
- 1两年经验的java程序员可以看哪些实用进阶的书籍?_适合两年java经验看的电子书
- 2Surv单因素批量生存分析使用 cox批量生存回归分析有点像deseq2的design差异分析designG:\r\2021_1203_geo\GEO-master\GSE11121_survival_survival包做cox单因素分析用多个样本
- 3Unable to start web server; nested exception is org.springframework.context.ApplicationContextExcept_unable to start web server; nested exception is or
- 4Linux常见面试题-ps查看进程命令_ps -ef| grep java
- 5基于微信小程序高校校园教室预约系统设计与实现 毕业设计论文大纲参考(JSP后台)
- 6Stable Diffusion系列课程上:安装、提示词入门、常用模型(checkpoint、embedding、LORA)、放大算法、局部重绘、常用插件_stable diffusion checkpoint
- 7大师学SwiftUI第6章 - 声明式用户界面 Part 4
- 8html的无语义标签:div & span
- 9【yolov8部署实战】VS2019+OpenCV环境部署yolov8目标检测模型|含详细注释源码
- 10python绘制实时波形图_使用python进行波形及频谱绘制的方法
【Python】Struct 库之 pack 和 unpack 详解_python struct unpack
赞
踩
1. 官网解析
首先是官网对于 pack 、 unpack 、calcsize 以及 Format Strings 的描述
1.1 pack、unpack、calcsize

struct.pack 返回一个 bytes对象,其中包含根据格式字符串 format 打包的值 v1, v2,…
参数必须与格式所要求的值完全匹配

struct.unpack 根据格式字符串 format 从缓冲区 buffer (假设由pack(format,…)打包)中解包。返回一个元组,即使它只包含一个元素。缓冲区的字节大小必须与格式所需的大小匹配,如 calcsize() 所反映的那样。

struct.calcsize 返回与格式字符串 format 对应的结构体(以及由 pack(format,…)生成的 bytes 对象)的大小。
1.2 Format Strings
这一段在官方的描述中很详细,同时也很长,这里我只放几个重要的地方,剩下的可以自行去官网查阅

格式字符串描述打包和拆包数据时的数据布局。它们由格式字符组成,格式字符指定打包/解包的数据类型。此外,特殊字符控制字节顺序、大小和对齐方式。每个格式字符串由一个可选的前缀字符(描述数据的总体属性)和一个或多个格式字符(描述实际数据值和填充)组成。
1.2.1 字节顺序、大小和对齐方式

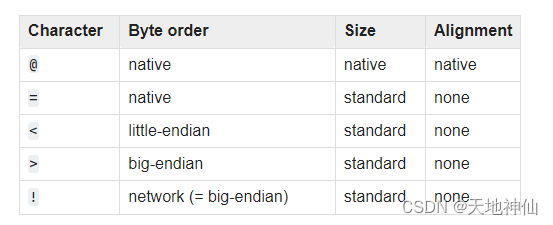
默认情况下,C 语言的类型以机器的本机格式和字节顺序表示,并在必要时通过填充字节来正确对齐(根据 C 语言编译器使用的规则)。选择这种行为是为了使打包结构体的字节与相应的 C 语言的结构体的内存布局完全对应。是使用本机字节排序和填充还是标准格式取决于应用程序。格式字符串的第一个字符可以用来指示字节顺序、大小和打包数据的对齐方式,如下表所示:
1.2.2 格式字符

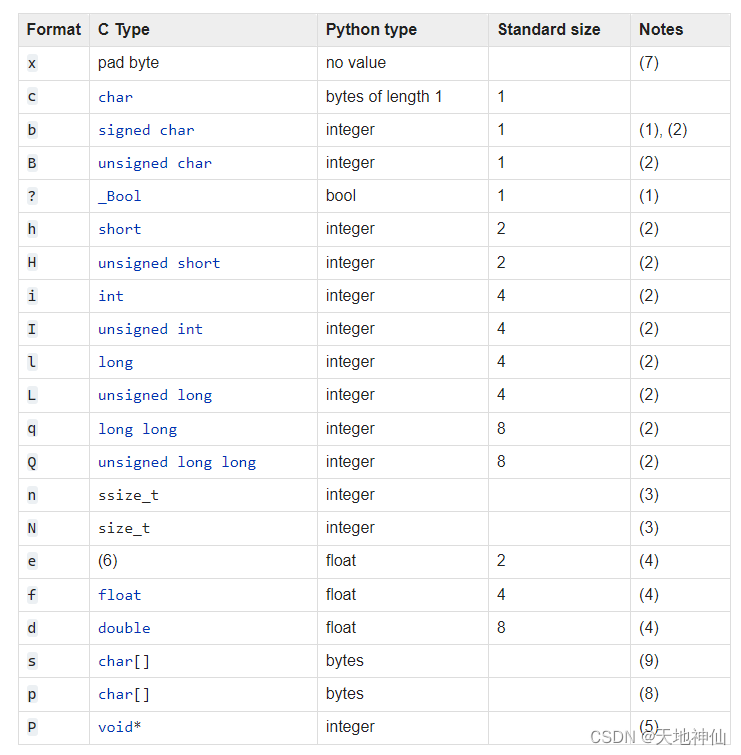
格式字符有以下含义:给定 C 和 Python 值的类型,它们之间的转换应该是显而易见的。Standard size 列是指使用Standard size时,以字节为单位的打包值的大小;也就是说,当格式字符串以 <,>,!或= 开头的时候(详情见上面一个表格的 Size 列)。当使用 native size 时,打包值的大小取决于平台。
2. pack 解析
pack会把给定的数据按照 format string 的方式去打包我们来看看例子
例子 1
from struct import *
print(pack(">bhl", 1, 2, 3))
- 1
- 2
这里 format string 为 >bhl,其中 > 代表采用大端(高位字节在前)的方式打包, b、h、l 分别代表采用 signed char、short、long(对于 C 语言)的数据类型来分别打包 1、2、3,他们分别占用 1 字节、2 字节和 4 字节,下图是运行的结果。b 开头表示是字节类型,输出的结果和我们分析的结果一致
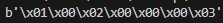
例子 2
from struct import *
print(pack("<2hl", 1, 2, 3))
- 1
- 2
这里 format string 为 <2hl,其中 < 代表采用小端(低位字节在前)的方式打包, 2h 代表前面 2 个数据采用 signed short 类型、进一步的,我们可以使用 x+格式字符 来表示,后续 x 个字符都用此格式字符来打包
下图是运行的结果:b 开头表示是字节类型,输出的结果和我们分析的结果一致。

例子 3
注意下面代码的运行结果
from struct import *
print(pack("@3c", b'1', b'2', b'3'))
print(pack("@1s", b'123'))
print(pack("@2s", b'123'))
print(pack("@3s", b'123'))
- 1
- 2
- 3
- 4
- 5
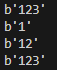
这一段代码主要是 format string 的不同导致了打包的结果和入参不同,其中 c 是以 char 类型去打包,3c 是代表后续的 3 个参数全部按照 char 去打包,而 s 是以 char[] 类型去打包,而 s 前面的数字则是代表打包多少位
3. unpack 解析
unpack 可以理解为是 pack 的逆向,直接看例子
例子1
from struct import *
print(unpack(">bhl",pack(">bhl", 1, 2, 3)))
- 1
- 2
将上面第一个例子的输出作为unpack的参数输入,然后按照和打包一样的 format string 去进行解包我们可以得到如下的结果,与我们的输入是一致的。
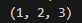
当然,在很多场景下并不是像这样自己打包数据然后再自己解包,而是需要按照一定的协议去解来自其他地方的字节流,于是可以这样写,在 data 中换成需要解包的数据,然后根据包的协议(字节顺序、大小和对齐方式)来编写解包的 format string
from struct import *
data = b'\x01\x00\x02\x00\x00\x00\x03'
print(unpack('>bhl', data))
- 1
- 2
- 3

