
热门标签
热门文章
- 1Unity3D开发之WebGL平台上 unity和js前端通信交互_unity 跟js 交互
- 2释放pytorch占用的gpu显存_pytorch程序异常后删除占用的显存操作
- 3【Microsoft Azure 的1024种玩法】七十五.云端数据库迁移之快速将阿里云RDS SQL Server无缝迁移到Azure SQL Database中_azure 迁移sql 到阿里云
- 4【K8S系列】深入解析k8s网络
- 5qt day3
- 6详解MySQL事务日志——undo log_undo log存的是什么
- 7SqlSugar小结_sqlsugar ignorecolumns
- 8小鹤输入法及练习工具推荐_小鹤双拼在线练习
- 9游戏开发者的操作系统课设的正确打开方式(Unity3D)_unity完成操作系统
- 10Typora收费了?推荐两款Markdown编辑器
当前位置: article > 正文
大模型的实践应用6-百度文心一言的基础模型ERNIE的详细介绍,与BERT模型的比较说明_bert与ernie掩码策略对比
作者:weixin_40725706 | 2024-02-17 23:45:02
赞
踩
bert与ernie掩码策略对比
大家好,我是微学AI,今天给大家讲一下大模型的实践应用6-百度文心一言的基础模型ERNIE的详细介绍,与BERT模型的比较说明。在大规模语料库上预先训练的BERT等神经语言表示模型可以很好地从纯文本中捕获丰富的语义模式,并通过微调的方式一致地提高各种NLP任务的性能。然而,现有的预训练语言模型很少考虑融入知识图谱(KGs),知识图谱可以为语言理解提供丰富的结构化知识。我们认为知识图谱中的信息实体可以通过外部知识增强语言表示。在这篇论文中,我们利用大规模的文本语料库和知识图谱来训练一个增强的语言表示模型(ERNIE),它可以同时充分利用词汇、句法和知识信息。实验结果表明,ERNIE在各种知识驱动任务上都取得了显著的进步,同时在其他常见的NLP任务上,ERNIE也能与现有的BERT模型相媲美。
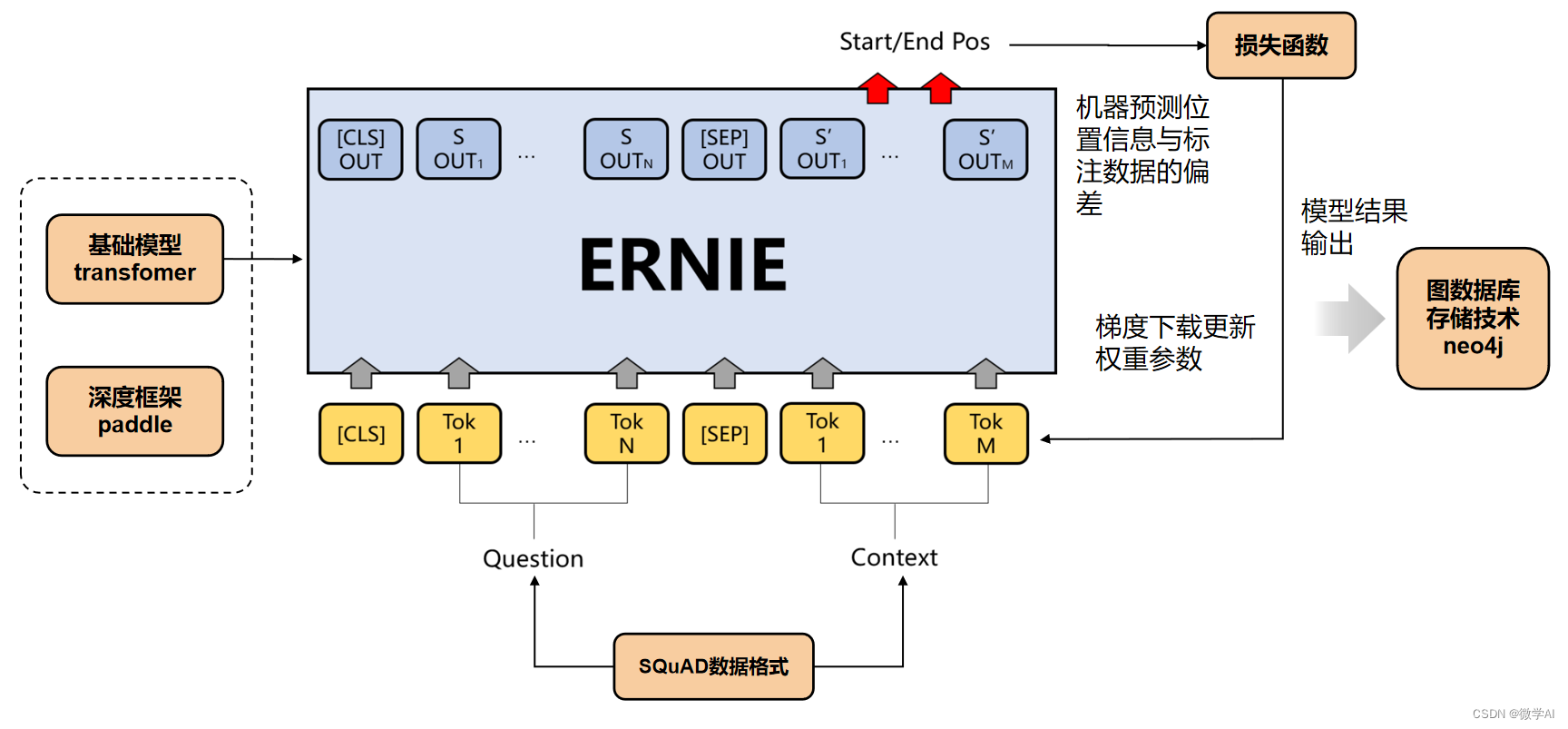
一、ERNIE和BERT的比较
首先,百度的ERNIE和BERT都是基于Transformer的预训练语言模型,但它们在模型架构和训练方式上有一些区别。
-
模型架构上的区别:
- BERT是谷歌在2018年提出的预训练深度双向语言模型。BERT的特点是通过遮挡一部分输入词汇(Masked Language Model)然后让模型预测这些被遮挡的词汇,以及下一句预测(Next Sentence Prediction)来进行模型的预训练。
- ERNIE(Enhanced Representation through kNowledge IntEgration)是百度在2019年提出的预训练深度语言模型。ERNIE的创新点在于它采用了基于知
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/102459
推荐阅读
相关标签

