
- 1git如何远程推送到gitlab_初次使用gitlab,本地代码push到远程指定的分支
- 2git:git用户push后无法弹出输入指定gitee的用户及密码的窗口_git push 指定用户
- 3数据结构与算法导论---通讯录的实现_数据结构与算法实训通讯录代码总结
- 4Vscode-Git graph怎么看?
- 5微信小程序开发系列(三十二)·如何通过小程序的API实现页面的上拉加载(onReachBottom事件)和下拉刷新(onPullDownRefresh事件)_微信小程序 onreachbottom
- 6git 克隆出问题remote: Access denied fatal: unable to access ‘<url>‘ The requested URL returned error: 403_git clone remote: [session-e84593b6] access denied
- 7【开发工具篇】git 常用命令合集_git镜像地址
- 8DES算法的介绍和实现_des实现类
- 9Mistral AI 推出最新Mistral Large模型,性能仅次于GPT 4_mistral-large
- 10微信小程序web-view使用说明,及链接打不开问题
保姆级教学——集群环境搭建及创建集群_服务器集群搭建教程
赞
踩
保姆级教学——集群环境搭建及创建集群
新建虚拟机
一些默认,加载镜像开启虚拟机,在安装位置选择自己目录,然后建立分区,首先添加 挂载点,类型标准分区,文件系统ext4
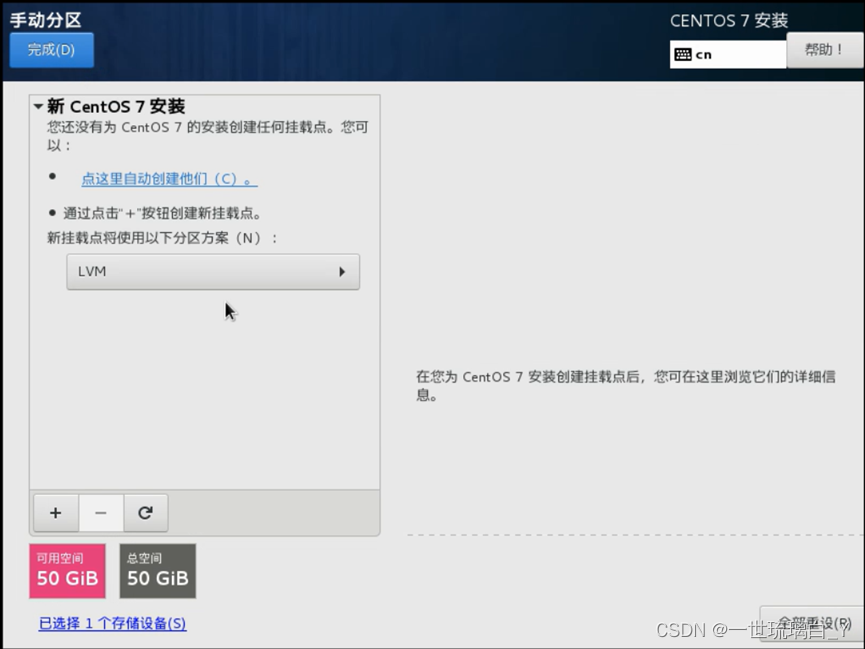
加载分区,期望给2G,
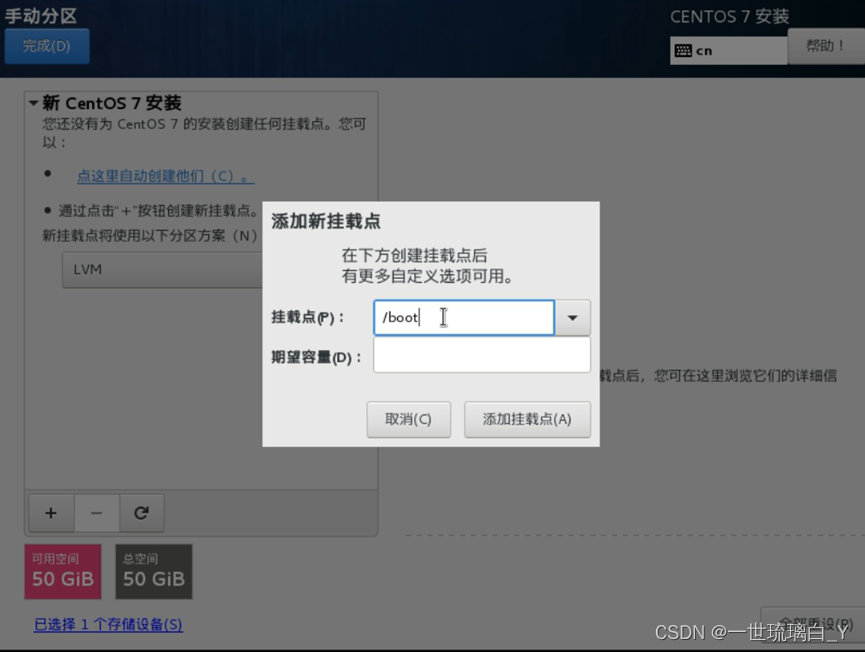
类型标准分区,swap默认
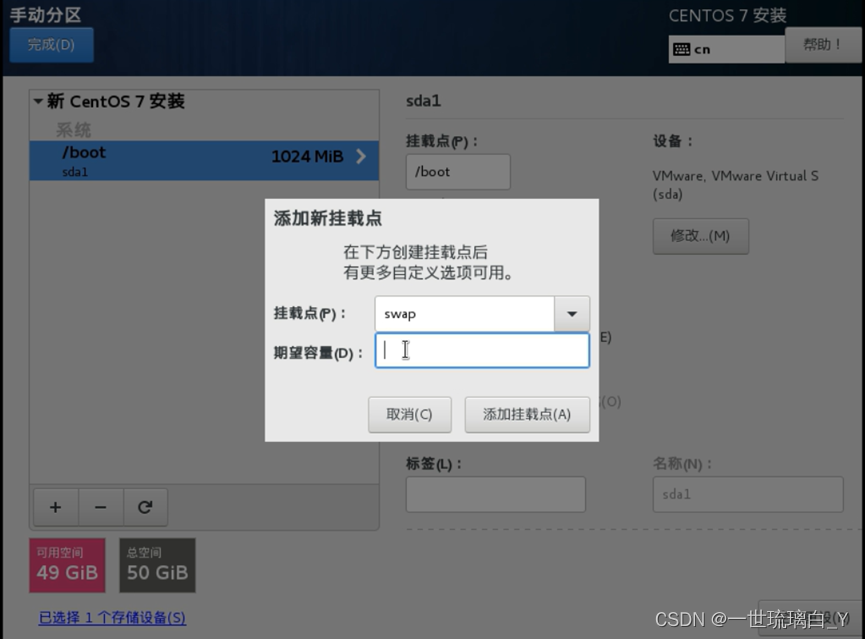
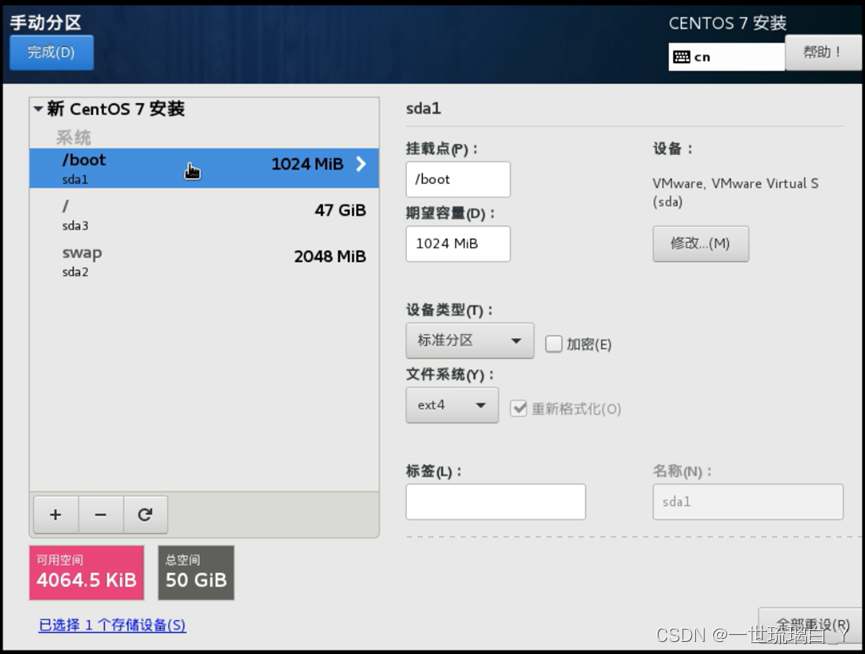
然后剩下47G给/就可以
网络打开,把kudmp对勾去掉
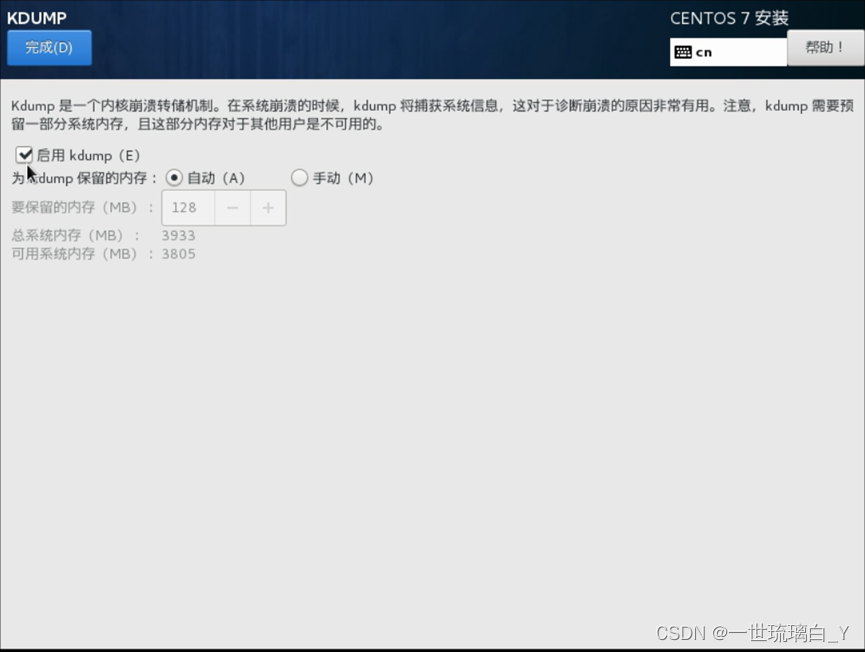
安装完成重新启动
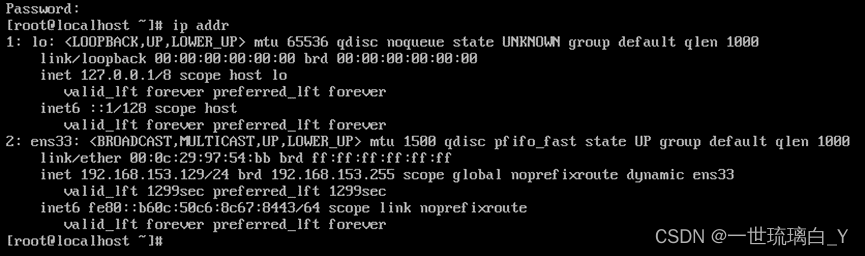
查看自己的ip地址ip addr,我的是192.168.153.129
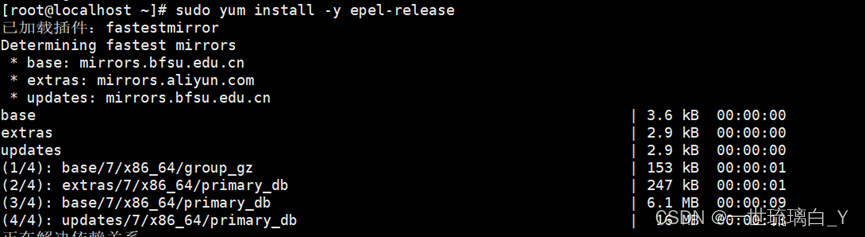
安装必要的环境:sudo yum install -y epel-release
第二个环境:sudo yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git

关闭防火墙(三台)
临时关闭防火墙:sudo systemctl stop firewalld
关闭防火墙自启动:sudo systemctl disable firewalld

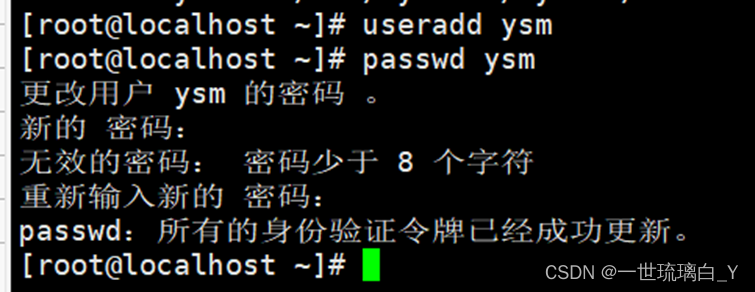
创建用户设置密码
useradd ysm
passwd ysm
配置ysm用户具有root权限(三台)
sudo vim /etc/sudoers
找到如下添加
Allow root to run any commands anywhere
root ALL=(ALL) ALL
ysm ALL=(ALL) NOPASSWD: ALL

Wq!退出,小写wq
在/opt目录下创建子目录(三台)
创建package、software目录
sudo mkdir -p /opt/package
sudo mkdir -p /opt/soft
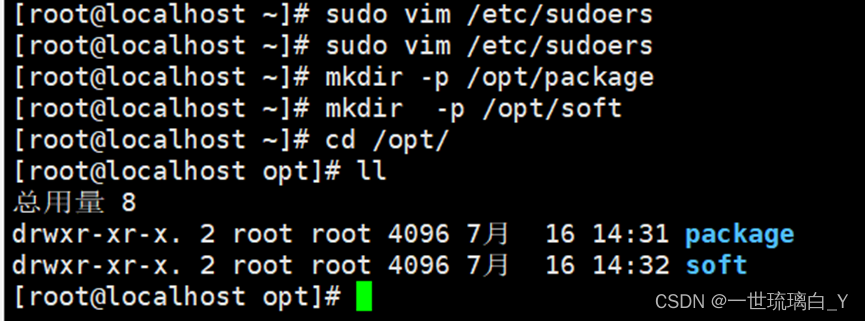
修改package、software文件夹的所有者
sudo chown ysm:ysm /opt/package /opt/soft

修改静态IP(三台)
vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=“192.168.241.100” # 设置的静态IP地址
NETMASK=“255.255.255.0” # 子网掩码
GATEWAY=“192.168.241.2” # 网关地址
DNS1=“192.168.241.2” # DNS服务器
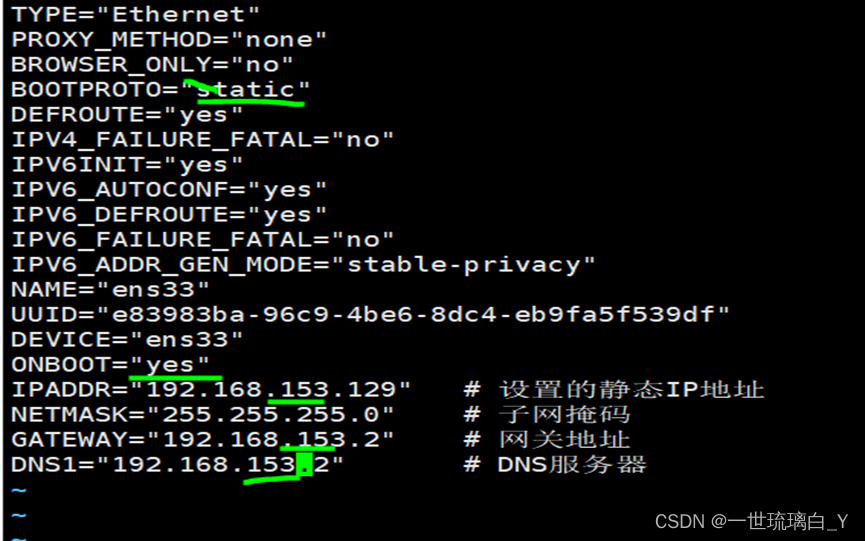
注意:静态static
Yes
添加的要跟自己的一致,我的ip是192.168.153.129,注意改成自己的
修改主机名(三台)
sudo hostnamectl --static set-hostname hadoop1

配置主机名称映射(三台)
vim /etc/hosts
格式:
ip 主机名
如下:
192.168.153.129 hadoop1
192.168.153.130 hadoop2
192.168.153,131 hadoop3

安装JDK(主节点)
删除linux自带的JDK
rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
上传JDK到 /opt/package 目录,利用xftp将jdk上传到/opt/package中
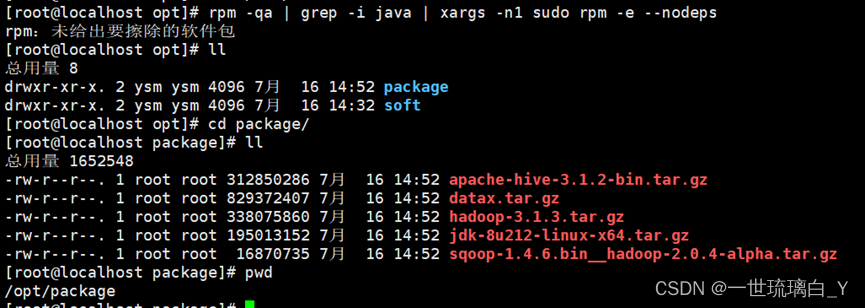
解压到 /opt/soft 目录
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/soft/
配置JDK环境变量**(主节点)
新建/etc/profile.d/my_env.sh文件
sudo vim /etc/profile.d/my_env.sh
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/soft/jdk1.8.0_212
export PATH=
P
A
T
H
:
PATH:
PATH:JAVA_HOME/bin
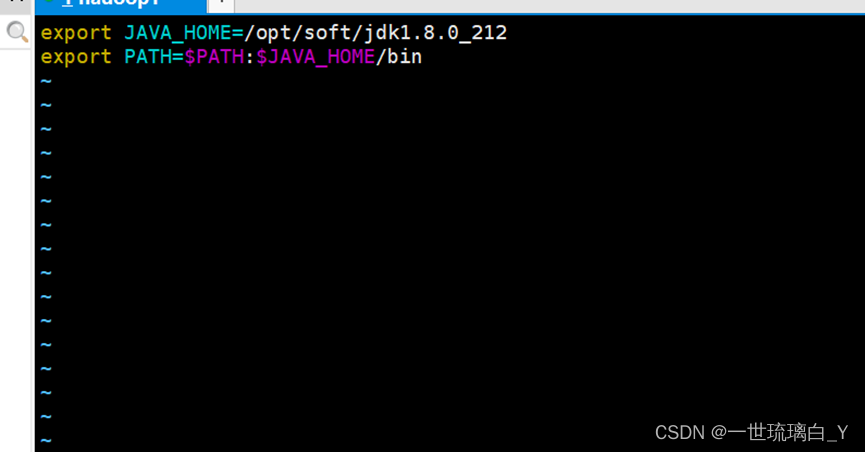
注意: 配置完毕后重启xshell窗口,让环境变量生效!
测试 java -version 出现如下内容,则成功安装配置!

接下来克隆虚拟机,创建hadoop1的完整克隆
克隆完毕后修改克隆后的虚拟机的静态ip,修改主机名、
比如hadoop2,ip地址改为192.168.153.130 hadoop2
主机名设置为hostnamectl --static set-hostname hadoop2
接下来安装hadoop
安装Hadoop(主节点)
将hadoop-3.1.3.tar.gz导入到 /opt/package 目录
切换到 /opt/package
解压hadoop-3.1.3.tar.gz 到soft目录
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/soft

添加hadoop的环境变量
sudo vim /etc/profile.d/my_env.sh
添加内容如下:
#HADOOP_HOME
export HADOOP_HOME=/opt/soft/hadoop-3.1.3
export PATH=
P
A
T
H
:
PATH:
PATH:HADOOP_HOME/bin
export PATH=
P
A
T
H
:
PATH:
PATH:HADOOP_HOME/sbin
断开连接重新连接
检查是否安装成功(出现版本号视为成功)
hadoop version
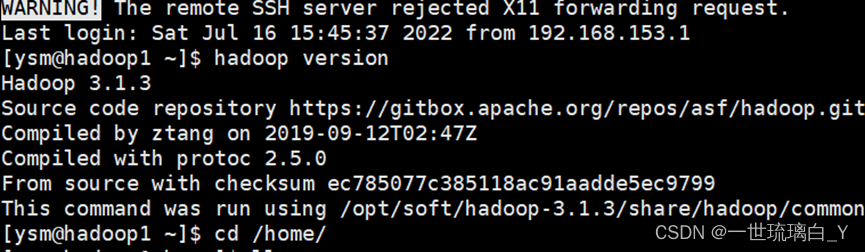
现在只有Hadoop1有hadoop了,23还没有,现在编写 zlcp 集群间数据分发脚本
在 /home/ysm 下创建 zlcp
vim zlcp
复制如下内容
注意: 循环中我使用的主机名是 ( hadoop1 hadoop2 hadoop3 ), 如不一样,自行修改为自己的主机
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo “no parameter!”
exit;
fi
#2. 遍历集群所有机器
for host in hadoop1 hadoop2 hadoop3
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e KaTeX parse error: Expected 'EOF', got '#' at position 23: … then #̲5. 获取父目录 …(cd -P $(dirname KaTeX parse error: Expected 'EOF', got '#' at position 19: …e); pwd) #̲6. 获取当前文件的名称 …(basename $file)
ssh $host “mkdir -p $pdir”
rsync -av
p
d
i
r
/
pdir/
pdir/fname
h
o
s
t
:
host:
host:pdir
else
echo $file does not exists!
fi
done
done
修改脚本 zlcp 具有执行权限chmod +x zlcp
将脚本移动到/bin中,以便全局调用sudo mv zlcp /bin/

SSH免密登录
我们已经掌握如何使用ssh登录远程服务器了,但是每次登录都要输入密码,比较麻烦。ssh提供一种免密登录的方式:公钥登录
- 在客户端hadoop1的家目录下使用 ssh-keygen -t rsa 生成一对密钥:公钥+私钥
注意:这地方要敲三次回车!
在/home/ysm/.ssh 下生成两个文件
id_rsa 私钥
id_rsa.pub 公钥
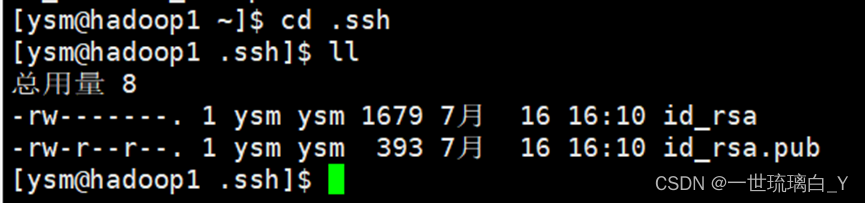
注意: .ssh 是一个隐藏文件,使用 ls -a查看
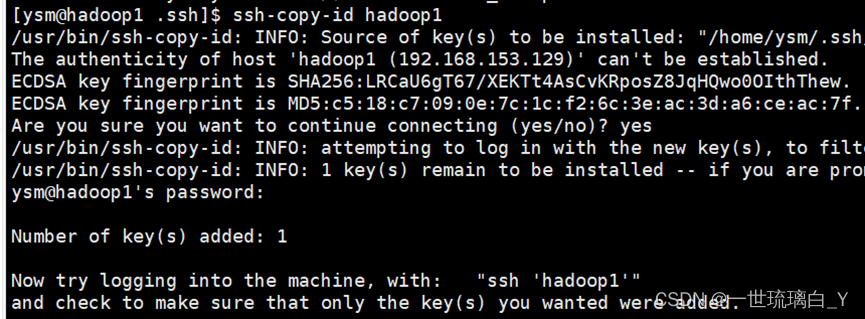
2. 将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
- 如果想三台机器之间互相都可以实现免密登录,可以将 整个 .ssh分发到各个机器
注意:回到家目录下ls-a 查看如果有.ssh再执行
[ysm@hadoop1 ~]$ zlcp .ssh/
zlcp 等下面配置为就可以使用了
.ssh 下功能说明
known_hosts 记录ssh访问过计算机的公钥(public key)
id_rsa 生成的私钥
id_rsa.pub 生成的公钥
authorized_keys 存放授权过的无密登录服务器公钥
接下来配置集群文件
配置 core-site.xml
注意:需要进入下面路径下,别错了
cd /opt/soft/hadoop-3.1.3/etc/hadoop/
执行:vim core-site.xml
添加如下内容在 configuration标签内
注意:以下所有的环境变量配置都在与之间添加
fs.defaultFS hdfs://hadoop1:8020 hadoop.data.dir /opt/soft/hadoop-3.1.3/data hadoop.proxyuser.ysm.hosts * hadoop.proxyuser.ysm.groups * hadoop.http.staticuser.user ysm 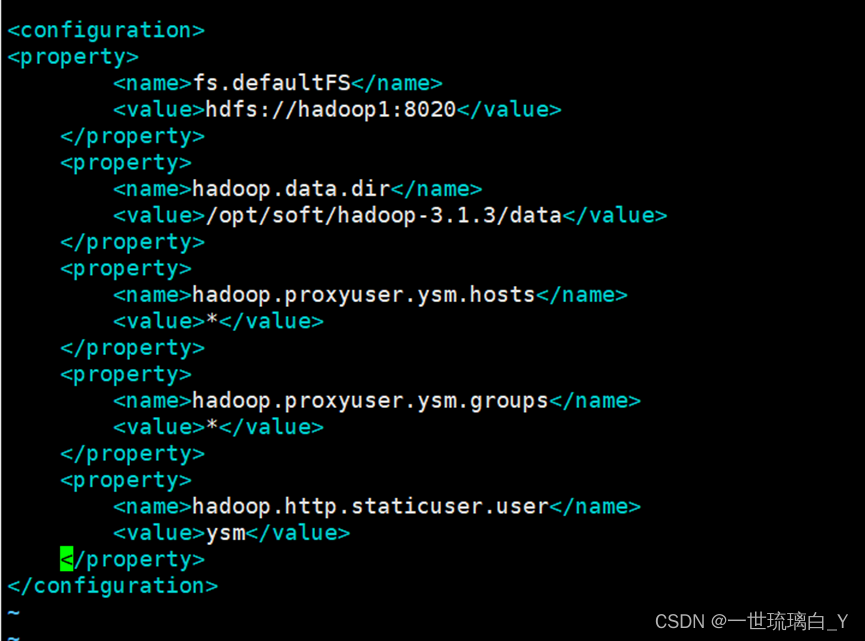配置hdfs-site.xml
vim hdfs-site.xml
添加如下内容
dfs.namenode.name.dir
file://
h
a
d
o
o
p
.
d
a
t
a
.
d
i
r
/
n
a
m
e
<
/
v
a
l
u
e
>
<
/
p
r
o
p
e
r
t
y
>
<
p
r
o
p
e
r
t
y
>
<
n
a
m
e
>
d
f
s
.
d
a
t
a
n
o
d
e
.
n
a
m
e
.
d
i
r
<
/
n
a
m
e
>
<
v
a
l
u
e
>
f
i
l
e
:
/
/
{hadoop.data.dir}/name</value> </property> <property> <name>dfs.datanode.name.dir</name> <value>file://
hadoop.data.dir/name</value></property><property><name>dfs.datanode.name.dir</name><value>file://{hadoop.data.dir}/data
dfs.namenode.checkpoint.dir
file://${hadoop.data.dir}/namesecondary
dfs.client.datanode-restart.timeout
30
dfs.namenode.secondary.http-address
hadoop3:9868
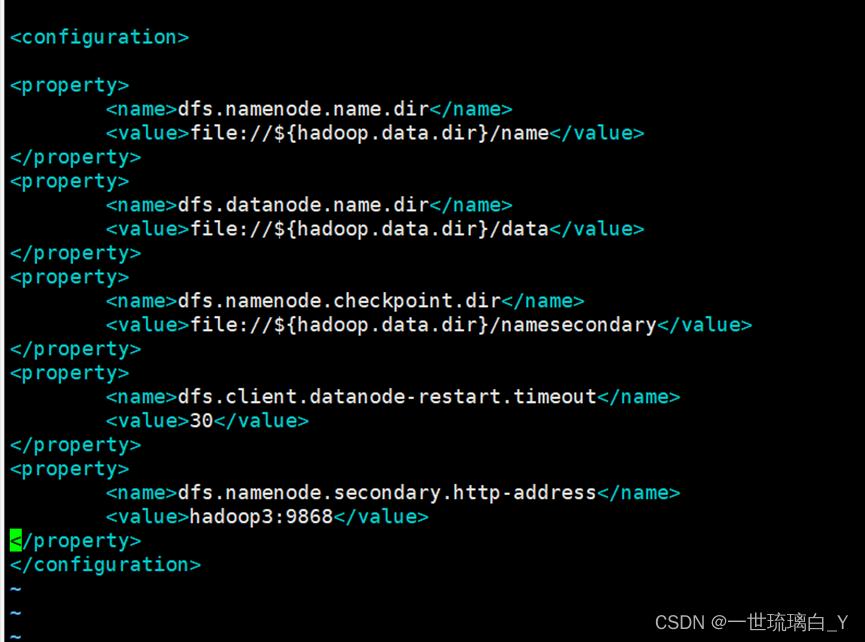
配置yarn-site.xml
vim yarn-site.xml
添加如下内容:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop2
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
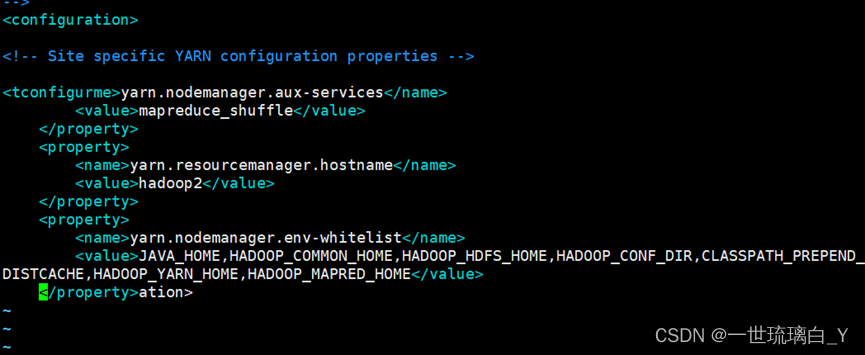
配置mapred-site.xml
vim mapred-site.xml
添加如下:
mapreduce.framework.name
yarn

配置workers
vim workers
删除localhost
添加如下主机名
hadoop1
hadoop2
hadoop3

接下来分发hadoop将安装好hadoop 分发给其他2台机器
在soft目录下执行
zlcp hadoop-3.1.3
接着分发 my_env.sh
注意:需要在 /etc/profile.d/ 下执行
sudo zlcp my_env.sh
分发完毕后: 在三台机器下都测试
hadoop version
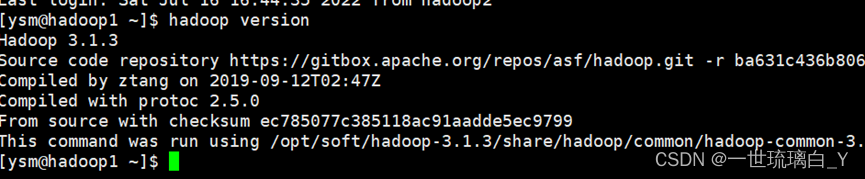
启动集群
如果集群是第一次启动,需要在 hadoop1 节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
执行格式化namenoden代码
注意:一定要在第一台机器上运行,因为我的namemode在第一台机器上
hdfs namenode -format
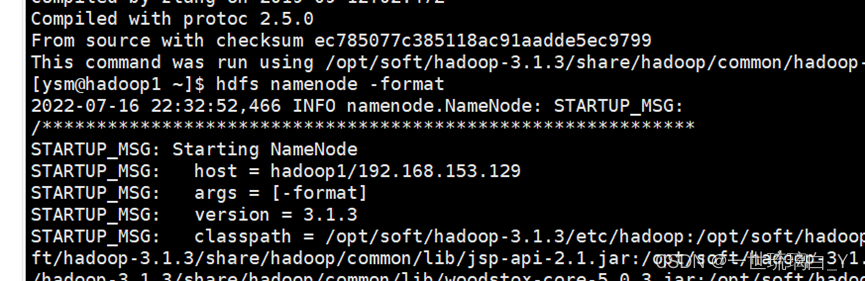
启动HDFS
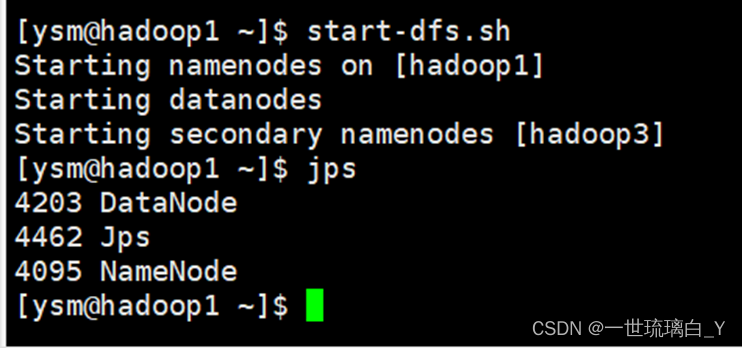
在namenode节点(hadoop1)上执行
start-dfs.sh
验证输入jps如果hadoop1出现这三个说明成功了
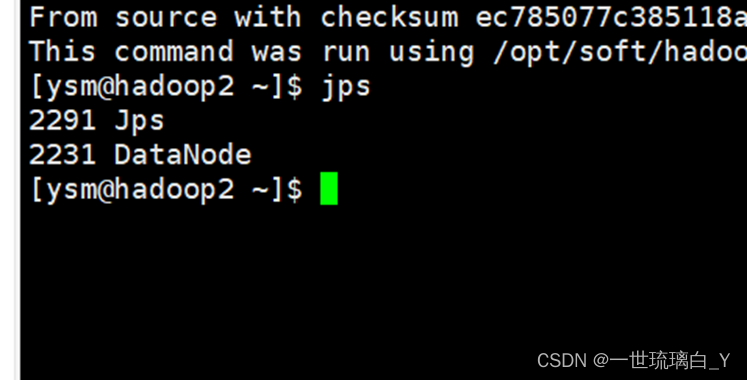
Hadoop2输入jps出现这两个说明成功
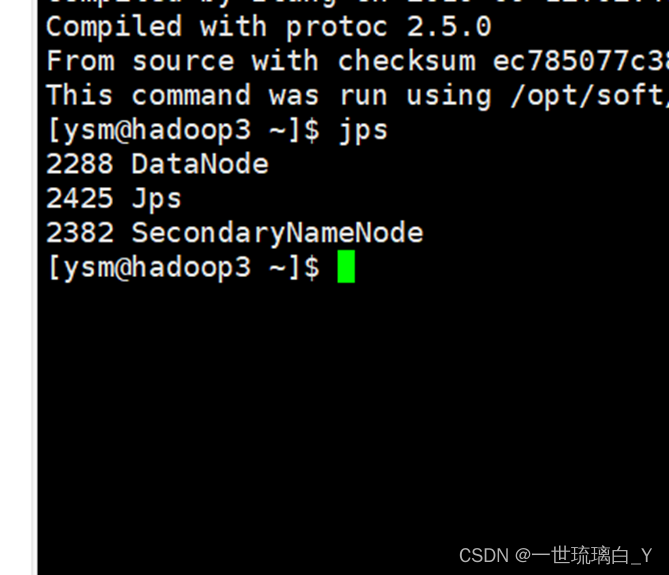
在hadoop3中出现这样说明成功了
启动 yarn
在配置了ResourceManager的节点(hadoop2)
start-yarn.sh

web测试访问namenode
在浏览器地址栏输入 namenode主节点ip:9870
例如
http://192.168.153.129:9870/
接下来配置时间同步
将三太机器都切换到root用户下
在每台机器都执行这两行命令
关闭时间:systemctl stop ntpd
关闭时间自启动:systemctl disable ntpd
1.修改ntp配置文件 (只在Hadoop1做配置)
vim /etc/ntp.conf
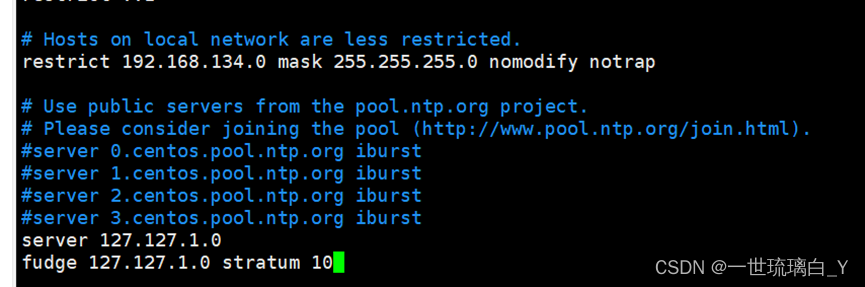
2.添加下面2行
将restrict 192.168.134.0改成自己的ip
下面四行注释掉添加
server 127.127.1.0
fudge 127.127.1.0 stratum 10
3 . 修改/etc/sysconfig/ntpd 文件
vim /etc/sysconfig/ntpd
添加如下内容
SYNC_HWCLOCK=yes
4 . 重新启动ntpd服务,设置开机自启动
systemctl start ntpd
systemctl enable ntpd
5 . 其他台机器配置(Hadoop2 和 Hadoop 3)
在其他机器配置10分钟与时间服务器同步一次
crontab -e
添加
*/10 * * * * /usr/sbin/ntpdate hadoop1

