
- 1RabbitMQ【部署 01】一篇学会RabbitMQ服务依赖的下载安装及简单使用(首次登录 User can only log in via localhost 问题处理)(1)
- 2halcon显示坐标_机器视觉之halcon入门(7)-一文弄懂halcon相机标定
- 3《Python编程从入门到实践 第二版》第四章练习_菜单 :想出在南宁学院至少三种你喜欢的食堂菜品,将其名称存储在一个列表中,再
- 4C#中 ArrayList 的使用方法_c#调用arraylist
- 5初相识 | 全方位认识 information_schema
- 6图文详解Redis中常见的缓存问题及解决方案:缓存更新策略,缓存穿透,缓存雪崩,缓存击穿_redis缓存怎么更新
- 7微信小程序|健身房预约课程小程序
- 8ubuntu 11.04使用apt-get安装软件时一直提示E:unable to locate package的解决办法_虚拟机e: unable to locate package sudo
- 9Python异步网络编程利器——详解aiohttp的使用教程_python aiohttp
- 10ChatGPT未来可能应用于iPhone?
深度学习笔记(八)---语义分割的前世今生_传统语义分割
赞
踩
Background
语义分割是一种典型的计算机视觉问题,其涉及将一些原始数据(例如,平面图像)作为输入并将它们转换为具有突出显示的感兴趣区域的掩模。许多人使用术语全像素语义分割(full-pixel semantic segmentation),其中图像中的每个像素根据其所属的感兴趣对象被分配类别ID。 早期的计算机视觉问题只发现边缘(线条和曲线)或渐变等元素,但它们从未完全按照人类感知的方式提供像素级别的图像理解。语义分割将属于同一目标的图像部分聚集在一起来解决这个问题,从而扩展了其应用领域。 注意,与其他基于图像的任务相比,语义分割是完全不同的且先进的。
计算机视觉领域三大问题:
图像分类(image classification)——识别图像中存在的内容;
物体识别和检测(object recognition and detection)——识别图像中存在的内容和位置(通过边界框);
语义分割(semantic segmentation) ——识别图像中存在的内容以及位置(通过查找属于它的所有像素)
概念:
普通分割:将不同分属不同物体的像素区域分开,如前景和后景分割开,狗的区域与猫的区域与背景分割
语义分割:在普通分割的基础上,分类出每一块区域的语义,这区域是什么物体。如把图像中的所有物体都指出他们的各自类别
实例分割:在语义分割的基础上,给每个物体编号
语义:主要是指分割出来的物体的类别,从分结果可以清楚的知道分割出来的是什么物体。
传统方法
传统方法:基于神经网络的分割方法是较为传统的分割方法。基本思想是通过训练多层感知机来得到线性决策函数,然后通过线性决策函数对像素进行分割来达到分割的目的。这种方法需要大量的训练数据。神经网络存在巨量的连接,容易引入空间信息,能较为地解决图像中的噪声和不均问题。选择何种网络结构是这种方法要解决的主要问题。
灰度分割
最简单的语义分段形式涉及分配区域必须满足的硬编码规则或属性,以便为其分配特定标签。规则可以根据像素的属性(例如灰度级强度)来构建。使用此技术的一种方法是拆分(Split)和合并(Merge)算法。该算法递归地将图像分割成子区域,直到可以分配标签,然后通过合并它们将相邻的子区域与相同的标签组合。
这种方法的问题是规则必须硬编码。此外,仅用灰色级别的信息来表示复杂的类(如人)是极其困难的。因此,需要特征提取和优化技术来正确地学习这些复杂类所需的表示。
条件随机场
考虑通过训练模型为每个像素分配类来分割图像。如果我们的模型不完美,我们可能会得到自然界不可能得到的噪声分割结果(如图中所示,狗像素与猫像素混合)。

将带标签dog的像素与带标签cat的像素混合,更真实的分割结果
可以通过考虑像素之间的先验关系来避免这些问题,例如,对象是连续的,因此附近的像素往往具有相同的标签。为了模拟这些关系,我们使用条件随机场(CRF)。
CRF是一种用于结构化预测的统计建模方法。与离散分类器不同,CRF可以在进行预测之前考虑“相邻上下文”,比如像素之间的关系。这使得它成为语义分割的理想候选。本节探讨CRF在语义分割中的应用。
图像中的每个像素都与一组有限的可能状态相关联。在我们的示例中,目标标签是可能的状态集。将一个状态(或标签,u)分配给单个像素(x)的成本称为它的一元成本(unary cost)。为了对像素之间的关系建模,我们还考虑了将一对标签(u,v)分配给一对像素(x,y)的成本,即成对成本(pairwise cost)。我们可以考虑它的近邻像素对(Grid CRF)或者我们可以考虑图像中的所有像素对(Dense CRF)
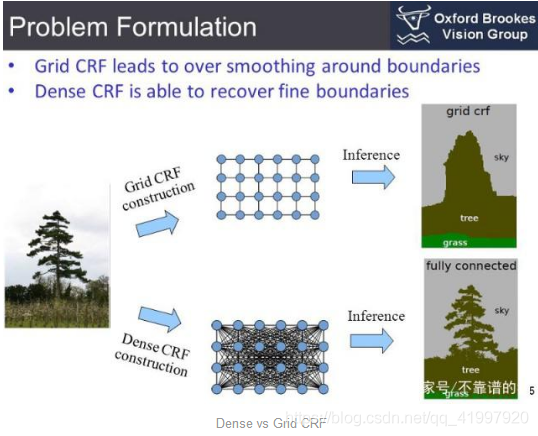
所有像素的一元和成对成本之和被称为CRF的energy (或成本/损失)。可以最小化该值以获得良好的分割输出。
图像分割:图像分割即我们认为的传统的语义分割。是根据灰度,彩色,空间纹理,几何形状等特征把图像划分成若干个互不相交的区域,使得这些特征在同一个区域内的表现出一致性或者相似性,而不同的区域间表现出明显的不同。由于计算机算力的问题,只能处理一些灰度图像,这时期分割主要是通过提取图像的低级特征,然后进行分割,一时涌现了一些方法,如Ostu,FCM,分水岭,N-Cut等。这阶段主要都是非监督学习,分割出的结果并没有语义的标注。
深度学习方法:随着FCN的出现,深度学习正式进入图像语义分割领域。其后的instanc segmentation 方法使得成为真正意义上的语义分割。传统的语义分割方法主要是根据图像的颜色纹理进行划分区域,但语义分割主要是一个语义单元,如将人,车等目标从图像中分割出来。
常用数据集:
参考博客:语义分割的数据集(https://blog.csdn.net/mou_it/article/details/82225505 )
VOC2012 ( http://host.robots.ox.ac.uk/pascal/VOC/voc2012/ )有 20 类目标,这些目标包括人类、机动车类以及其他类,可用于目标类别或背景的分割
MSCOCO ( http://cocodataset.org/ )是一个新的图像识别、分割和图像语义数据集,是一个大规模的图像识别、分割、标注数据集。它可以用于多种竞赛,与本领域最相关的是检测部分,因为其一部分是致力于解决分割问题的。该竞赛包含了超过80个物体类别
Cityscapes ( https://www.cityscapes-dataset.com/dataset-overview/#features )50 个城市的城市场景语义理解数据集
Stanford Background Dataset:至少有一个前景物体的一组户外场景。
Pascal Context:有 400 多类的室内和室外场景
评估和标准:
IOU:用于评估语义分割算法性能的标准指标是平均 IOU(Intersection Over Union,交并比),IoU 定义如下:
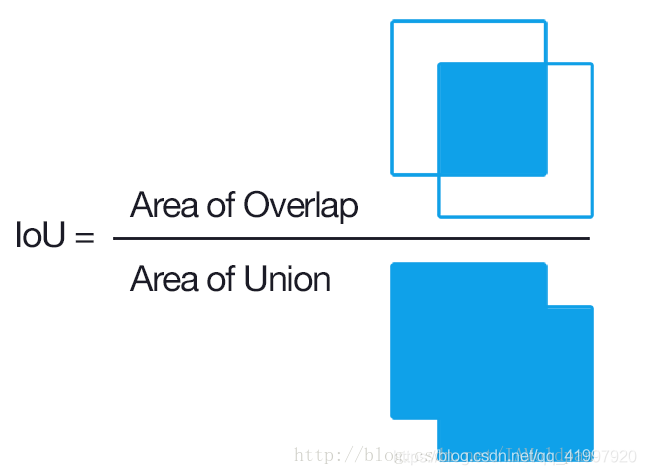
这样的评价指标可以判断目标的捕获程度(使预测标签与标注尽可能重合),也可以判断模型的精确程度(使并集尽可能重合)。
IoU一般都是基于类进行计算的,也有基于图片计算的。一定要看清数据集的评价标准。
基于类进行计算的IoU就是将每一类的IoU计算之后累加,再进行平均,得到的就是基于全局的评价,所以我们求的IoU其实是取了均值的IoU,也就是均交并比(mean IoU)
pixcal-accuracy (PA,像素精度):
基于像素的精度计算是评估指标中最为基本也最为简单的指标,从字面上理解就可以知道,PA是指预测正确的像素占总像素的比例.
经典深度学习方法:
深度学习方法
深度学习极大地简化了执行语义分割的管道,并产生了令人印象深刻的质量结果。在本节中,我们将讨论用于训练这些深度学习方法的流行模型体系结构和损失函数。
1.模型架构
全卷积网络(FCN)是用于语义分割的最简单、最流行的架构之一。在论文FCN for Semantic Segmentation中,作者使用FCN首先通过一系列卷积将输入图像下采样到更小的尺寸(同时获得更多通道)。这组卷积通常称为编码器。然后通过双线性插值或一系列转置卷积对编码输出进行上采样。这组转置卷积通常称为解码器。
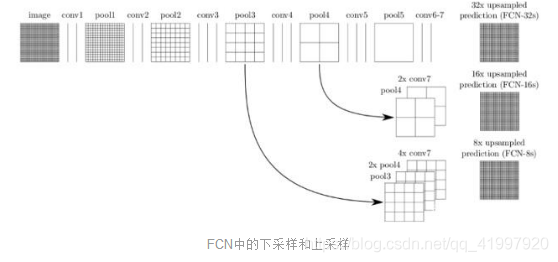
这种基本架构虽然有效,但也有一些缺点。其中一个缺点是由于转置卷积(或反卷积)操作的输出不均匀重叠而出现棋盘伪影(Checkerboard Artifacts)。

另一个缺点是由于编码过程中的信息丢失而在边界处的分辨率较差。
有几种解决方法可以提高基本FCN模型的性能。下面是一些很受欢迎的解决方法
U-Net:U-Net是对简单FCN架构的升级。它具有从卷积块的输出到同一层转置卷积块的相应输入的skip connections。
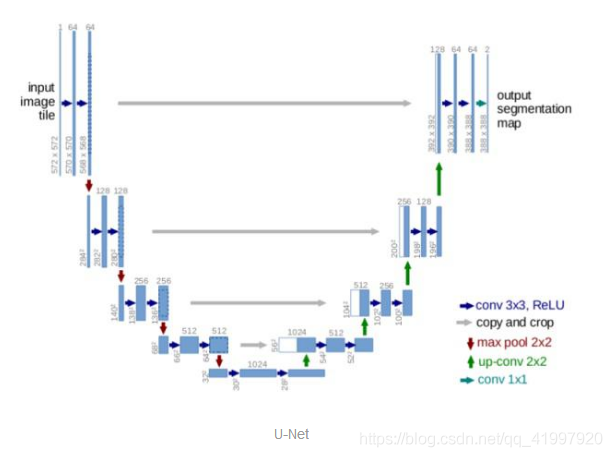
这种skip connections 允许梯度更好地传递,并提供来自图像大小的多个尺度的信息。来自更大范围(上层)的信息可以帮助模型更好地分类。来自更小范围(更深层次)的信息可以帮助模型更好地分段/定位。
Tiramisu模型Tiramisu模型类似U-Net,不同之处是它使用Dense块进行卷积和转置卷积,就像DenseNet论文中所做的那样。Dense块由若干层卷积组成,在这些卷积层中,前面所有层的特征映射都用作后面所有层的输入。由此产生的网络具有极高的参数效率,可以更好地访问较早层的特征。
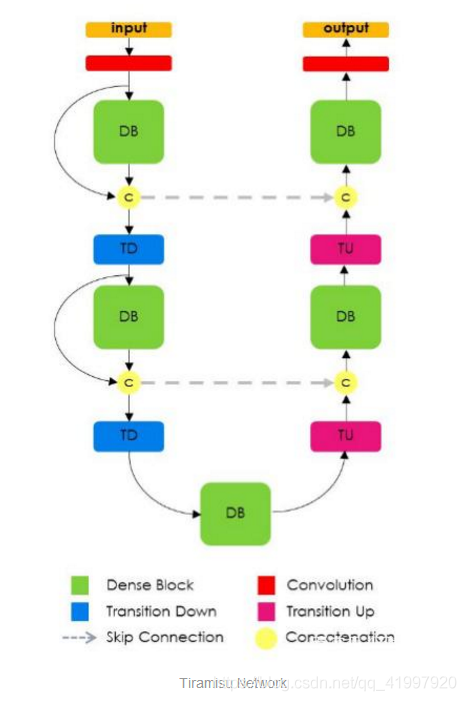
这种方法的缺点是,由于多个机器学习(ML)框架中的连接操作的性质,它的内存效率不是很高(需要运行大型GPU)。
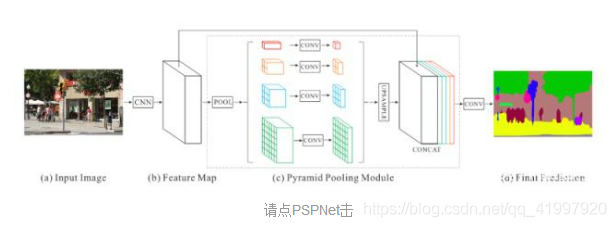
MultiScale方法一些深度学习模型显式地引入了合并来自多个尺度的信息的方法。例如,金字塔场景解析网络(PSPNet)使用四种不同的核大小执行池化操作(max或average),并跨越CNN的输出特征映射,例如ResNet。然后,使用双线性插值来对所有池输出和CNN输出特征映射的大小进行采样,并将所有这些输出特征映射沿着通道轴连接。在该级联输出上执行最终卷积以生成预测。
Atrous(Dilated)卷积提供了一种有效的方法来组合多个尺度的特征而不会大量增加参数的数量。通过调节dilation rate,相同的filter使其权重值在空间中spread得更远。这使它能够学习更多全局背景。
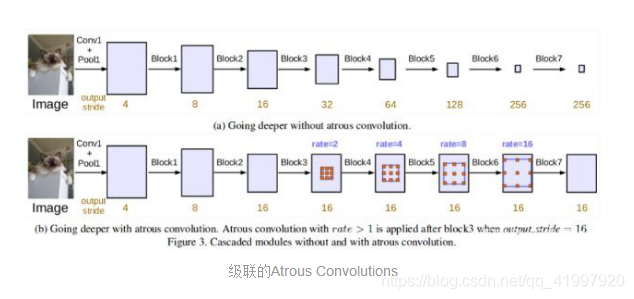
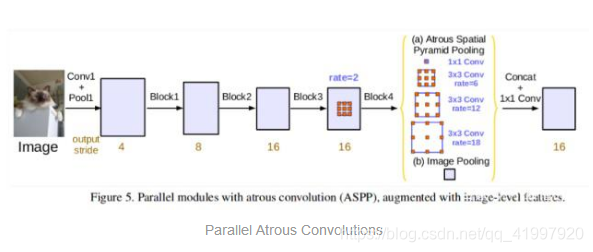
DeepLabv3论文使用不同扩张率的Atrous卷积从多个尺度捕获信息,图像大小没有显著损失。他们尝试以级联方式(如上所示)使用Atrous卷积,并以Atrous Spatial Pyramid Pooling的形式(如下所示)以并行方式使用Atrous卷积。
混合CNN-CRF方法一些方法使用CNN作为特征提取器,然后使用这些特征作为Dense CRF的一元成本(潜在)输入。由于CRF能够模拟像素间关系,因此这种混合CNN-CRF方法提供了良好的结果。
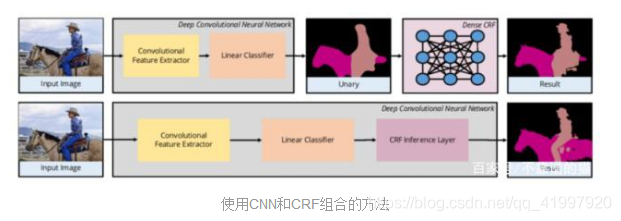
某些方法将CRF纳入神经网络本身,如CRF-as- rnn,其中Dense CRF被建模为循环神经网络。这支持端到端训练,如上图所示。
2.损失函数
与普通分类器不同,必须为语义分段选择不同的损失函数。以下是一些用于语义分割的常用损失函数:
Pixel-wise Softmax with Cross Entropy用于语义分割的标签大小与原始图像相同。标签可采用one-hot编码形式表示,如下图所示:
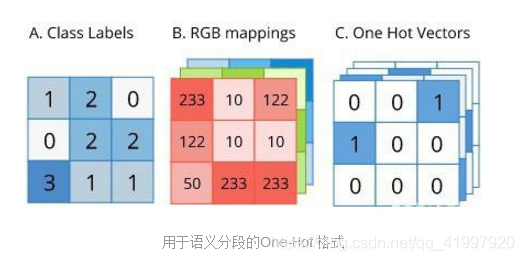
由于标签是一种方便的One-Hot 形式,因此可以直接作为计算交叉熵的ground truth (target)。然而,在应用交叉熵之前,必须在预测输出上逐像素地应用softmax,因为每个像素可以属于我们的任何目标类。
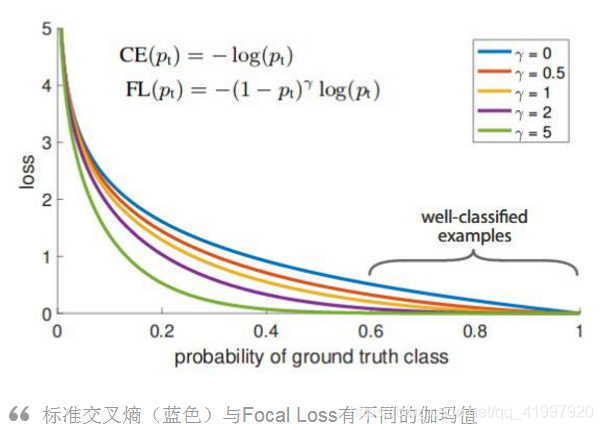
Focal Loss在RetinaNet的论文中引入的Focal Loss,建议在严重类不平衡的情况下,升级到标准交叉熵损失。
考虑如下图所示的标准交叉熵损失方程(蓝色)。即使在我们的模型对像素类(比如80%)非常有信心的情况下,它也有一个有形的损失值(在这里,大约为0.3)。另一方面,当模型对一个类有信心(即80%的置信度损失接近0)时,Focal Loss(紫色,gamma=2)对模型的惩罚并不大。
让我们通过一个直观的例子来探讨为什么这是重要的。假设我们有一个10000像素的图像,只有两个类:背景类(单热形式为0)和目标类(单热形式为1)。让我们假设97%的图像是背景,3%的图像是目标。现在,假设我们的模型80%确定背景像素,但只有30%确定目标类像素。
在使用交叉熵的同时,由于背景像素引起的损失(97% of 10000) * 0.3等于等于2850 并且由于目标像素引起的损失等于(3% of 10000) * 1.2等于360。显然,由于更自信的阶级所造成的损失占主导地位,并且模型学习目标阶层的动机很小。相比之下,由于焦点损失,背景像素引起的损失等于(97% of 10000) * 00.这使得模型能够更好地学习目标类。
Dice LossDice Loss是另一种流行的损失函数,用于具有极端类不平衡的语义分割问题。在V-Net论文中引入Dice Loss用于计算预测类和ground truth类之间的重叠。Dice 系数(D)表示如下:

我们的目标是最大化预测类和ground truth类之间的重叠(即最大化Dice 系数)。因此,我们通常最小化(1-D) 以获得相同的目标,因为大多数机器学习(ML)库仅提供最小化的选项。
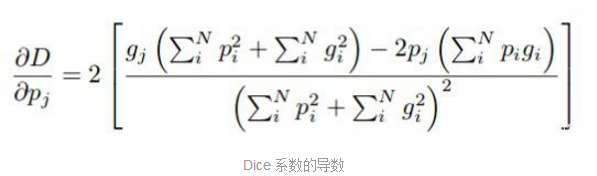
尽管Dice Loss对于具有类不平衡的样本效果很好,但计算其导数的公式(如上所示)在分母中具有平方项。当这些值很小时,我们可能会得到很大的梯度,导致训练不稳定。

