
- 1Podman添加私有镜像源配置 registries.conf_/etc/containers/registries.conf
- 2探索无限:Sora与AI视频模型的技术革命 - 开创未来视觉艺术的新篇章
- 3[Android]开机自启动脚本和selinux权限配置_手机 开机自启动脚本
- 4淘宝爬虫商品销量数据采集_爬取淘宝
- 5Docker中的RabbitMQ已经启动运行,但是管理界面打不开_docker启动rabbitmq后无法访问
- 6一文看懂,python抓取m3u8里ts加密视频及合成、多线程、写入的问题_scrapy下载m3u8加密视频
- 7DNS解析-连接域名与服务器IP_dns怎么和域名关联
- 8ELF文件详解—初步认识_.elf
- 9腾讯云数据库品牌升级,大咖解读数据库三大变化_腾讯云数据库生态解读
- 10已知图像坐标系求相机坐标系_相机标定之张正友标定法数学原理详解(含python源码)...
百度“文心一言”大模型(ERNIE)发布了,对标ChatGPT_文心一言大模型的大小
赞
踩
大家好,我是微学AI,今天给大家介绍一下基于大语言模型的背景下,国内外的发展现状,以及百度的“文心一言”大模型。
一、自然语言处理模型的发展
自然语言处理(NLP)大模型的发展可以追溯到早期的简单的规则模型,再到后的机器学习,近十年崛起的神经网络和深度学习研究。直到2017年基于注意力机制的transformer模型的横空出世打开了自然语言处理的新篇章,Google的研究团队在2018年发布了名为BERT(Bidirectional Encoder Representations from Transformers)的模型,在当时打破了自然语言处理11项任务的最好成绩,从此自然语言处理领域才真正迎来了巨大的变革。BERT采用了一种无监督的预训练方法,通过大规模的语料库学习文本表达,具有惊人的性能和通用性,成为自然语言处理领域里的里程碑式进展。
BERT之后,又陆续出现了GPT1、XLNet、RoBERTa等模型,它们在模型结构、预训练任务和微调方式上都有所创新,并且不断刷新了各类自然语言处理任务的最佳性能。到了2020年OpenAI公司发布了GPT-3模型,号称参数量高达1750亿个,在各类自然语言生成、理解、对话等任务上都有着非常出色的表现。
OpenAI在2022年11月发布了ChatGPT,以对话的形式与模型进行问答,真正颠覆了整个人工智能领域,大家都对他更加的关注。今日OpenAI又发布了GPT-4模型,有更多惊艳的功能。

在国外的AI热潮之前,国内也在加速开发中国版的ChatGPT,希望能够对标ChatGPT。国内大厂也是大量投资,大力发展AIGC领域,也有取得一些成绩。
2023年3月16日14:00,百度发布自然语言处理大模型“文心一言”(ERNIE Bot)。模型的推出有助于对公司核心产品搜索引擎带来全面升级,百度搜索今年在技术上重要的工作就是要把整个检索系统变成检索+生成双模系统。

二、“文心一言”大模型优势
文心大模型的基础底座:百度的文心大模型(2019 年推出)和Open AI的GPT模型类似,且“文心一言”所基于的ERNIE系列模型具备跨模态、跨语言的深度语义理解与生成能力。此外,“文心一言”并非百度文心大模型的第一个产品,其AI作画平台“文心一格”和产业级搜索系统“文心百中”已经面相公众开放。
算力方面:百度拥有多个云计算可用区、庞大的超算集群,我们认为,百度智能云能为ERNIE大模型应用提供高并发、高弹性、高精度等不同计算需求。
数据方面:百度现有数据规模能够助力产品实现 0-1,且模型在用户、数据的良性循环下有望变得越来越聪明,形成马太效应。商业应用面向B端和C端两个延展方向。
三、“文心一言”大模型的应用方向
面向C端应用:“文心一言”植入在百度搜索中双引擎运作,一方面可以弥补搜索效率不高的问题,同时也可以弥补“文心一言”单一答案生成、用户信任度不够的短板;
面向B端应用:“文心一言”搭载在云计算产品上赋能各行各业创意生成、内容创作等,AI辅助工作有望帮助企业大幅降低成本,商业前景可期。公司整体基本面下行风险低,上行空间大。
“文心一言”大模型是基于文心大模型发展而来的,中间加了很技术,例如强化学习、知识增强等;
四、文心大模型全景图
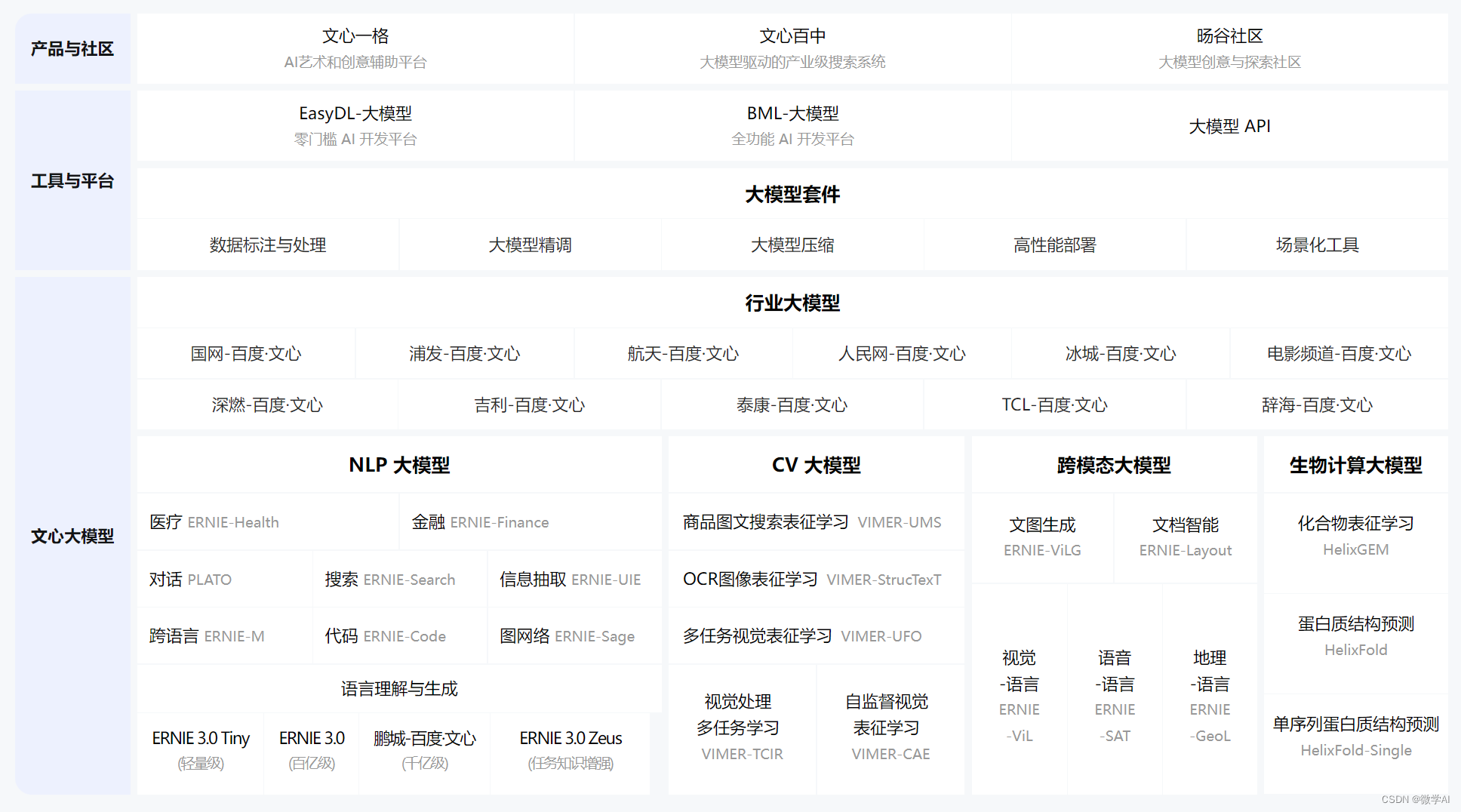
大模型积累:
百度对于类似 GPT 的核心大模型早有积累。百度的文心大模型和 Open AI 的 GPT 模型类似,在2019 年就已经推出,并且已经迭代了多轮,已经从单一的自然语言理解延申到多模态包括视觉、文档、文图、语音等,因此“文心一言”所基于的 ERNIE 系列模型也已经具备较强泛化能力和性能。以最新发布的 ERNIE 3.0 Zeus 为例,该模型迭代于 ERNIE 3.0,拥有千亿级参数,其已经具备智能创作等各类自然语言理解和生成任务,且公开数据集上小样本学习、理解和生成任务效果皆好于业界其他模型。此外,本次“文心一言”并非是百度文心大模型的第一个产品,其 AI 作画平台“文心一格”和产业级搜索系统“文心百中”已经面相公众开放,由此可见百度大模型实用性较高。
算力支撑:
百度大模型的持续发展有强大算力支撑。百度拥有多个云计算可用区、庞大的超算集群,奠定大模型训练的基础设施。目前公司有阳泉、徐水、定兴三个云计算中心,其中,阳泉智能云数据中心仅一期就可承载 16 万台服务器。我们认为,百度智能云能为 ERNIE 大模型应用提供高并发、高弹性、高精度等不同计算需求。同时,百度自研 AI 芯片“昆仑”已在多场景实际部署几万片,在公司搜索业务中也已形成较强的工程化实践。
今天开始大家就可以试用“文心一言”大模型了,大家根据邀请码进行试用,百度根据大家使用过程的数据反馈,进行模型后续的优化与升级。

