- 1【云原生】项目上云最佳实践
- 2智能家居的云海,三翼鸟能飞多高?
- 3大学泵与泵站试题及答案,分享几个实用搜题和学习工具 #媒体#微信
- 4深度评估: Deepeval - AI模型性能的全面评测工具
- 5数学建模 Lecture 1: 评价类模型———层次分析法_正互反矩阵权重
- 62734.力扣每日一题6/27 Java(贪心算法)
- 7pom文件中的3种命名标签<name>、<finalName>、<artfactId>_
- 8Kotlin中常用的设计模式整理_kotlin partial function
- 9uni-popup 弹出层
- 10LeetCode -面试题02.02. 返回到数第k个节点 -简单_leetcode返回第k个节点
聚类分析|k-means聚类方法及其Python实现_python kmeans
赞
踩
0. k-means算法简介
k-means算法由MacQueen在1967年提出。是一种经典的基于划分的聚类方法。
划分方法(Partitioning Method)是基于距离判断样本相似度,通过不断迭代将含有多个样本的数据集划分成若干个簇,使每个样本都属于且只属于一个簇,同时聚类簇的总数小于样本总数目。
该方法需要事先给定聚类数以及初始聚类中心,通过迭代的方式使得样本与各自所属类别的簇中心的距离平方和最小,聚类效果很大程度取决于初始簇中心的选择。
K-means算法接受输入量k,然后将n个数据样本的样本集D划分为k个簇以便使所获得的聚类满足:
(1)同一簇中的数据样本相似度较高,而不同簇中的数据样本相似度较小。
(2)聚类相似度是利用各簇中数据样本的均值所获得一个“簇中心”(引力中心)来进行计算的。
1. k-means算法工作原理
- 数据样本分类
从D中任意选择k个数据样本作为初始簇中心。对于所剩下其它数据样本,则根据它们与这些簇中心的相似度(距离),分别将它们分配给与其最相似的簇中心所代表的簇。 - 簇中心的调整
计算每个所获新簇的簇中心(该簇中所有数据样本的均值) - 不断重复这一过程直到标准测度函数开始收敛为止
一般标准测度函数都采用均方差。
假设待聚类的数据样本集 D D D ,将其划分为 k k k 个簇,簇 C C C的中心为 Z Z Z,定义准则函数 E E E:
E = ∑ i = 1 k ∑ D i s ∈ C i D i s 2 ( Z i , D i s ) E=\sum^{k}_{i=1}\sum_{D_{is}\in C_i} Dis^2(Z_i,D_{is}) E=i=1∑kDis∈Ci∑Dis2(Zi,Dis)
其中
D
i
s
2
(
Z
i
,
D
i
s
)
Dis^2(Z_i,D_{is})
Dis2(Zi,Dis) 为
Z
i
Z_i
Zi与样本
D
i
s
D_{is}
Dis的距离。
一次迭代中产生的最佳样本集合的中心
Z
Z
Z成为下一次迭代的簇中心。
2. k-means算法流程
输入: 聚类个数k以及数据样本集D
输出: 满足方差最小标准的k个聚类
处理流程:
step1: 从
D
D
D中任意选择
k
k
k个数据样本作为初始簇中心;
step2: 根据簇中数据样本的平均值,将每个数据样本重新赋给最类似的簇;
step3: 更新簇的平均值,即计算每个簇中数据样本的平均值;
step4: 循环step2到step3直到每个聚类不再发生变化为止。
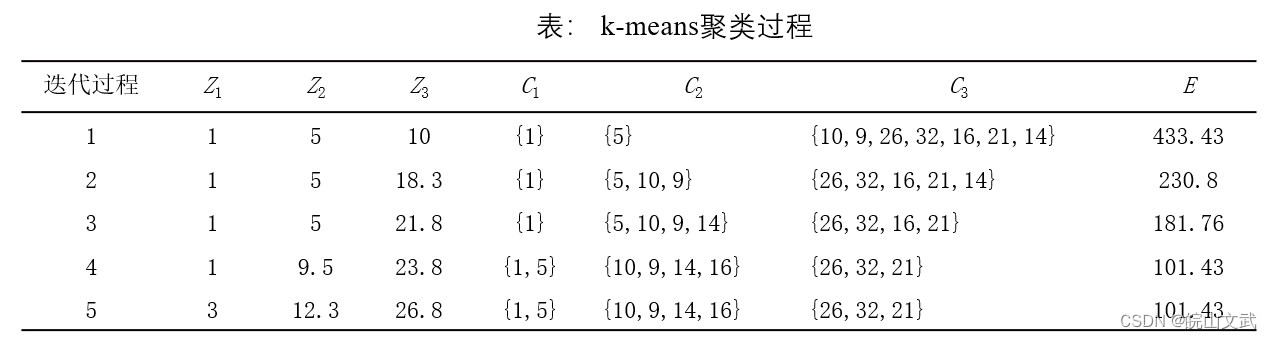
例: 设数据样本集合为D={1,5,10,9,26,32,16,21,14},将D聚为3类,即k=3。
随机选择前三个样本{1},{5},{10}作为初始簇类中心Z1、Z2和Z3,采用欧氏距离计算两个样本之间的距离。
第一次迭代:按照三个聚类中心分为三个簇{1}、{5}和{10,9,26,32,16,21,14}。对于产生的簇分别计算平均值,得到平均样本为1、5和18.3,作为新的簇类中心Z1、Z2和Z3进入第二次迭代。
第二次迭代:通过平均值调整数据样本所在的簇,重新聚类,即将所有数据样本分别计算出与Z1、Z2和Z3的距离,按最近的原则重新分配,得到三个新的簇:{1}、{5,10,9}和{26,32,16,21,14}。重新计算每个簇的平均值作为新的簇类中心。
依次类推,第五次迭代时,得到的三个簇与第四次迭代的结果相同,而且准则函数E收敛,迭代结束。
3. k–means算法的Python实现
KMeans函数格式:
KMeans(n_clusters=8, max_iter=300, min_iter=10, init='k-means++')
- 1
参数说明:
(1) n_clusters:要进行的分类的个数,即k的值,默认是8。
(2) max_iter:最大迭代次数,默认300。
(3) min_iter:最小迭代次数,默认10。
(4) init:有三个可选项:
‘k-means++’:使用k-means++算法,默认选项;
‘random’:从初始质心数据中随机选择k个观察值;
形如 (n_clusters, n_features) 并给出初始质心的数组形式的参数。
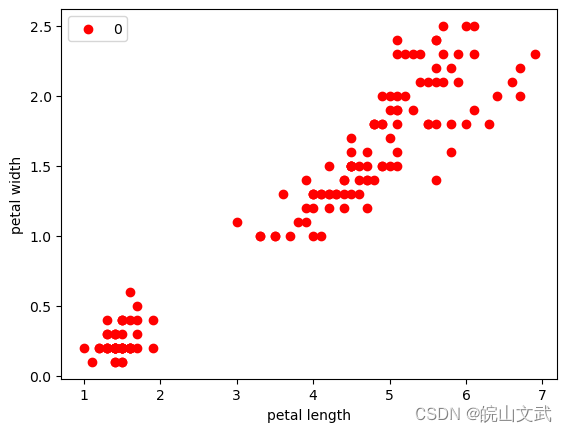
#利用k-means聚类算法实现鸢尾花数据(第3个和第4个维度)的聚类。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:,2:] #只取后两个维度
#绘制数据分布图
plt.scatter(X[:, 0], X[:, 1], c = "red", marker='o', label='0')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show()
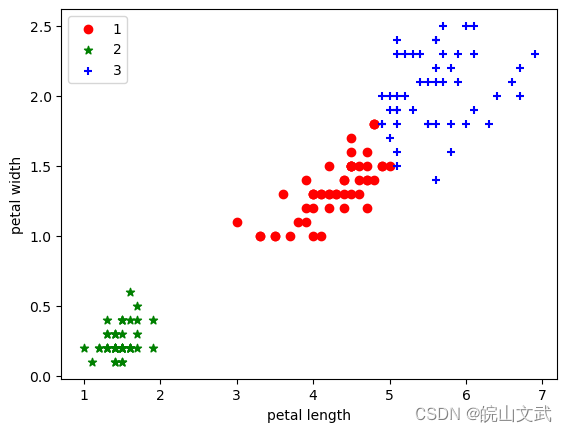
estimator = KMeans(n_clusters=3)#构造聚类器
estimator.fit(X)#聚类
label_pred = estimator.labels_ #获取聚类标签
#绘制k-means结果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c = "red", marker='o', label='1')
plt.scatter(x1[:, 0], x1[:, 1], c = "green", marker='*', label='2')
plt.scatter(x2[:, 0], x2[:, 1], c = "blue", marker='+', label='3')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27