
- 1通过sql查询mysql数据字典
- 2科普一些免费的ChatGPT_免费chatgpt
- 3如何修改Sourcetree本地仓库路径_sourcetree删除本地仓库
- 42021 RoboCom 世界机器人开发者大赛-高职组(初赛)_7-7 救救倒霉鬼
- 5华为服务器Taishan安装银河麒麟Kylin-Server-V10-SP3操作系统(IBMC安装)_银河麒麟v10 sp3服务器镜像
- 6python 倒序_python np.argsort倒序
- 7Hadoop3:客户端向HDFS写数据流的流程讲解(较枯燥)
- 8turbo码_信息论-Turbo码学习
- 9CTF-文件上传_ctf文件上传 传不上去
- 10SourceTree指令_sourcetree 命令
机器学习之朴素贝叶斯二、情感分析实践_朴素贝叶斯 情感分析
赞
踩
一、什么是朴素贝叶斯?
二、利用朴素贝叶斯进行情感分析
结合之前的公式推导,进行代码编程,以情感分析为例,进行实践操作。
感受:都说算法离不开数学,真的是深有体会,就拿朴素贝叶斯来说,基于贝斯公式思想来进行算法处理,在进行训练和测试的时候,只要明白公式的推导,就能很清晰明白训练和测试过程。
本质上还是计算,根据先验概率、条件概率来求后验概率的操作。
不得不感慨数学真的神奇!!!
1. 数据类别说明

2. 什么是词袋模型
我们这里为了简化工作进行样本数据向量化使用的词袋模型:
词袋模型是一种文本表示方法,将文本看作由单个词语组成的集合(即“袋子”),忽略其语法和顺序,仅保留每个词出现的频率。在词袋模型中,文本可以表示为一个向量,其中每个维度对应一个词,向量的值表示该词在文本中出现的次数或权重。
具体来说,词袋模型包含以下几个步骤:
a. 分词:将文本划分为一个个单独的词语。
b. 构建词表:统计所有文本中出现过的不同的词语,并构建一个词表。
c. 编码:将每个文本表示为一个向量,向量的长度等于词表中词语的数量,每个维度表示一个词语,向量的值表示该词在文本中出现的次数或权重。
d. 应用机器学习算法:使用词袋模型表示的文本向量作为特征输入到机器学习算法中进行训练和预测。
e. 词袋模型的优点是简单有效,能够捕捉词语之间的共现关系,并且适用于各种自然语言处理任务,如文本分类、情感分析、信息检索等。缺点是忽略了词语之间的顺序和上下文关系,无法处理多义词和歧义词,并且不具备解释性。
3. 数据展示
这里使用简单代码进行说明数据的样式,和,数据打标情况

看下打印结果:

可以看到,我们的样本中总共5条样本,打标情况分别为1,1,1,0,0,
4. 利用词袋模型进行词表构建
这一步是我们的重中之重,需要将我们的所有样本进行词表构建。
这词表中,每一个词都是唯一,具备唯一的ID,后面会说到,这种方式的一个重大缺陷:当我们的词表内容不丰富的时候,也就是说在我们进行模型测试的时候,测试语料的情感词在词表中不存在,就会导致,模型捕获不到样本的情感信息。
因此,词表的构建十分重要!!!应尽可能丰富,但是过于庞大,那么在进行计算的时候将是一件十分恐怖的事情。这个问题随后再说。


构造词表后的结果打印:
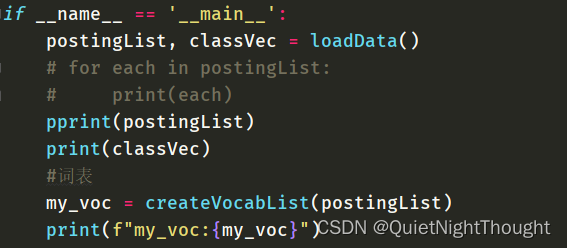
结果如下:

5. 到了这一步,我们的前期工作都已经准备好了,有了样本的向量化数据,开始进行 朴素贝叶斯分类器构造:

首先进行公式操作

接着传入数据进行计算
def train(data,label):
'''
:param data: 这里的数据是样本经过向量化后的向量信息
:param label: 样本所对应的标签信息
:return:
1. vec_0 --- 开心的条件概率组
2. vec_1 --- 伤心的条件概率组
3. simple_1 --- 样本数据属于伤心的概率
'''
num_simple = len(data) #样本的数量
num_words = len(data[0]) #统计每个样本的词的数据量
simple_1 = sum(label)/float(num_simple) #计算的是伤心的
'''
这里说明一下,为什么使用的是sum(label) 来进行计算:
正常这里应该是,属于伤心的样本数据/总的样本数
那么我们这里用sum的效果就是,伤心样本的数量,因为伤心
的label为1,开心为0,所有label的和就是,伤心的数量
这里取巧了。
'''
# 进行条件概率数组初始化
array_0,array_1 = np.zeros(num_words),np.zeros(num_words)
_0 = 0.0
_1 = 0.0 #这里是多求条件概率的分母进行初始化,至于怎么用后面说
#todo 对所有伤心的样本进行计算条件概率
for i in range(num_simple):
if label[i] == 1: #伤心
array_1 += data[i]
_1 += sum(data[i])
else: #开心
array_0 += data[i]
_0 += sum(data[i])
vec_0 = array_0/_0
vec_1 = array_1/_1
'''
在计算样本 x 属于某个类别 C 的后验概率时,朴素贝叶斯假设各个特征之间相互独立,即
p(x|C) = p(x1|C)p(x2|C)...p(xn|C),其中 x1, x2, ..., xn 分别是特征向量的不同维
度。这个假设简化了计算过程,但是忽略了特征之间的相关性。
根据贝叶斯公式,朴素贝叶斯可表示为: p(C|x) = p(x|C)p(C)/p(x) 其中,p(x|C) 表示在类
别 C 下特征向量 x 出现的概率,p(C) 表示类别 C 的先验概率,p(x) 表示特征向量出现的概
率。由于对于所有类别都是相同的,所以可以省略分母 p(x)
可以看到vec_0 = array_0/_0计算的就是p(x|C) = p(x1|C)p(x2|C)...p(xn|C)
也就是当是开心样本的时候,是特征 X 的概率。
array_0,中的每一个维度就是一个特征,那么array_0将所有开行样本中的数据相加,也就计算出了,每个特征发生次数。那么就可以计算,当开心label时候,特征X发生的概率。即 每个特征发生次数/总的样本发生次数
_0 计算的就是,开心样本数据中,总的样本发生次数。
'''
return vec_0,vec_1,simple_1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
来看下打印结果的展示:

可以看到,计算的结果,我都用红色箭头指向了,结果还是明确的。
:return:
1. vec_0 --- 开心的条件概率组
2. vec_1 --- 伤心的条件概率组
3. simple_1 --- 样本数据属于伤心的概率
- 1
- 2
- 3
- 4
这三者就是我们最终训练的产物,用于我们后续的测试:
6. 进行测试使用
#todo 对测试样例进行向量化并且进行使用
def test():
postingList, classVec = loadData()
#词表
my_voc = createVocabList(postingList)
#训练数据
train_data = []
for i in postingList:
train_data.append(wordVec(my_voc,i))
vec_0,vec_1,simple_1 = train(train_data,classVec)
test_01 = ["中奖","了","开心"]
#todo 开始进行测试
test_simple_01 = np.array(wordVec(my_voc,test_01))
res = prod_fun(test_simple_01, vec_0, vec_1, simple_1)
if prod_fun(test_simple_01,vec_0,vec_1,simple_1):
print(f"{test_01}预测标签为:开心{res}")
else:
print(f"{test_01}预测标签为:伤心{res}")
test_02 = ["表白","失败","很","痛苦"]
#todo 开始进行测试
test_simple_02 = np.array(wordVec(my_voc,test_02))
res = prod_fun(test_simple_02, vec_0, vec_1, simple_1)
if prod_fun(test_simple_02,vec_0,vec_1,simple_1):
print(f"{test_02}预测标签为:开心{res}")
else:
print(f"{test_02}预测标签为:伤心{res}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
最后的打印结果:
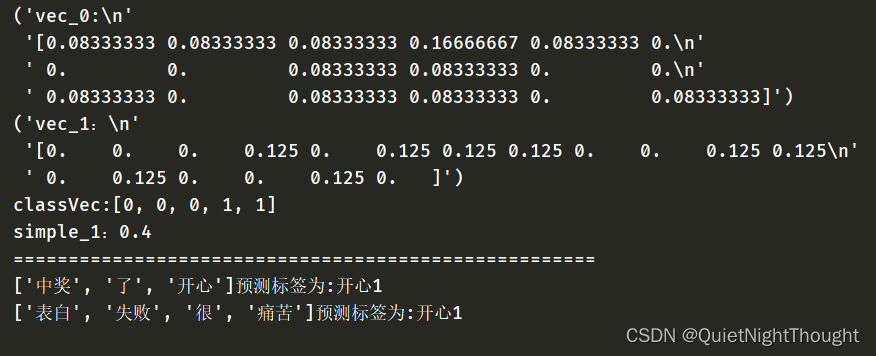
最后我们看到,在进行分类的时候没有,准确的进行分类,这里还需要进行进一步优化。这里先不讨论,下篇文章我在学习使用。

