
jupyter notebook 切换编译环境——使用pytorch环境gpu加速,CUDA、pytorch解释_jupyter notebook 怎么运行gpu中的pytorch
赞
踩
jupyter notebook 切换编译环境——使用pytorch环境gpu加速,CUDA、pytorch解释
前言
最近用jupyter notebook 跑一个简单的卷积网络,发现gpu没有用,发现编译环境并不是我的pytorch运行环境,为了用gpu加速运行,需要切换到我之前我建立pytorch环境。在这里记录一下。
1.查看你所创建的python运行环境
conda env list
- 1

如果要新建环境,方式有很多,可以用PyCharm编辑器新建,也可以用命令框 ,输入 conda create -name 环境名字 python=版本号, 回车。
2.激活环境
conda activate pytorch # pytorch是要激活环境的名称
- 1
3.下载ipykernel包
pip install ipykernel
- 1
4.把本地环境导入jupyter notebook
python -m ipykernel install --name pytorch #pytorch 为环境名
- 1
5.切换运行环境
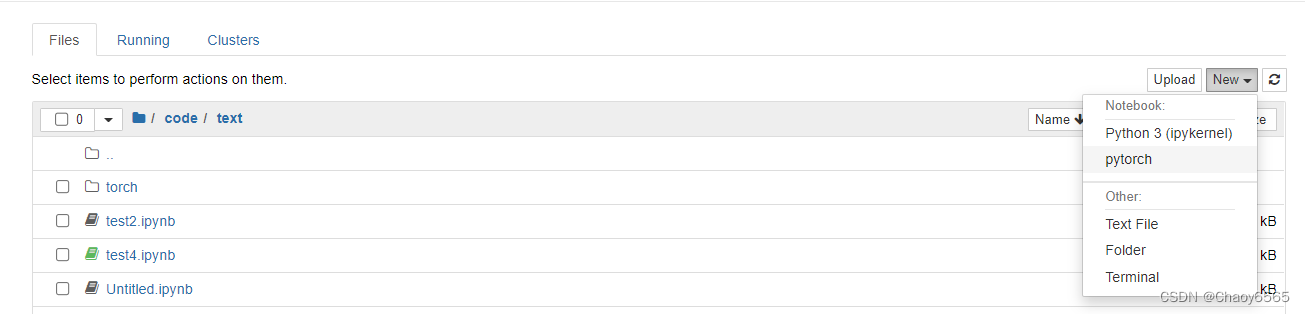
在新建ipynb的时候切换运行环境就好了。
6.CUDA GPU Torch 解释
GPU仅用于图形渲染,此功能是GPU的初衷。后来人们发现,GPU这么一个强大的器件只用于图形处理太浪费了,它应该用来做更多的工作,例如浮点运算。怎么做呢?直接把浮点运算交给GPU是做不到的,因为它只能用于图形处理(那个时候)。最容易想到的,是把浮点运算做一些处理,包装成图形渲染任务,然后交给GPU来做。这就是 GPGPU(General Purpose GPU)的概念。不过这样做有一个缺点,就是你必须有一定的图形学知识,否则你不知道如何包装。于是,为了让不懂图形学知识的人也能体验到GPU运算的强大,Nvidia公司又提出了CUDA的概念。
CUDA(Compute Unified Device Architecture),通用并行计算架构,是一种运算平台。它包含CUDA指令集架构以及GPU内部的并行计算引擎。你只要使用一种类似于C语言的 CUDA C语言,就可以开发CUDA程序,从而可以更加方便的利用GPU强大的计算能力,而不是像以前那样先将计算任务包装成图形渲染任务,再交由GPU处理。
注意,并不是所有GPU都支持CUDA。这一段引用自http://t.csdn.cn/uTvta
PyTorch 是一种开源深度学习框架,以出色的灵活性和易用性著称。这在一定程度上是因为与机器学习开发者和数据科学家所青睐的热门 Python 高级编程语言兼容。PyTorch 采用了 Chainer 创新技术,称为反向模式自动微分。PyTorch 是 Facebook AI Research 和其他几个实验室的开发者的工作成果。该框架将 Torch 中高效而灵活的 GPU 加速后端库与直观的 Python 前端相结合,后者专注于快速原型设计、可读代码,并支持尽可能广泛的深度学习模型。Pytorch 支持开发者使用熟悉的命令式编程方法,但仍可以输出到图形。详细说明可参考http://t.csdn.cn/8aV4w
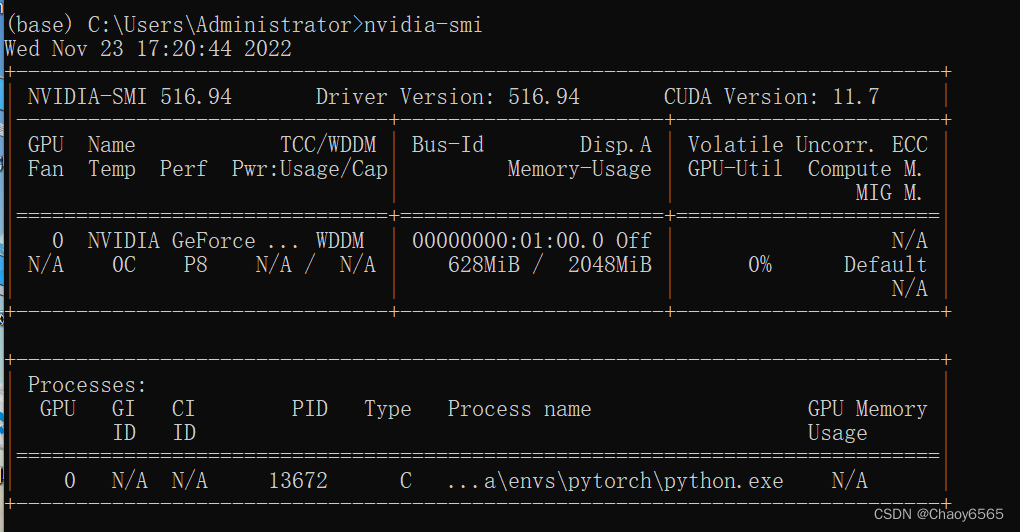
7.查看CUDA版本
nvidia-smi,也可以查看CUDA的版本,GPU使用情况
nvidia-smi
- 1
8.查看cuda是否可用
import torch # 如果pytorch安装成功即可导入
print(torch.cuda.is_available()) # 查看CUDA是否可用
print(torch.cuda.device_count()) # 查看可用的CUDA数量
print(torch.version.cuda) # 查看CUDA的版本号
- 1
- 2
- 3
- 4
输出结果:
True
1
11.3

