
- 1【Ruff学习1】Ruff是一个物联网的操作系统,可以让开发者使用JS高效且迅速地开发物联网应用_ruff js
- 2C#使用RabbitMQ-3_发布订阅模式(扇形交换机)
- 3数据库阿里连接池 druid配置详解_maxopenpreparedstatements
- 4Android开发基础(二)
- 5C/C++学习笔记:变量的作用域和变量的引用_vs的length如何引用
- 6MySQL数据库连接池 :Druid_mysql druid
- 7数据结构与算法-003.双向链表和循环链表_构造void addbefore(t data,node
succ) 怎么调用 - 8面向对象三大特性---继承_面向对象程序设计继承性
- 9微信小程序在线儿童有声读物系统设计与实现
- 10Codeforces Round 919 (Div. 2)C同余的同余
基于深度学习人脸性别识别_性别识别分类模型
赞
踩
要求针对提供的人脸数据集,预测人脸性别。
本次将提供 20000 多张已经分割的人脸图像,要求基于人脸图像自动识别该人性别。数据集的年龄从 1 岁覆盖到 100 多岁,包括了白种人、黄种人、黑种人等多种种族数据。数据集存在人脸姿态、光照、年龄等多种干扰,具有一定的挑战性。
2.2 数据集
数据集包括以下 csv 文件:
train.csv:训练集,其中包括两列,第一列 id 是人脸图像的编号,即对应的文件名,第二列 label 是性别标签,0 表示男性,1 表示女性
test.csv:测试集,只包括一列 id,即测试集中所有的人脸图像的编号。测试集中没有性别标签
train文件夹:所有的训练图像,扩展名名.jpg,其命名与train.csv中的id命名一致
test 文件夹:所有的测试图像,扩展名为jpg,其命名与test.csv中的id命名一致
sampleSubmit.csv:提交文件的样本,其中包括两列,第一列 id 是所有测试集的人脸图像的编号,即对应的文件名,第二列 label 是模型输出的性别标签,0 表示男性,1 表示女性
数据说明:
id:图像文件名,其对应图像为 id.jpg
label:图像标签,0 表示男性,1表示女性
3 运行环境
虚拟环境:Anaconda 4.5.4
Python环境:Python 3.6.5
编译器:vs code
深度学习框架:pytorch1.5.1 , tensorflow2.3.0
其他环境:jupyter, Kaggle notebook
Python库:numpy,pandas,os,PIL,matplotlib
4 算法原理与分析
4.1 损失函数
损失函数是一个非负实数函数,用来量化模型预测与真实标签之间的差异,下面介绍几种常用的损失函数:
4.1.1 平方损失函数(MSE)
平方损失函数较为容易理解,它直接测量机器学习模型的输出与实际结果之间的距离。这里可以定义机器学习模型的输出为y, 实际的结果为y_t,那么平方损失函数可以被定义为:
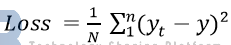
4.1.2 交叉熵损失函数(CrossEntropy)
二分类
在二分的情况下,模型最后需要预测的结果只有两种情况,对于每个类别我们预测得到的概率分别为p和(1-p),此时表达式为:
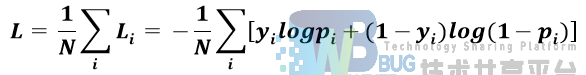
其中:
y_i表示样本i的label,正类为1,负类为0
p_i表示样本i预测为正的概率
多分类
多分类实际上是对二分类的扩展:

其中:
y_i表示第i类的标签
p_i表示第i类的概率
.2 梯度下降
众所周知,在求最优解时常用到两个方法,两者均可用于线性/非线性拟合,梯度下降法通过不断地向梯度反方向迭代可以得到最优解,过程通常分为计算梯度和调整权值直至收敛
4.2.1 随机梯度下降(SGD)
随机梯度下降是指对于一个单样本计算损失,即随机一个样本更新一次梯度。

这样的好处是计算f(x)的梯度和计算f(x+1)的梯度是可以并行计算的,大大提高了运行速度,而且其可以避免冗余数据的影响,但是并不是每次都朝着全局最优迭代,多以通常说地SGD都是mini-batch SGD。
4.2.2 带动量的梯度下降(momentum)
如下图所示,如果进行梯度下降法的一次迭代, 可以看到是慢慢摆动到最小值, 这种上下波动减慢了梯度下降法的速度, 理想的情况是,在纵轴上, 你希望学习慢一点, 因为你不想要这些摆动, 但是在横轴上,你希望加快学习,你希望快速从左向右移,移向最小值,移向红点。

其基本的想法就是计算梯度的指数加权平均数,并利用该梯度更新你的权重。
4.3 卷积神经网络
基础的CNN由卷积(convolution),激活(activation)和池化(pooling)三种结构组成。CNN输出的结果是每幅图像的特定特征空间。当处理图像分类任务时,我们会把CNN输出的特征空间作为全连接层或全连接神经网络(fully connected neural network, FCN)的输入,用全连接层来完成从输入图像到标签集的映射,即分类。当然,整个过程最重要的工作就是如何通过训练数据迭代调整网络权重,也就是后向传播算法。目前主流的卷积神经网络(CNNs),比如VGG, ResNet都是由简单的CNN调整,组合而来。
CNN层级结构
数据输入层/ Input layer
卷积计算层/ CONV layer
ReLU激励层 / ReLU layer
池化层 / Pooling layer
全连接层 / FC layer
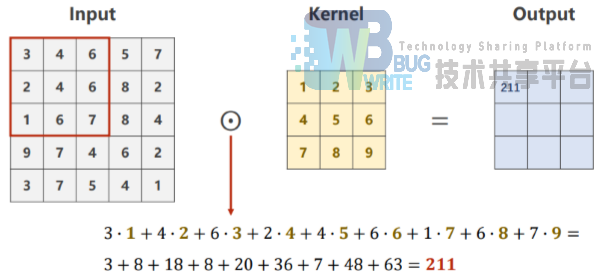
卷积计算过程
4.4 深度学习训练技巧
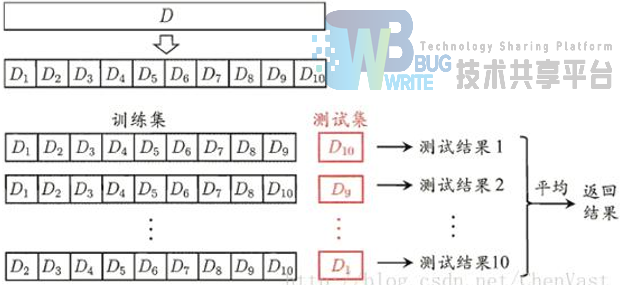
4.4.1 划分验证集和K交叉验证
模型什么时候达到最好,首先看对训练集的拟合程度,也就是通常所说的loss,但是并不是loss越小越好,更重要的是模型在新数据下的表现能力,也就是val_loss。我们通常将训练集划分出一部分作为验证集,来查看模型的泛化能力,但是这也会产生一个弊端,也就是没有充分的运用到训练数据,要知道,很多任务中的训练数据本身也并不多,所以我们这里采用k折交叉验证来最小化这个弊端。
4.4.2 ReduceLROnPlateau配合EarlyStopping
在训练过程中通过手工调整超参数费时费力,ReduceLROnPlateau通过监测验证集上的损失(val_loss)来动态的调整学习率,而且配合EarlyStopping,可以在val_loss多次不再变化后停止训练,更容易获取训练的最佳点。
4.4.3 Dropout
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
4.4.4 Batch normalization
在我们以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是输入数据经过σ ( W X + b ) 这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。如果我们能在网络的中间也进行归一化处理,既可以加快训练速度,又可以避免采用其他正则化手段,还能提高模型精度。
5 实验设计
5.1 数据读入
该任务给出的原始数据是由csv文件和相关的图片文件夹构成,操作起来很不方便,本文通过pandas的读取方法将csv文件里的图片名和标签读取到统一的txt文件中,如下图所示。

通过继承pytorch里提供的DataSet类重写自己的数据集类,然后通过DataLoader打乱并生成batch。

5.2 图像增强
为了丰富图像训练集,更好的提取图像特征,泛化模型(防止模型过拟合),一般都会对数据图像进行数据增强。数据增强,常用的方式,就是旋转图像,剪切图像,改变图像色差,扭曲图像特征,改变图像尺寸大小,增强图像噪音(一般使用高斯噪音,盐椒噪音)等。
归一化和标准化

下边展示一些常用的图像增强方法:
亮度变化

随机灰度化

随机旋转

水平垂直翻转

5.3 模型设计
5.3.1 模型一
模型1结构
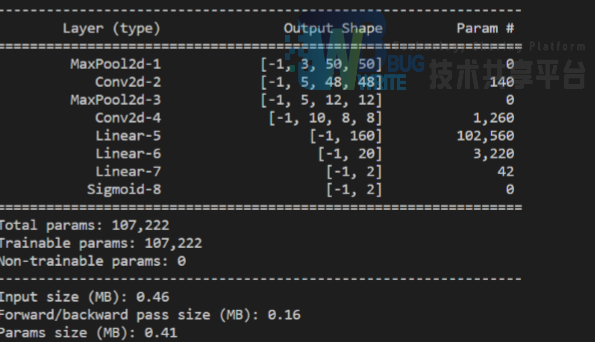
损失函数:BCELoss
参数选择
以1:4将训练集划分为验证集(validation)和训练集,以下将探讨学习率(learning_rata)、epoch、batch_size、优化器,正则化系数λ对验证集准确率的影响。

总结
在提高模型一精度的过程中,各种手段(包括数据增强,各种超参数调节均未取得较大进步,最高准确率只有89%,有理由确定该模型是影响精度的主要原因,猜测原因主要是模型深度还不够,可调节的参数不够多)
5.3.2 模型二
模型结构
模型二通过使用小的3*3的卷积核进行处理,叠加5层,拉平后接全连接层,这样使得网络深度足够,有足够多的参数。下图是部分网路结构。
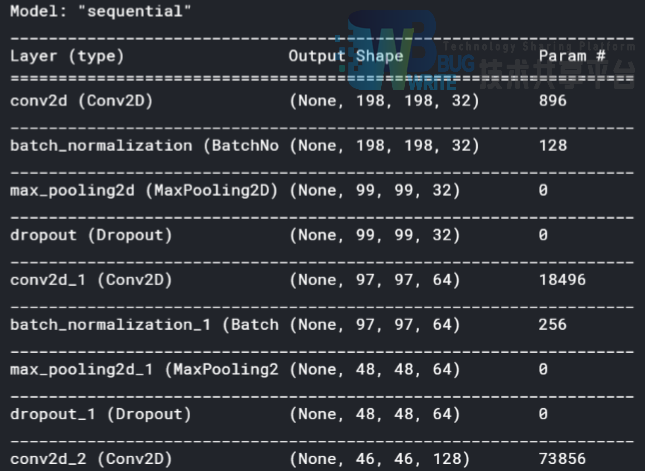
该网络除了使用小的卷积核之外,还使用了dropout方法,这也是一种正则化方法,随机的让部分神经元失活,可以防止过拟合的出现。而且该网络在每一个卷积层的输出添加了Batch Normalization层,该层可以让网络训练过程中使得每一层神经网络的输入保持相同分布。
训练过程
在模型1的训练过程中通过手工调整超参数费时费力,在该模型中我们使用ReduceLROnPlateau,通过监测验证集上的损失(val_loss)来动态的调整学习率,而且配合EarlyStopping,可以在val_loss多次不再变化后停止训练,更容易获取训练的最佳点。
实验表明,通过多次训练,该模型最佳可达到91.2%的准确率。
5.3.3 模型三
迁移学习
模型迁移利用上千万的图象训练一个图象识别的系统,当我们遇到一个新的图象领域,就不用再去找几千万个图象来训练了,可以原来的图像识别系统迁移到新的领域,所以在新的领域只用几万张图片同样能够获取相同的效果。模型迁移的一个好处是可以和深度学习结合起来,我们可以区分不同层次可迁移的度,相似度比较高的那些层次他们被迁移的可能性就大一些。
所以在遇到特征比较相似的情况时,可以使用预训练模型来达到自己的目的。
VGG16迁移学习
通过大量实践,并跑了多个预训练模型,发现对于人脸性别识别任务上VGG16效果最好,验证集上效果最高可到到92.7%,下表展示了VGG16训练过程中的部分数据。

在此之前,或许因为训练经验不足,其他的预训练模型都没有产生理想的结果,也因为kaggle上gpu使用时间的限制和速度的限制,没有对其他模型进行大量的训练工作,也可能是其他模型识别的特征与该任务相差太大,训练结果见下表所示。
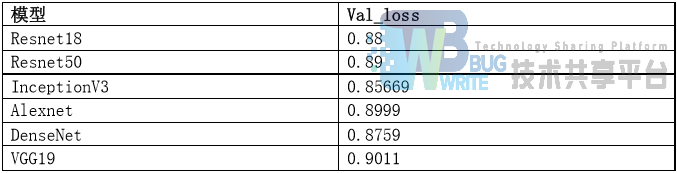
5.4 模型融合
在获取了大量的训练结果数据后,所谓三个臭皮匠,胜过诸葛亮,模型融合是一个很关键的步骤,能够大大提高精度。模型融合方法很多,下面介绍使用到的几个方法。
5.4.1 投票
如果是三个性能较差,但是高度不相关的模型:

可以看到大大的提高了精确性。
5.4.2 带权重的投票
得到了一堆准确率差别挺大的数据,经过实验,随着低准确率样本数增多,投票过后的精度并不会再升高,反而不如用精确率最高的几组数据进行投票。可以想到这样一个场景:对于一道题,就算有2个成绩一般的人选A,反而你更宁愿相信成绩很好的人说选B,复原到该任务中,一个准确率很高的结果的票数远不止1票才合理。基于这种思想,将得分高的结果票数增多取得了比平均投票更好的效果。但是探索合适的权重仍然是一个复杂的工作,相信合适权重分配能取得更好的表现。
6 实验结果与分析
6.1 实验结果
通过大量实验,模型一的最佳测试集结果为0.89,模型二的最佳表现为0.916,模型三的VGG16迁移学习最佳测试集结果可达到0.927,在通过投票和带权重的投票模型融合手段下,最佳测试集结果可达到0.93447。
6.2 结果分析与展望
对于这个结果,我觉得还存在很多不足,主要还有很多工作没有做完,主要有以下工作:
在模型融合上,权重探索还不够多,而且单纯的对结果投票并没有对各个模型物尽其用,基于这个问题,我觉得可以将各个表现比较好的模型最后一个卷积层拉平的向量V保存下来,然后将几个模型的向量V进行拼接,通过一个或者多个全连接层进行训练,相信可以最大化的发掘出每个模型的优点
对于一个不错的模型,因为gpu和设备的限制,只用到了部分数据,并且没有去做K交叉验证,所以应该还有一定的提升空间
我一直有一个想法:模型输出的是为男性或者女性的概率,那么当模型输出值在0.45-0.55的时候,说明模型也觉得既像男性,又像女性,那么这个时候模型输出的结果属于“值得怀疑的结果”,我们可以对于这部分的输出再进行训练,提取更多的特征
对于诸多复杂的预训练模型,没有进行大量而丰富的训练,并没有得出其最好的结果,相信其中还有很多潜力等待挖掘
其次,对于各种trick还不够熟悉,对于模型的设计还有很多不足
在对于图像数据清洗和处理上,在明知道有错误数据,但是却未来得及处理。
我相信,随着自己不断地学习,以及条件地改善,这些遗留问题都会被一一解决,自己也能对该类问题更加游刃有余。
- 隐藏此二维码 [详细] -->
赞
踩

