置,接收LLM增强的用户指令和潜在的视觉提示,指导diffusion模型生成风格化或主题化的视频。
经过多个denoising(去噪)步骤后,生成视频的latent representation被获取,然后通过相应的解码器映射回像素空间,从而获得生成的视频。


