
热门标签
热门文章
- 1vue -- 无法打卡vue ui创建项目_deprecate request@^2.67.0 request has been depreca
- 2react 遍历生产form表单(FormItem)_react 循环form.item
- 3build opencv3.3.0 with VTK8.0, CUDA9.0 on ubuntu9.0
- 4java正则表达式校验日期_java验证出生日期正则表达式
- 501_C++ Qt开发:Qt的安装与配置
- 6C# 使用EPPlus创建Excel文件_c# epplus excel
- 7linux多进程通信框架,Linux下多进程IPC通讯的例子
- 8Unity摄像机详解_unity 摄像机 后视镜开发
- 9DOM编程-表单验证_html dom表单验证
- 10Sora给中国AI带来的真实变化
当前位置: article > 正文
多模态基础---BERT
作者:从前慢现在也慢 | 2024-02-17 23:16:47
赞
踩
多模态基础---BERT
1. BERT简介
BERT用于将一个输入的句子转换为word_embedding,本质上是多个Transformer的Encoder堆叠在一起。
其中单个Transformer Encoder结构如下:
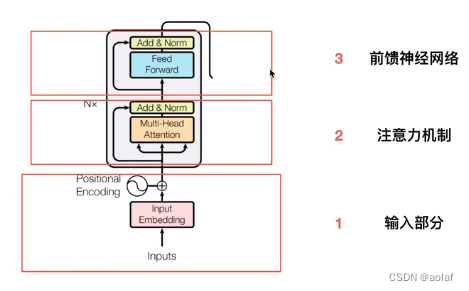
BERT-Base采用了12个Transformer Encoder。
BERT-large采用了24个Transformer Encoder。
2. BERT的输入
原始的句子中包含[CLS] 和 [SEP]两个字符,其中 [SEP]是两个句子间的分隔符,[CLS]则用于做二分类任务,即判断前后两个句子是否相邻。
BERT的输入由三部分组成:
Input = Token Embedding + Segment Embedding + Position Embedding
Token Embedding:将原始句子(包含字符)进行编码
Segment Embedding :第一个句子中每个word彼此编码一致,第二个句子中每个word彼此编码一致,
Position Embedding:位置编码,不同于原始Transformer中的positional encoding的正余弦编码方式,这里采用可学习参数的编码方式。
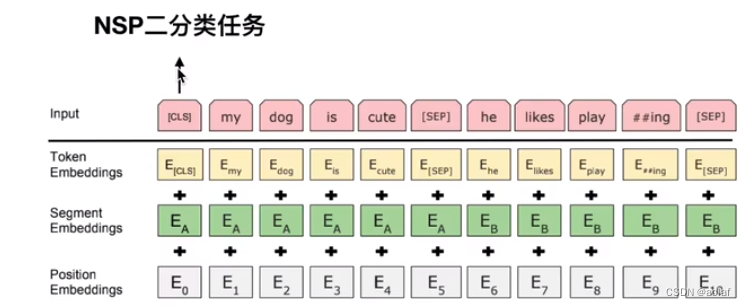
3. BERT的预训练
BERT的训练任务包括:
- 预测被遮挡的单词
- 预测两个句子是否是相邻的句子
1和2是同时训练的
3.1 MLM 任务(Model Language Mask)
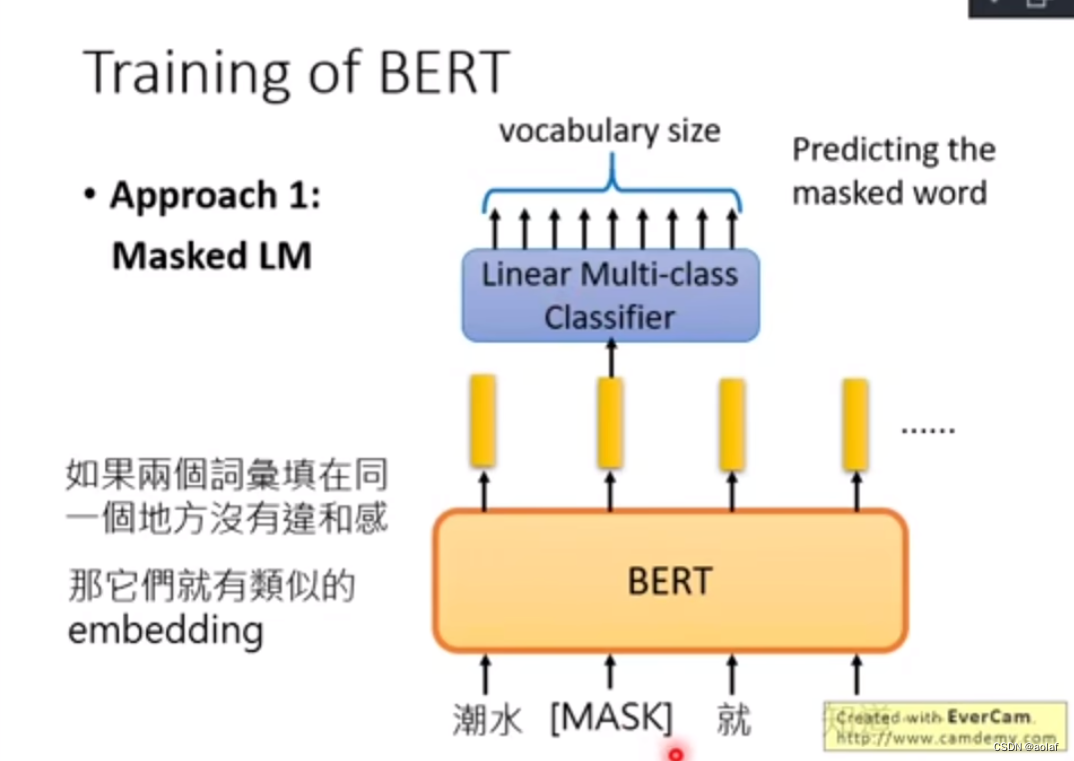
由于BERT在预训练时的数据集很多都是无标签的,因此采用无监督学习方式。
常见的无监督模型包括:
- Auto Regressive(AR),自回归模型,只能考虑单侧信息,典型的就是GPT。

- Auto Encoding, 自编码模型,可使用上下文信息,BERT使用的就是AE。

AE的缺点:忽略了mask和mask之间的联系

3.2 NSP 任务 (Next Sentence Prediction)
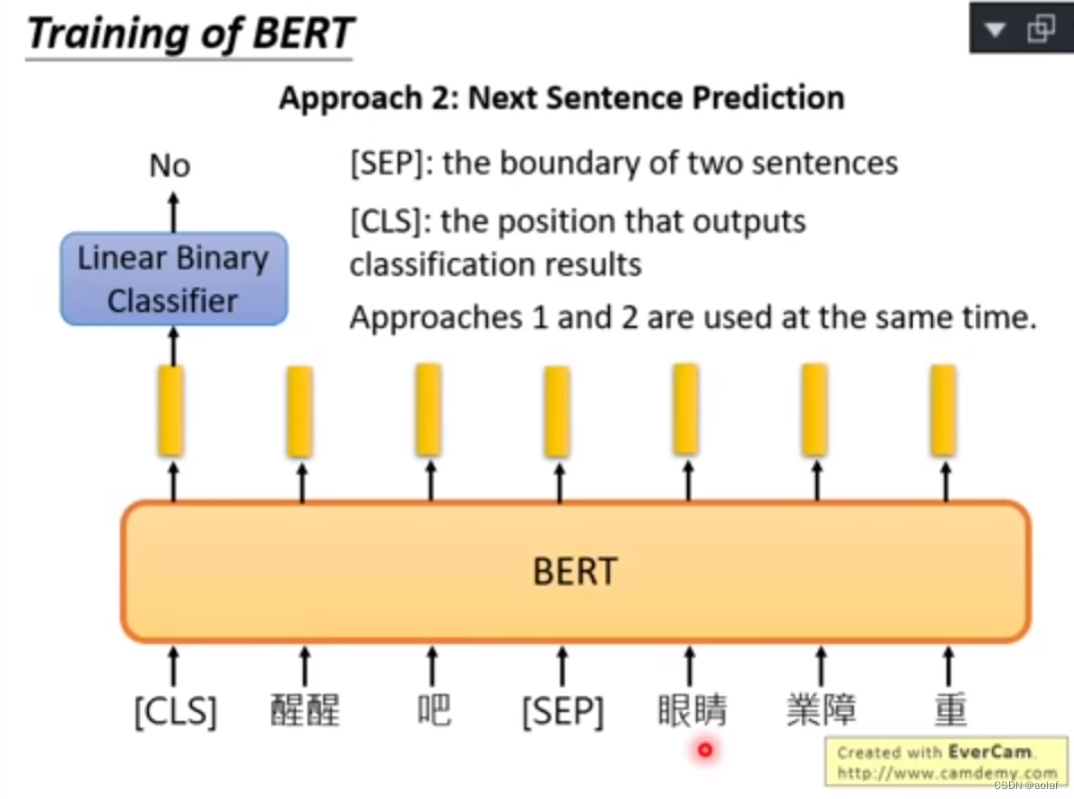
3.2.1 NSP样本
- 正样本:从训练语料库中取出两个连续的段落作为正样本。
- 负样本:从不同文档中随机创建一对段落作为负样本。
缺点:
将主题预测和连贯性预测合并为一个单项任务。由于主题预测任务比较简单,因此降低了整体任务的难度。
改进方式:
从同一篇文档中抽取两个不连续的段落作为负样本
4. BERT的四种用法
- 预测句子的类别:输入一个句子,输出一个类别
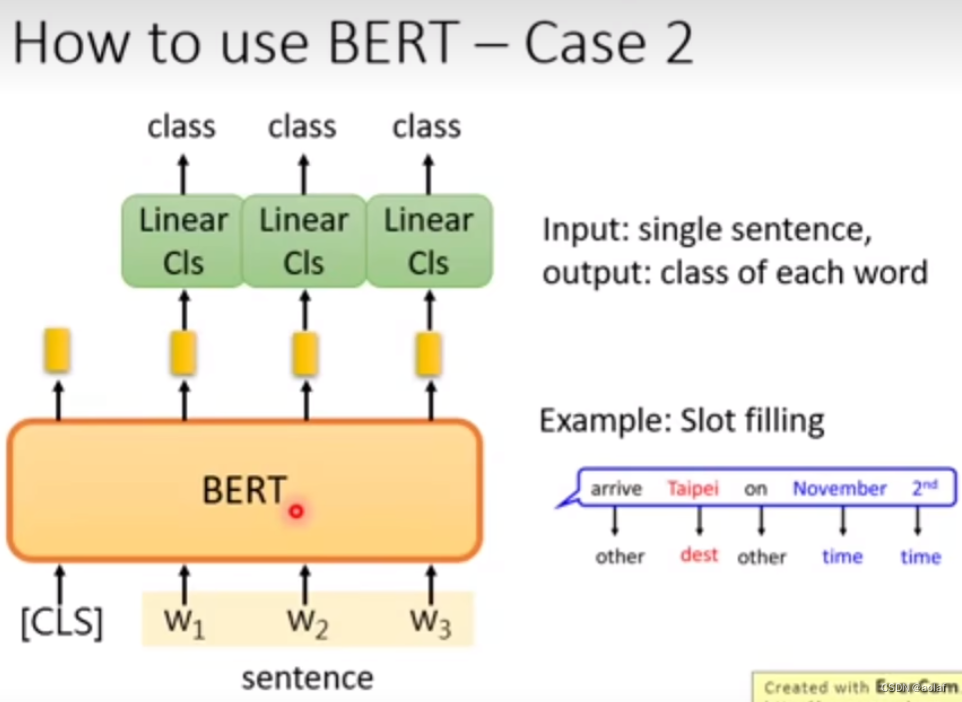
- 预测句子中每个单词的类别:输入一个句子,输出每个单词的类别
- 预测两个句子是否相邻:输入两个句子,输出判断是否相邻的类别
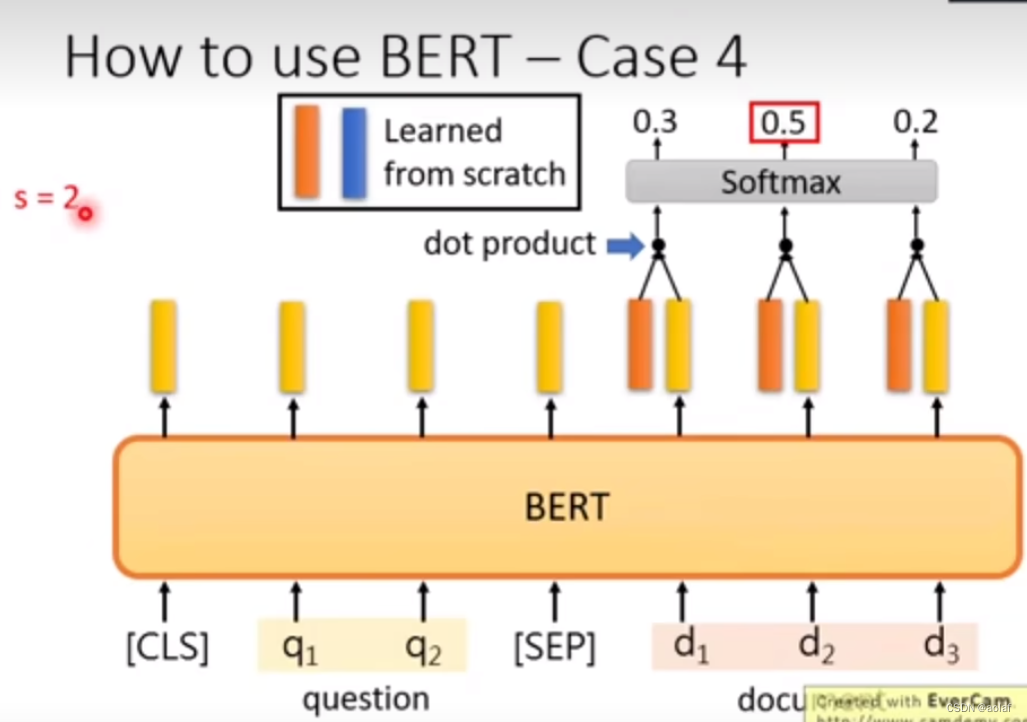
- 预测某个问题在文章中的答案:输入一个问题和一篇文章,输出问题在文章中答案的位置(索引)didj
case1:
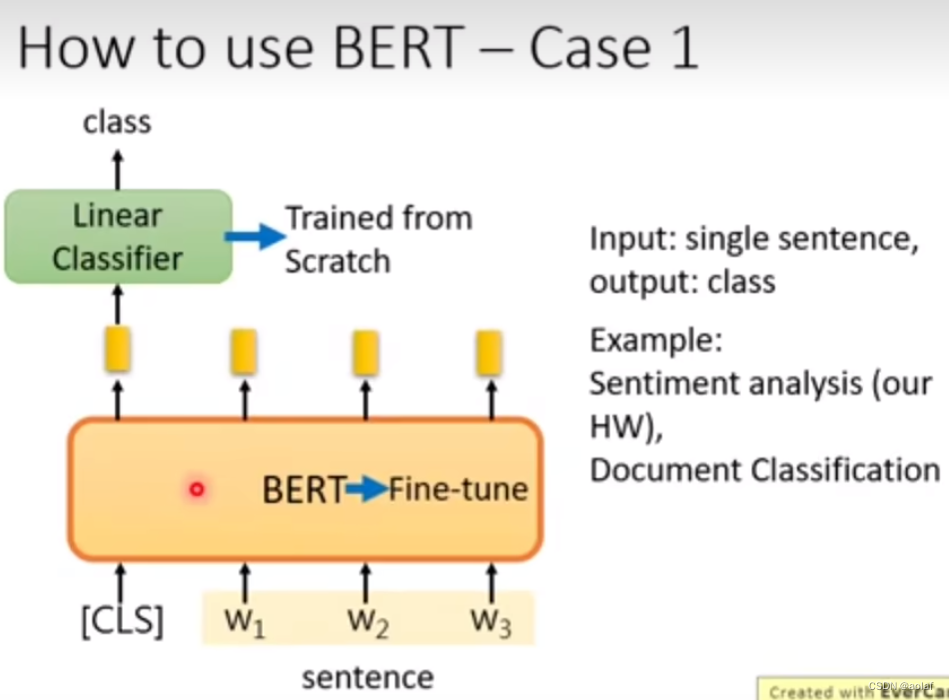
case2:
 case3:
case3:
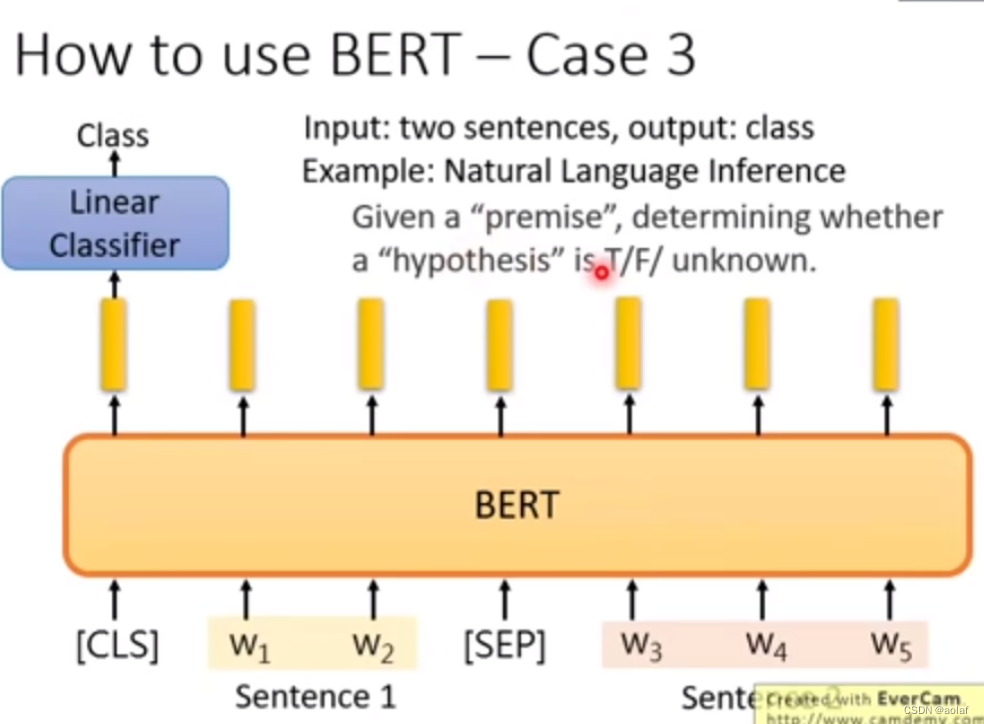 case4:
case4:
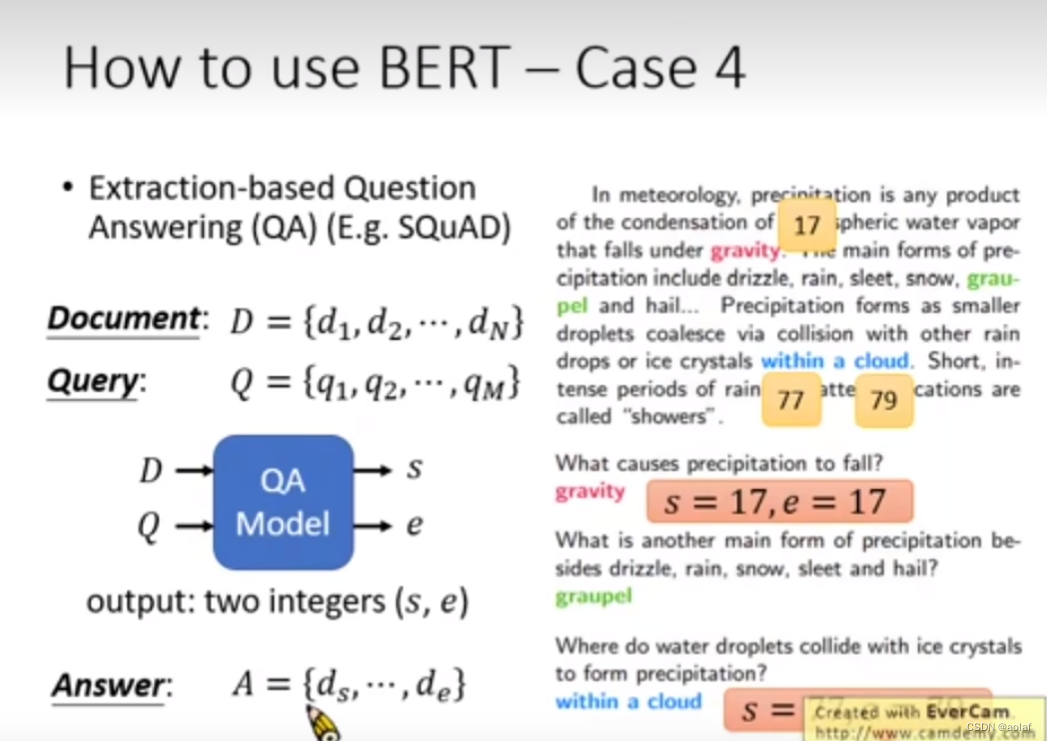

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/102264
推荐阅读
相关标签

