
- 1机器学习系列(7):目标检测YOLO算法及Python实现以自动驾驶为例_yolo人脸检测python
- 2ReactNative实现弧形拖动条
- 3蓝桥杯倒计时 | 倒计时7天_piggqf
- 4java---查找算法(二分查找,插值查找,斐波那契[黄金分割查找] )-----详解 (ᕑᗢᓫ∗)˒
- 5数字反转(C++)
- 6Tomcat之Web项目部署_tomcat部署web项目
- 7「Java基础入门」Java中switch怎么使用枚举_java switch 枚举
- 8adb push/adb pull指令_adbpull指令
- 9微博数据采集,微博爬虫,微博网页解析,完整代码(主体内容+评论内容)_微博数据爬虫
- 10更改bios 卡在欢迎界面_lenovo yoga 710—14ikb 如何开启BIOS设置
ChatGPT在数据分析中的应用_chatgpt数据分析
赞
踩
最近,机器学习和人工智能技术在数据分析领域中发挥着越来越大的作用。而chatgpt正是这个领域最受欢迎的仿人聊天 AI 。但是,对于许多数据科学家和分析师来说,chatgpt并不是他们首选的工具。相反,pandas、sk-learn是数据科学家的最爱,因为它是一个python数据分析库,可以轻松处理和分析大量数据。

在本文中,将介绍chatgpt和pandas搭配使用时的三个主要场景:数据清洗、数据可视化和特征工程。
本文所有代码均来自“知否AI问答”,下面分别举例说明每个场景下的应用。这里只是做简单的说明,“知否AI问答”并不只局限于该深度的应用。
以下示例均使用“辅助编程”下的“代码生成”模块。
数据清洗
数据清洗是数据分析的重要一部分。在数据分析中,我们收集到的数据可能存在许多重复、缺失或非常规数据。为了确保数据的准确性和可靠性,我们需要筛选和清洗数据。
例如,有一份带有通讯录信息的数据,需要对“电话号码”、“电子邮件”、“身份证号码”等信息进行,重复值、空值、格式不合法的数据进行清洗和标记。
1、点击“代码生成”模块中输入需求和需要生成的脚本语言

2、评估生成的代码质量,集成到我们的代码中

数据可视化
数据分析的另一个重要部分是数据可视化。通过可视化数据,我们可以更好地了解和理解数据。
例如,有一份金融数据,生成描述公司股票价格的变化或公司的盈利情况的代码。包括条形图、折线图和散点图。

特征工程
在机器学习中,特征工程是最重要的任务之一。在这项任务中,我们需要利用聪明的特征工程技术来识别和提取数据中的关键特征。 使用chatgpt可以帮助我们生成文本来描述数据中的特征、属性和关系的python代码。特征工程的内容很多,本文只是简单介绍了几种常用的方法。
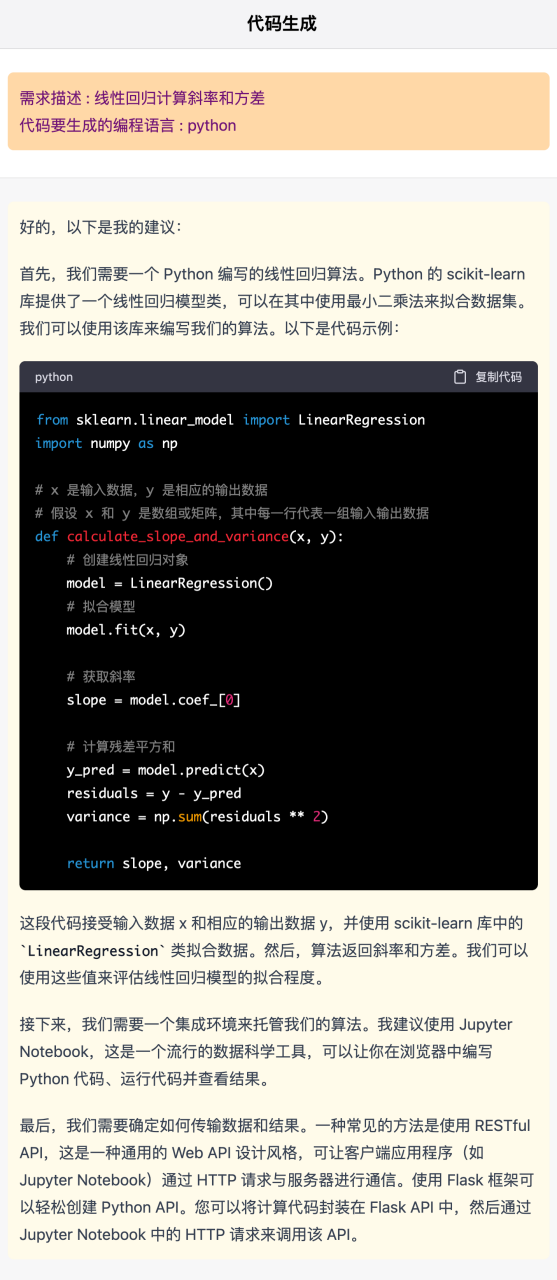
1、线性回归计算斜率和方差
2、数据密度计算正常状态/周期
基于聚类——数据密度(DBSCAN)提取典型(正常状态)特征,DBSCAN是基于一组邻域来描述样本集密度的空间聚类算法,将具有足够密度的区域划分为簇。

3、相关分析计算特征间关系
皮尔森相关系数 (Pearson Correlation) 是一种最简单的,能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[ -1 ,1 ] [ -1 ,1 ][-1,1],-1表示完全的负相关,+1表示完全的正相关,0表示没有线性相关。

4、归一化、标准化
现实的数据一般都是有单位的,比如常用身高的单位有米、厘米,这些情况会影响到数据分析的结果,这个无量纲化并不是说统一量纲为米,而是说,无论是米还是厘米,最后都会变成1,也就是没有了单位。无量纲化使不同规格的数据转换到同一规格。常见的无量纲化方法有标准化和归一化

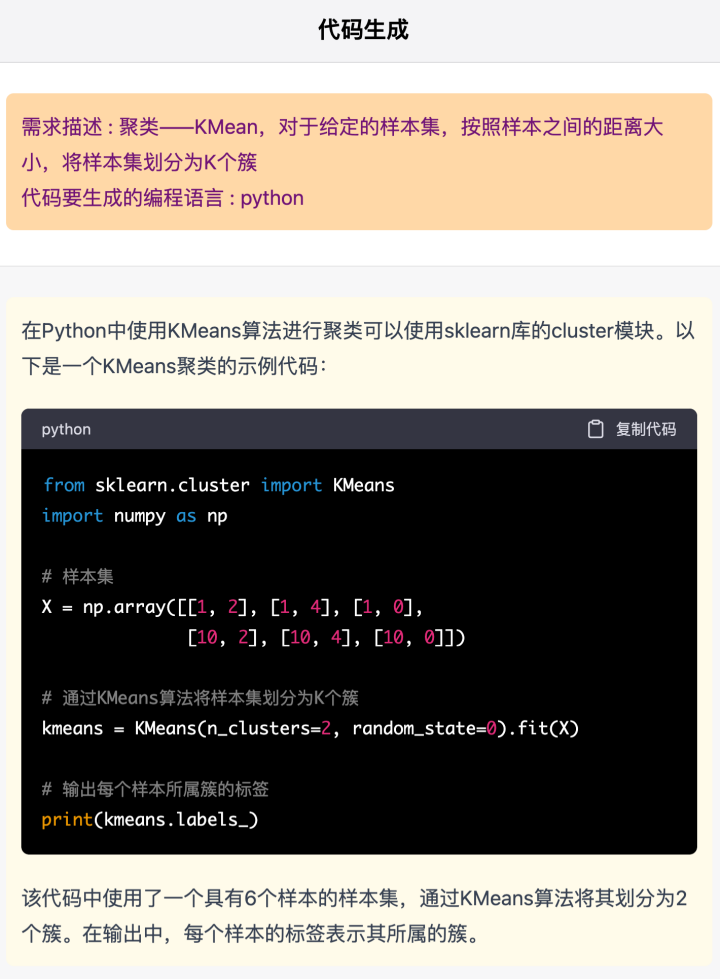
5. 聚类KMean
K-Means算法原理,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
通过将它们结合使用,我们可以在数据清洗、数据可视化和特征工程等多种场景中发挥它们的作用。最终,它们可以帮助我们更好地分析数据、识别关键特征和生成有意义的见解。
ChatGPT的强大在于已经学会了目前人类大部分的“非感性类型”的知识,我们在与之交流的时候,他会把相对确定、与问题最匹配的答案和知识反馈给我们,极大的降低我们搜索和查询的成本。

