
- 1Anthropic 的 Claude AI 的提示技术
- 2树莓派上搭建Nginx服务器_树莓派如何配置nginx
- 3CVPR‘2023 即插即用系列! | BiFormer: 通过双向路由注意力构建高效金字塔网络架构_biformer注意力机制
- 4HUAWEI HiCar走向深度生态开放,助力汽车成为下一个超级终端_华为hicar授权实验室
- 5Python学习系列:面向对象高级编程(-)_python高级编程(面向对象)
- 6为什么不推荐Selenium写爬虫_爬虫selenium的缺点
- 7调用MapReduce对文件中各个单词出现的次数进行统计_eclipse用mapreduce实现计数
- 8YOLOv5 提升小目标识别能力 解决VisDrone2019数据集_yolov5测试visdrone
- 9鸿蒙 手游sdk 开发教程_鸿蒙sdk
- 10语义计算、知识图谱与智能问答(医药常识问答实例)_医疗智能问答csdn
下载并处理【T0】指令微调数据集--手把手教程
赞
踩
T0 benchmark(或者叫P3)是一个大规模的人工标注instruction tuning数据集,在ICLR 2021 T0一文中提出,其收集了来自huggingface hub上的多任务数据,并为每一个task都装备了来自prompt source的人工撰写指令。
P3数据集可以在huggingface上找到:链接
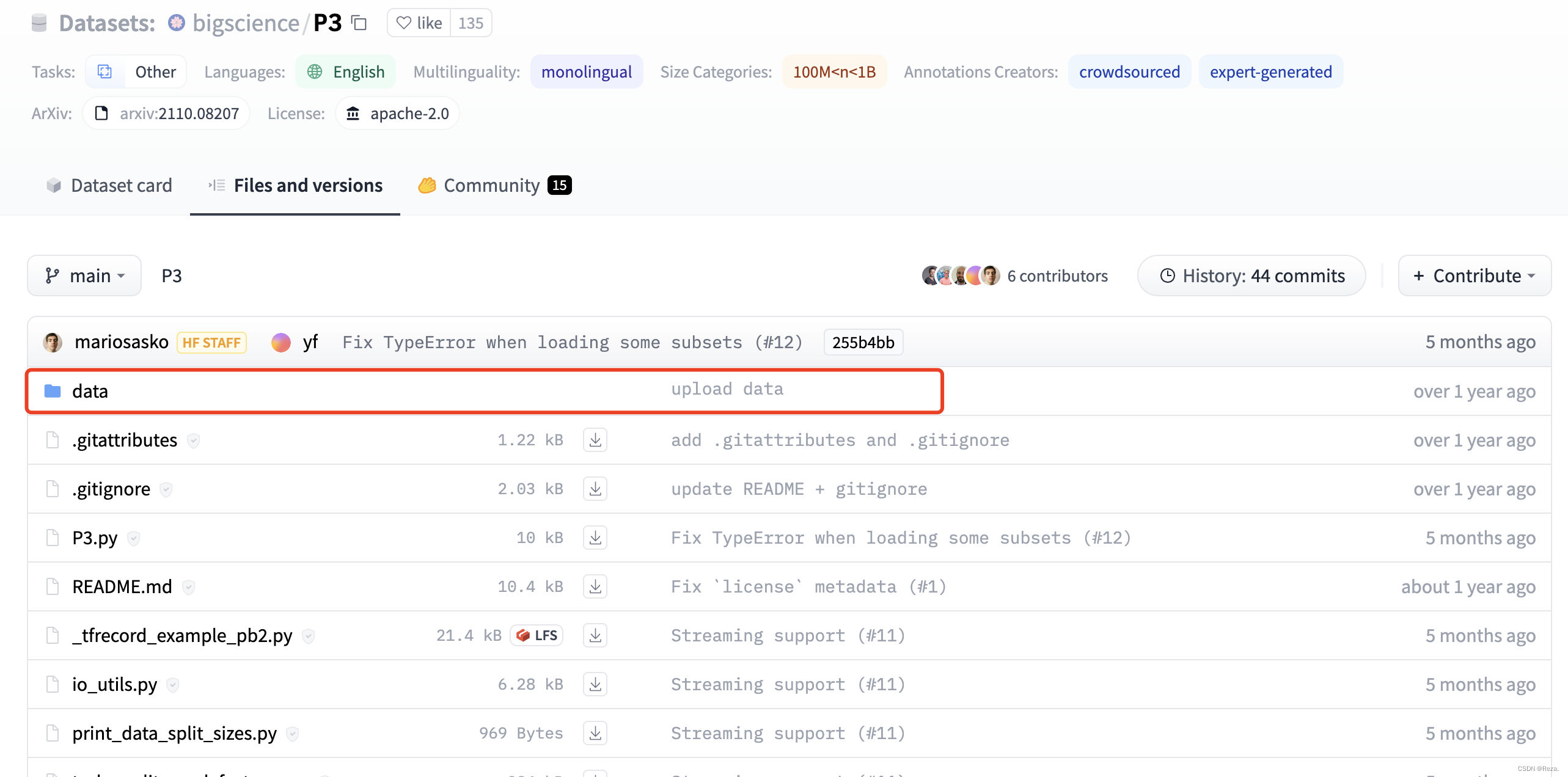
然而我们下载之后会发现,所有数据文件都以.tfrecord,而且打开之后的内容非常怪异:
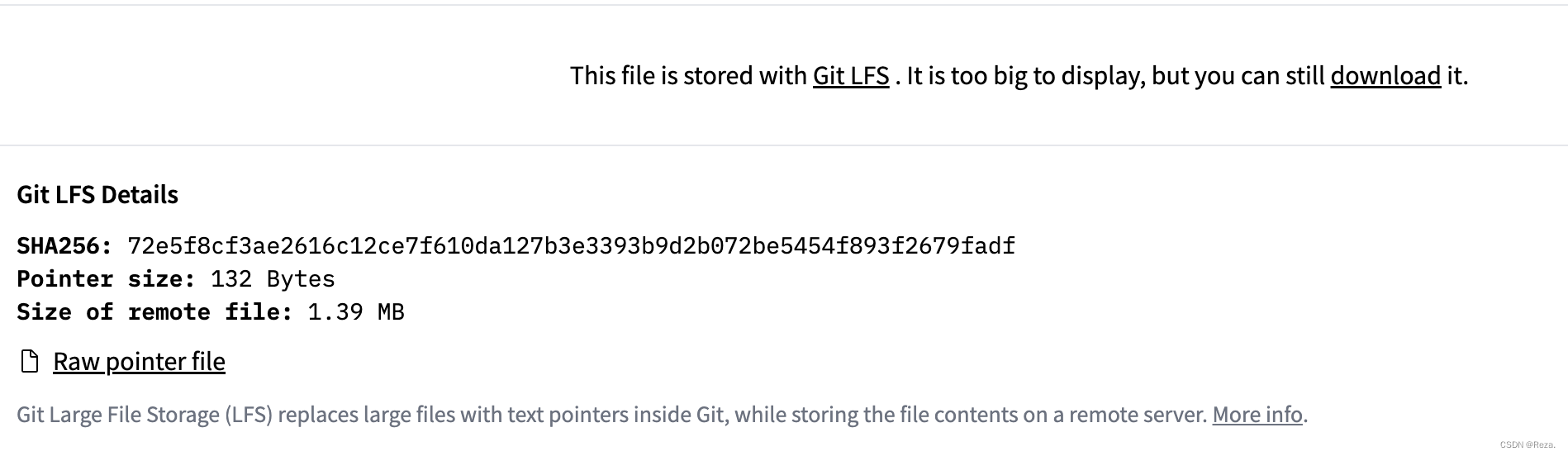
如上图所示,下载的所有数据文件,都是Git LFS 文件(也就是large file system),可以简单理解成pointer,记载了数据所在的存储地址,而真正的数据其实并未下载成功,它们还存储在pointer指向的远端服务器上。
要完全下载P3,需要遵从如下步骤:
1. 下载Git lfs
首先要下载git-lfs, git lfs 官网:https://git-lfs.com/
以mac为例:brew install git-lfs就可以直接安装。
linux的话需要有sudo权限,目前笔者并未找到靠谱的linux上源码安装git-lfs的方法,具体参考:https://askubuntu.com/questions/799341/how-to-install-git-lfs-on-ubuntu-16-04
2. clone仓库
接下来就直接把p3从huggingface hub上克隆下来:
git clone https://huggingface.co/datasets/bigscience/P3
- 1
克隆下来之后,会发现整个仓库其实很小,如前面所述,这个时候并未把正真的数据下载,而只是下载了所有LFS文件罢了。
3. 还原LFS文件
接下来先进入P3的根目录,
然后用如下命令,使用git-lfs将所有lfs文件指向的远端文件,都下载下来:
git lfs install # git-lfs initialization, set `--force` if there is any errors
git lfs pull # download all files pointed by lfs
- 1
- 2
然后就进入了漫长等待。。。整个P3的完整数据应该差不多几百个G大小。。

4.【可选】挑选evaluation subset
由于整个数据集实在太过庞大,所以我们可以选择只下载部分我们需要的数据。
例如,笔者只希望下载T0的 held-out evaluation set(测试集),没有必要把整个庞大的数据集都给下载下来,所以可以先用如下python脚本,将不需要的tasks全部删掉之后再去下载(读者根据自己需要修改代码):
# remain ANLI R1-R3, CB,COPA and RTE tasks import os import shutil def get_directories(path): directories = [] for entry in os.scandir(path): if entry.is_dir(): directories.append(entry.name) return directories def target_task_dir(directory): ''' only return true when facing with the target task directory. ''' directory = directory.lower() if "anli" in directory and ("r1" in directory or "r2" in directory or "r3" in directory): return True elif "cb" in directory: # super_glue CB return True elif "copa" in directory: # super_glue COPA return True elif "rte" in directory: # super_glue RTE return True else: return False path = "./data" directories = get_directories(path) for directory in directories: if not target_task_dir(directory): # del this directory (including all files in it) shutil.rmtree(os.path.join(path,directory))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
将上述脚本放到P3根目录,python 运行就可以。
删除之后,记得得git保存一下修改:
git add -A
git commit -m "del unused tasks"
- 1
- 2
之后再去git lfs pull。
5. 处理tfrecord文件
tfrecord是一种专属于tensorflow的二进制文件。虽然我们现在已经下载好了所有数据,但是你会发现这些文件仍然无法直接被编辑器打开,我们也没办法直接查看数据内容。
此时,如果你的代码使用的是tensorflow,那么现在下载好的这些tfrecord文件就可以直接用来构建dataset class,训练模型。除此之外,tfrecord文件相较于其他默认的数据格式类型,不仅节省存储,也能让模型训练、推理也能更高效(详见该博客:https://medium.com/mostly-ai/tensorflow-records-what-they-are-and-how-to-use-them-c46bc4bbb564)。
但如果你用的是其他框架,比方说pytorch;或者用做其他用途,那么我们只能将tfrecord文件再转成其他格式,例如json。
以下步骤用来把T0数据集的所有tfrecord文件转化成json:
5.1 下载tensorflow
数据处理过程类似于逆向工程,所以需要用到tensorflow。
笔者下载了gpu 版本tensorflow,cpu版本应该也可以。具体安装过程自行搜索。
5.2 数据格式转换
首先观察T0数据集目前的文件结构。每一个task folder下都会包含若干文件,其中,两种类型的文件尤为重要:
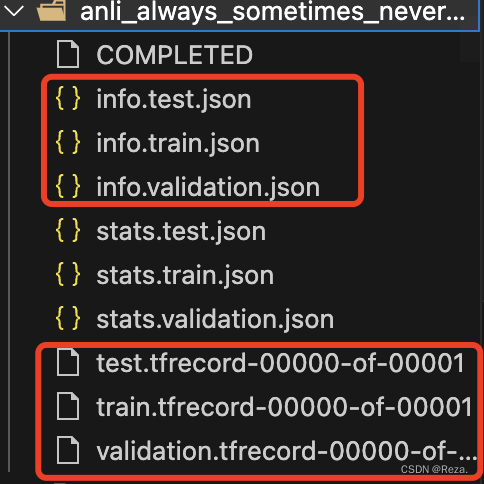
xxx.tfrecord-00000-of-00001: 数据文件,包含了T0数据集的样本info.xxx.json: 格式文件,定义了对应的tfrecord文件的数据格式结构,例如字段名称、数据类型
所以对于每一个task folder,我们都需要将这个task下的所有xxx.tfrecord-00000-of-00001文件转为json格式,而转换则依赖于对应的info.xxx.json文件。
笔者这里直接附上代码(带有详细注释),整个转化过程同样需要消耗一段较长的时间:
import os # set the cuda device os.environ["CUDA_VISIBLE_DEVICES"] = "2,3,4,5,6,7" # specify GPU number, but I didn't find the gpu is acutally used (utility is always equal to 0) import json import argparse import tensorflow as tf import numpy as np from tqdm import tqdm def process_tfrecord(tfrecord_file, feature_schema): dataset = tf.data.TFRecordDataset(tfrecord_file) # features = {key: tf.io.VarLenFeature(getattr(tf, feature_schema[key]["dtype"])) for key in feature_schema} # for bool variable, simply convert to int64 features = {key: tf.io.VarLenFeature(getattr(tf, feature_schema[key]["dtype"])) if feature_schema[key]["dtype"] != "bool" else tf.io.VarLenFeature(tf.int64) for key in feature_schema} data = [] for record in dataset: try: example = tf.io.parse_single_example(record, features) except: print("error in parsing the record: {}".format(record)) print("the features are: {}".format(features)) exit() entry = {} for key, value in example.items(): if key in feature_schema: if feature_schema[key]["dtype"] in ["int64", "bool", "float", "float32"]: entry[key] = value.values.numpy().tolist() else: entry[key] = np.array(value.values).tolist() entry[key] = [v.decode('utf-8') for v in entry[key]] data.append(entry) return data def process_one_file(data_file, info_file, save_file): # read the info file with open(info_file, "r") as f: info_data = json.load(f) feature_schema = info_data["features"] # only support data values in `float`, `int64`, `string`, and `bool` (actually int64) for key, value in feature_schema.items(): # convert int32 to int64 if value["dtype"] == "int32": feature_schema[key]["dtype"] = "int64" tfrecord_file = data_file data = process_tfrecord(tfrecord_file, feature_schema) with open(save_file, "w") as f: json.dump(data, f, indent=2) def main(): parser = argparse.ArgumentParser() parser.add_argument("--meta_path", type=str, default="./data", help="path to the meta folder.") parser.add_argument("--overwrite", action="store_true", help="whether to overwrite the existing files.") args, unparsed = parser.parse_known_args() if unparsed: raise ValueError(unparsed) meta_path = args.meta_path all_subfolders = [f.path for f in os.scandir(meta_path) if f.is_dir()] # get all the folder uder "./data" data_file_names = ["train.tfrecord-00000-of-00001", "validation.tfrecord-00000-of-00001", "test.tfrecord-00000-of-00001"] info_file_names = ["info.train.json", "info.validation.json", "info.test.json"] task_cnt = 0 for idx, subfolder in tqdm(enumerate(all_subfolders), total=len(all_subfolders)): # process only if the subfolder contains the data files (one of the three) if any([os.path.exists(os.path.join(subfolder, data_file_name)) for data_file_name in data_file_names]): print("==> processing task {}...".format(subfolder)) task_cnt += 1 for data_file_name, info_file_name in zip(data_file_names, info_file_names): data_file = os.path.join(subfolder, data_file_name) info_file = os.path.join(subfolder, info_file_name) save_file = os.path.join(subfolder, data_file_name.replace(".tfrecord-00000-of-00001", ".json")) # if the target processed file exists, then we can skip it if `overwrite` is not set if os.path.exists(save_file): if args.overwrite: print("~ overwriting the existing file: {}".format(save_file)) process_one_file(data_file, info_file, save_file) else: print("~ skipping the existing file: {}".format(save_file)) else: process_one_file(data_file, info_file, save_file) else: print("skipping the subfolder: {}, since it does not contain any data files".format(subfolder)) print("\n *** processed {} no-empty task folders out of total {} folders ***".format(task_cnt, len(all_subfolders))) if __name__ == "__main__": main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
简单来讲,上述代码的处理过程主要是利用info.xxx.json中定义的字段信息,使用tf.io.parse_single_example将文件还原回原始数据类型。
处理之后的json文件格式,就会类似于官网定义的样子:


