
- 1java中常见的限流算法详细解析_java中固定窗口算法
- 29.4.k8s的控制器资源(job控制器,cronjob控制器)
- 3git cherry-pick同步commit到多个分支_git cherry-pick多个commit
- 4Vue+springboot+java民宿管理系统_共享民宿 开源 java
- 5dpdk使用intel-82599网卡SRIOV的VF时,需要将VF网卡绑定到vfio_82599ec vf
- 6【大数据开发运维解决方案】超级详细的VMware16安装Redhat8&挂载镜像配置本地yum源&安装unixODBC教程_redhat8.0挂载镜像
- 7python装饰器详解_def fun1(func): func()
- 8人工智能在模拟空战中击落人类飞行员
- 9MacOSX 安装ffmpeg_install_name_tool -change ffmpeg
- 10中文文本关键词抽取的三种方法(TF-IDF、TextRank、word2vec)_word2vec和tfidf的区别
散列表 Hash ,c/c++描述_函数getprime的功能是将
赞
踩
散列 ,英文单词 hash ,意思是把关键字映射变换成杂乱无章的其它值。虽然是映射成了内存地址。但直观上 Hash 后,是把数据杂乱无章的柔和在了一块。所以散列表也叫 hash table。

顺序查找、二分查找和折半查找,都是把待查询的记录的关键字与存储中的记录的关键字进行比较,关键字相同的,即是要找的记录。所以查找时间取决于关键字比较的次数。然而,我们也可以换一种存储技术,即hash 存储,由关键字代入 hash 函数,直接得到其在存储中的存储地址,找到该记录。 用公式表示:
存储位置 = f(关键字)
这个关键字与存储位置之间的对应函数,就叫哈希函数,存储所有记录的连续的存储地址,就叫做哈希表或者散列表。
哈希函数不是固定的,可以多种多样。但一个好的哈希函数应该满足:
(1)哈希函数计算简单、快速,不应超过别的查找方法里关键字比较的时间。
(2)哈希函数值均匀分布。这样可以减少冲突。如果两个不同的关键字,经过哈希函数计算,得到相同的散列地址,这俩关键字,就互为同义词,构成同义词冲突。如果造成冲突的俩关键字非同义词,就叫做堆积,此情况会出现于对一些同义词冲突处理以后,引起的新的堆积。
若要完全不存在哈希冲突,比如采用线性映射,会造成散列表很大,造成存储资源的浪费。所以要求散列函数可以把不同的,各种各样的关键字映射到相对集中的范围,还要求散列地址均匀分布,尽量不构成冲突,如果构成冲突,由哈希冲突函数计算得到合适的存储位置。
所以散列存储技术的关键问题就是:(1)合适的散列函数。(2)冲突的处理。
以下是几个已知常用的散列函数,但不限于此:
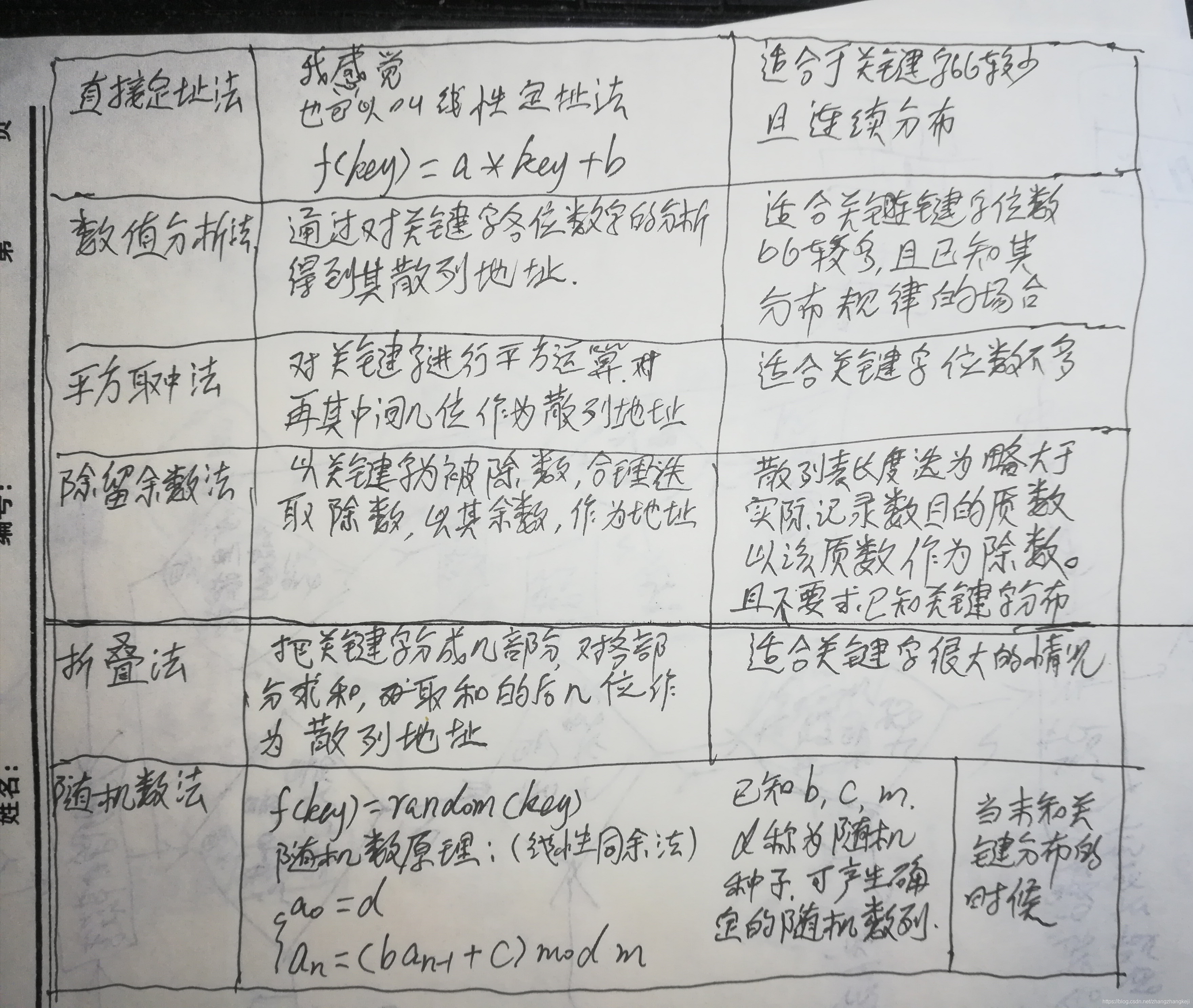
散列函数可以自己设计,也可以调用编程语言提供的散列函数,如 java 的hashCode() 方法。但作为将来的软件专家,我们接过退休的前辈们的职责,作为将来的中流砥柱,还是要多学习一些知识,亲自实践下怎么设计散列查找。
以下是处理散列冲突的方案分类:

影响散列查找的性能的三个方面:
(1)散列函数是否均匀;
(2)处理冲突的方法;
(3)装载因子α

接着介绍两个概念:
查找成功时的查找长度:只有哈希表中已有的元素(或记录),才可以查找得到。每个记录的成功查找长度是其从第一次开始查找进行记录里关键字比对到找到所需记录经过的关键字比较次数。表里所有记录的成功查找长度之和除以总记录数,即为成功查找的平均查找长度。ASLsuccess:average search length
查找不成功时的平均查找长度:表里以外的记录在表里查找肯定是找不到的。一个新记录的插入,要先经过查找,要么找到同样的,则不再插入,要么找到可以插入的空位,查找才结束。所以查找不成功时的查找长度,就是从开始查找到找到第一个可以插入的空位时的关键字比较的次数。
查找不成功的平均查找长度这个参数,只对待插入表的第一个记录有参考意义,它描述了该元素插入表里需要经过的平均比较次数,数值越小,则插入效率越高,哈希表的性能越好。新记录插入后,原表已发生变化。只能对最新的表重新计算查找成功或者不成功的平均查找长度这两个参数。
查找长度的计算,csdn里已有很多这样的文章,讲解的很好。我就不再具体举例了,我也是从ta们的文章里明白这两个概念的。
查找是哈希表操作的基础。插入、建表伴随这查找,删除记录也离不开查找。
删除记录更复杂一些。举例如果先插入记录A,再插入其同义词记录B,那么删除A时,应该把记录B移过来,取消同义词冲突标记,如果删除了B,就只在A位置取消同义词冲突标记。如果待删除的记录的关键字与其存储地址不匹配,说明有堆积产生,删除该元素后应该取消其应插入位置的堆积标志。删除操作依赖于所建立的哈希表结构体变量的成员组成。
struct HashData {
int key; //约定以 关键字 = 0 表示空位,可以插入
char data;
int collisonTimes; // 0冲突,表示该处不存在冲突
};
struct HashTable {
int tableLength;
int prime;
HashData datas[MAX];
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们把哈希表整体作为一个结构体变量,其含有一个记录数组。每个记录里多了一个成员collisonTimes : 对应该位置的冲突次数,0 代表没有冲突,1 代表有 1 次冲突,即有一个同义词,n 代表产生了 n 次冲突,该位置还有 n 个同义词,都被挪走了。
删除操作的程序流程如图:
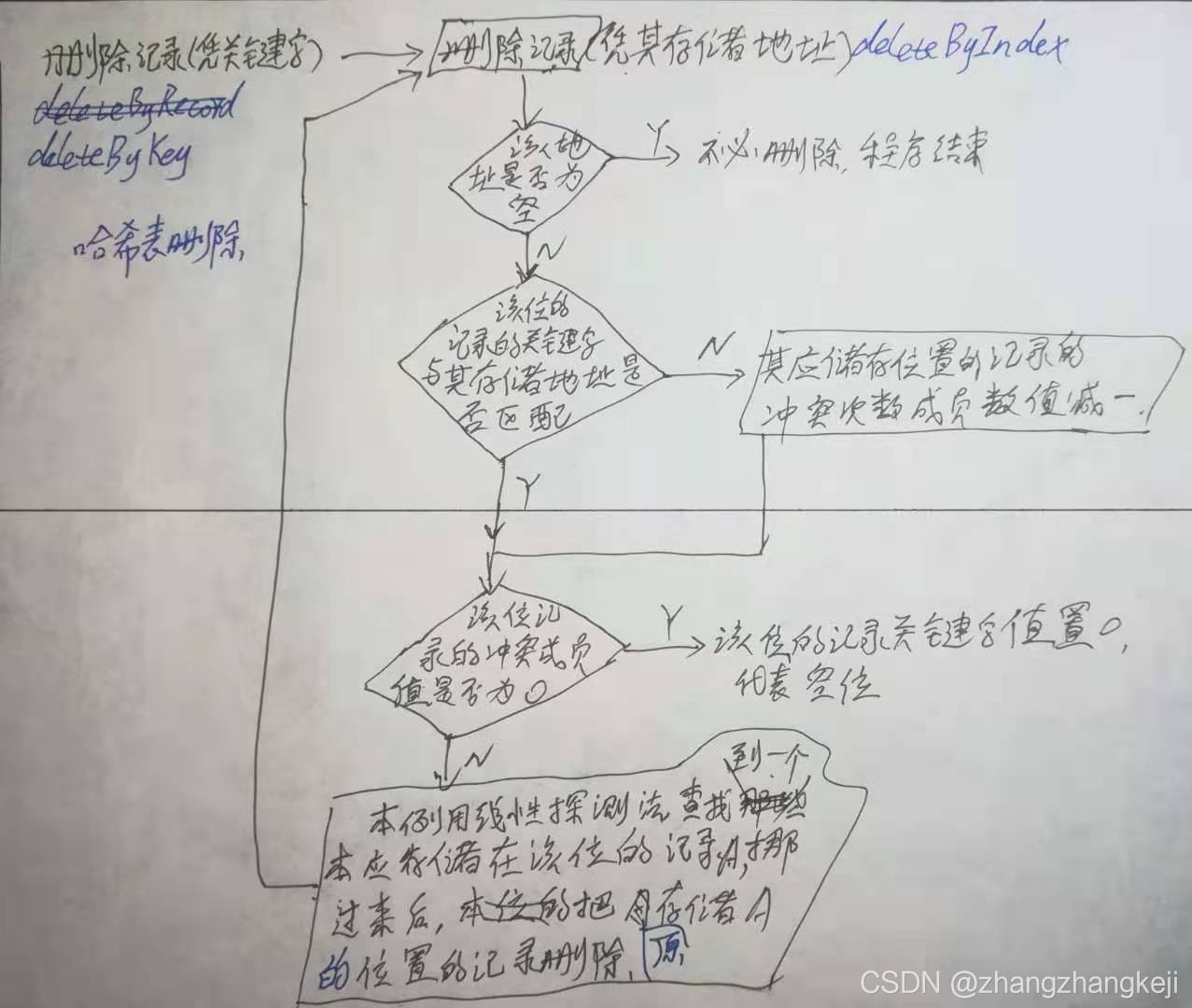
各函数功能如下:
函数initialHashTable : 初始化哈希表,key值全部置为0,表空位。
函数getPrime : 本程序采用除留余数法作为哈希函数,本函数根据记录总数目生成合适的素数。
函数insert:往表里插入记录。本程序采用散列函数除留余数法,处理冲突用开放定址法的线性探测法。
函数search:在表里查找对应关键字的记录位置,若表里没有该关键字,返回其合适的插入位置。
函数deleteByRecord : 根据记录的关键字删除记录,其调用了deleteByIndex。
函数deleteByIndex : 根据记录的存储位置下标,删除记录。
函数dispalyHashTable:显示哈希表的全部内容。
函数ASLSuccess:返回当前哈希表的成功查找的平均查找次数。
函数ASLUnsuccess:返回当前哈希表的不成功查找的平均查找次数。
以下是全部代码,先是main函数所在源文件:
#include<iostream> using namespace std; #define MAX 30 #include<stdio.h> #include<math.h> struct HashData { int key; //约定以 关键字 = 0 表示空位,可以插入 char data; int collisonTimes; // 0冲突,表示该处不存在冲突 }; struct HashTable { int tableLength; int prime; HashData datas[MAX]; }; extern void initialHashTable(HashTable& table); extern int getPrime(int length); extern void insert(HashTable &table,int key,char data); extern void deleteByIndex(HashTable& table, int index); extern void deleteByKey(HashTable &table,int key); extern int search(HashTable &table, int key); extern void dispalyHashTable(HashTable &table); extern float ASLSuccess(HashTable &table); extern float ASLUnsuccess(HashTable &table); int main() { int keyArray[] = { 16,74,60,43,54,90,46,31,29,88,77 }, length = 11; char dataArray[] = {'a','b','c','d','e','f','g','h','i','j','k'}; HashTable table; table.tableLength = length; table.prime = getPrime(table.tableLength); initialHashTable(table); for (int i = 0; i < length; i++) insert(table,keyArray[i],dataArray[i]); dispalyHashTable(table); cout <<endl<< "ASL success : " << ASLSuccess(table)<<endl; cout << "ASL unsuccess : " << ASLUnsuccess(table) << endl; cout << endl << "delete key 77:" << endl; deleteByRecord(table,77); dispalyHashTable(table); cout <<endl<< "ASL success : " << ASLSuccess(table) << endl; cout << "ASL unsuccess : " << ASLUnsuccess(table) << endl; cout << endl << "delete key 16:" << endl; deleteByRecord(table, 16); dispalyHashTable(table); cout << endl << "ASL success : " << ASLSuccess(table) << endl; cout << "ASL unsuccess : " << ASLUnsuccess(table) << endl; cout << endl << "delete key 2:" << endl; deleteByRecord(table, 2); return 0; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
接着是各函数所在源文件代码:
#include<iostream> using namespace std; #define MAX 30 #include<stdio.h> #include<math.h> struct HashData { int key; char data; int collisonTimes; }; struct HashTable { int tableLength; int prime; HashData datas[MAX]; }; int getPrime(int length) { int prime = length; int i = 0, j =0; while ( i <= j) { prime++; j = sqrt(prime); for (i = 2; i <= j && prime % i != 0; i++); } return prime; } void initialHashTable(HashTable& table) { for (int i = 0; i < MAX; i++) { table.datas[i].key = 0; table.datas[i].collisonTimes = 0; table.datas[i].data = '?'; } } int search(HashTable & table, int key) { int address = key % table.prime; while (table.datas[address].key != 0 && table.datas[address].key != key) //处理冲突的线性探测法 address = (address + 1) % table.prime; return address; } void insert(HashTable & table, int key, char data) { int address = search(table ,key); table.datas[address].key = key; table.datas[address].data = data; table.datas[address].collisonTimes = 0; //处理冲突; int i = key % table.prime; if(i != address) table.datas[i].collisonTimes++; } void deleteByIndex(HashTable &table,int index) { if (table.datas[index].key == 0){ //待删关键字不在表中,无需删除 cout << "table does not include this data ." << endl; return; } int prime = table.prime; int i = table.datas[index].key % prime; if (i != index) table.datas[i].collisonTimes--; if (table.datas[index].collisonTimes == 0) { table.datas[index].key = 0; table.datas[index].data = '?'; } else { i = (index + 1) % prime; while (table.datas[i].key % prime != index) i = (i + 1) % prime; table.datas[index].key = table.datas[i].key; table.datas[index].data = table.datas[i].data; deleteByIndex(table, i); } } void deleteByKey(HashTable & table, int key) { //插入a没有冲突 //插入a 后,插入b与a同地址,移动b 到 c , //插入上面a b后,插入 c 与b 同地址,移动 c至 d。要区分删除 a b c 的不同 int address = search(table, key); deleteByIndex(table,address); } void dispalyHashTable(HashTable & table) { printf("%15s:","index"); for(int i = 0 ; i < table.prime ; i++) printf("%4d",i); printf("\n%15s:", "key"); for (int i = 0; i < table.prime; i++) printf("%4d", table.datas[i].key); printf("\n%15s:", "char"); for (int i = 0; i < table.prime; i++) printf("%4c", table.datas[i].data); printf("\n%15s:", "collision times"); for (int i = 0; i < table.prime; i++) printf("%4d", table.datas[i].collisonTimes); } float ASLSuccess(HashTable & table) { //成功查找的查找次数,是找到该记录的比较次数,最少是一次 int i,keyNum = 0, sum = 0 ,prime = table.prime; for(i = 0 ; i < prime ; i++) if (table.datas[i].key != 0) { keyNum++; sum++; if (table.datas[i].key % prime != i) { int j = table.datas[i].key % prime; sum += (i > j ? (i - j) : (i + prime - j)); } } return (sum + 0.0) / keyNum; } float ASLUnsuccess(HashTable & table) { //不成功查找的查找次数,是对表里没有的记录而言的。等于从第一次key值比 //较到找到空位时的总的比较次数。 int sum = 0; for (int i = 0; i < table.prime; i++) if (table.datas[i].key == 0) sum++; else { int j; for (j = 1; table.datas[(i + j) % table.prime].key != 0; j++); sum = sum + j + 1; } return sum * 1.0 / table.prime; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
接着是测试结果和课本标准答案:


谢谢阅读。

