
- 1pytorch实战---IMDB情感分析_pytorch imdb
- 2神经网络算法基础概念总结_前馈神经系统和反馈神经系统按什么划分
- 3PyTorch从入门到实践 | (1) PyTorch快速入门_《pytorch机器学习从入门到实践》例子
- 4matepath2vec attention机制的 用户电影推荐项目 有数据 代码_matepath2vec 推荐系统
- 5(NLP)文本预处理_文本结构化处理
- 6从瀑布模式到水母模式:ChatGPT引领软件研发的革新之路_chatgpt 驱动软件开发:ai 在软件研发全流程中的革新与实践 pdf
- 7JAVA:SpringBoot中使用websocket出现404问题_webscoket 服务器 404
- 8利用Word2Vec模型训练Word Embedding,并进行聚类分析_word2vec的作用是训练word embedding
- 9从零到一:基于 K3s 快速搭建本地化 kubeflow AI 机器学习平台
- 10大学生创新创业万学答案(二)_万学平台企业求职深度准备答案
Hadoop-HA-3.3.3高可用集群搭建
赞
踩
Hadoop-HA-3.3.3高可用集群搭建
前言
在之前搭建的Hadoop完全分布式集群中存在着单点故障问题,如果namenode宕机或是软硬件升级,集群将无法使用。实现高可用的主要目的就是消除单点故障(SPOF)。HA又包括HDFS HA和YARN HA。本文将介绍hadoop3.x版本的高可用集群搭建,但不完全从零开始搭建,只在原有的配置文件上做修改再测试。
软件版本
- hadoop-3.3.3
- zookeeper-3.8.0
- jdk1.8
- 操作系统:centos7
环境准备
- 修改主机名,主机名和ip地址映射
- 关闭防火墙
- ssh免密登录
- 安装jdk,配置环境变量
- zookeeper集群
之前只在master上配了免密登录,需要在worker1和worker2上面进行同样的操作实现三台机器相互登录免密
一、HDFS-HA集群搭建
HDFS-HA高可用功能是通过配置多个NameNode(active/standby)实现对NameNode的热备用来解决以上问题。当机器崩溃或机器需要维护升级的情况下可以将NameNode快速转移到另外一台机器上。
在HDFS-HA集群中,两台或多台独立的集群被配置为NameNode。在任何时刻只能有一个NameNode处于Active状态,其他NameNode处于Standby状态。而 Standby 只是充当从属节点,保持足够的状态以在必要时提供快速故障转移。
一次只有一个 NameNode 处于Active状态对于 HA 集群的正确操作至关重要。否则,命名空间状态将很快在两者之间产生分歧,从而冒着数据丢失或其他不正确结果的风险。为了保证这个属性并防止所谓的“裂脑场景”,管理员必须为共享存储配置至少一种隔离方法。在故障转移期间,如果无法验证前一个 Active 节点已放弃其 Active 状态,则防护进程负责切断前一个 Active 对共享编辑存储的访问。这可以防止它对命名空间进行任何进一步的编辑,从而允许新的 Active 安全地进行故障转移。
1. HDFS-HA手动模式
集群规划
| master | worker1 | worker2 |
|---|---|---|
| NameNode JournalNode DataNode | NameNode JournalNode DataNode | NameNode JournalNode DataNode |
将之前搭建的拷贝一份,在workers中把master也加上
# 在三台机器上执行
cp -r hadoop-3.3.3/ hadoop-3.3.3-bak
cd /usr/local/src/hadoop-3.3.3/etc/hadoop
vi workers
# workers内容如下
master
worker1
worker2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
修改配置文件
1. core-site.xml
<!-- 把多个NameNode的地址组装成一个集群,集群名字随便取 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-3.3.3/tmp</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2. hdfs-site.xml
<!-- namenode存储目录 --> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/src/hadoop-3.3.3/name</value> </property> <!-- datanode数据存储目录 --> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/src/hadoop-3.3.3/data</value> </property> <!-- journalnode数据存储目录 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/usr/local/src/hadoop-3.3.3/jn</value> </property> <!-- 完全分布式集群名称 --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!-- 集群中的namenode节点都有哪些 --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2,nn3</value> </property> <!-- namenode的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>master:9000</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>worker1:9000</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn3</name> <value>worker2:9000</value> </property> <!-- namenode的http通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>master:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>worker1:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn3</name> <value>worker2:9870</value> </property> <!-- 指定namenode元数据在journalnode上的存放位置,journalnode用于同步主备namenode之间的edits文件 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://master:8485;worker1:8485;worker2:8485/mycluster</value> </property> <!-- 访问代理类:client用于确定哪个NameNode为Active --> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用隔离机制时需要ssh秘钥登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
3. hadoop-env.sh
# 添加以下内容
export HDFS_JOURNALNODE_USER=root
- 1
- 2
4. 分发
cd hadoop-3.3.3/etc/hadoop/
scp hadoop-env.sh root@worker1:$PWD
scp hadoop-env.sh root@worker2:$PWD
scp core-site.xml root@worker1:$PWD
scp core-site.xml root@worker2:$PWD
scp hdfs-site.xml root@worker1:$PWD
scp hdfs-site.xml root@worker2:$PWD
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5. 启动测试
- 启动journalnode
# 在三台机器上执行
hdfs --daemon start journalnode
- 1
- 2
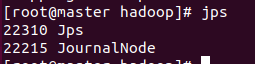
- 在nn1上格式化并启动
# 格式化
hdfs namenode -format
# 启动
hdfs --daemon start namenode
- 1
- 2
- 3
- 4
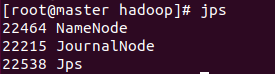
访问web界面,由于是手动模式所以需要手动切换为Active
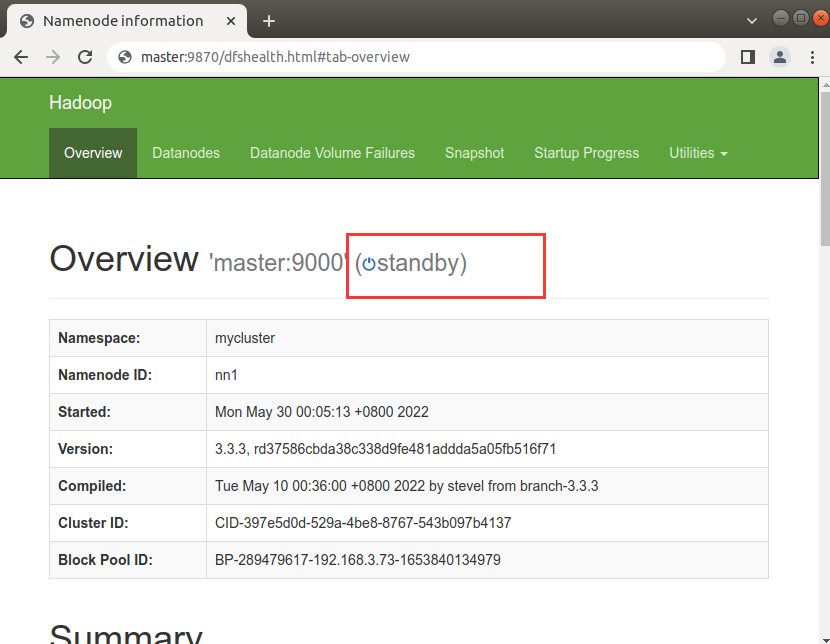
- 在nn2和nn3上,同步nn1的元数据信息
# 在nn2和nn3上执行
hdfs namenode -bootstrapStandby
- 1
- 2
- 启动nn2和nn3
# 在nn2和nn3上执行
hdfs --daemon start namenode
- 1
- 2
查看一下这两个节点的web页面
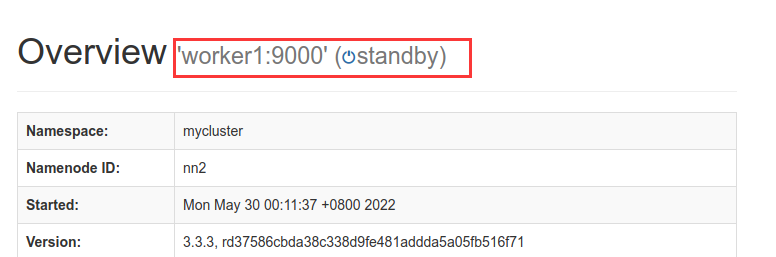
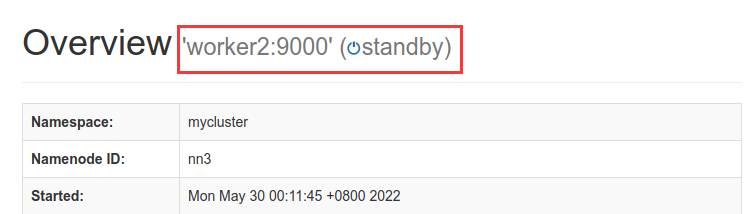
- 在所有节点启动datanode
# 在三台机器上执行
hdfs --daemon start datanode
- 1
- 2
- 将nn1切换为Active
hdfs haadmin -transitionToActive nn1
- 1

可以看出只能同时存在一个active的节点

- 查看是否Active
hdfs haadmin -getServiceState nn1
- 1

2. HDFS-HA自动模式
手动模式需要自己去切换namenode状态,太鸡肋了。一般都不会去用手动模式而是自动模式。
自动故障转移需要部署zookeeper,新增了ZKFailoverController(ZKFC)进程。
还需要安装一个包,以解决自动切换失败的问题。
yum install -y psmisc
- 1
集群规划
| master | worker1 | worker2 |
|---|---|---|
| NameNode JournalNode DataNode Zookeeper ZKFC | NameNode JournalNode DataNode Zookeeper ZKFC | NameNode JournalNode DataNode Zookeeper ZKFC |
1. hdfs-site.xml
在hdfs-site.xml中增加
<!-- 启用namenode故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
- 1
- 2
- 3
- 4
- 5
2. core-site.xml
在core-site.xml中增加
<!-- 指定要连接的zkServer地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,worker1:2181,worker2:2181</value>
</property>
- 1
- 2
- 3
- 4
- 5
3. hadoop-env.sh
在hadoop-env.sh中增加
export HDFS_ZKFC_USER=root
- 1
3. 分发
cd hadoop-3.3.3/etc/hadoop/
scp hadoop-env.sh root@worker1:$PWD
scp hadoop-env.sh root@worker2:$PWD
scp core-site.xml root@worker1:$PWD
scp core-site.xml root@worker2:$PWD
scp hdfs-site.xml root@worker1:$PWD
scp hdfs-site.xml root@worker2:$PWD
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4. 启动测试
- 启动zookeeper
# 三台机器执行
zkServer.sh start
- 1
- 2
- 初始化HA在zookeeper中的状态
hdfs zkfc -formatZK
- 1
- 启动hdfs集群
start-dfs.sh
- 1
在zookeeper cli中查看状态
# 打开zkCli
zkCli.sh
# 在cli中执行,查看谁是active节点
get -s /hadoop-ha/mycluster/ActiveStandbyElectorLock
- 1
- 2
- 3
- 4
- 5
nn2被选为了Active节点
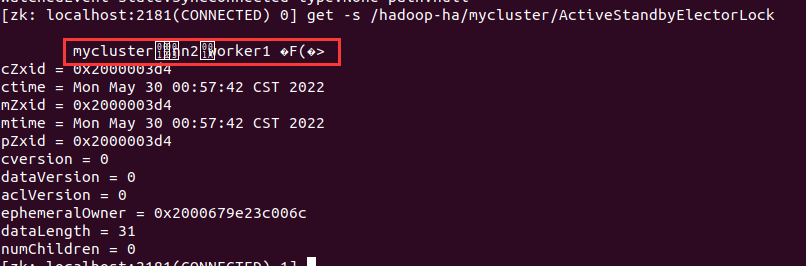
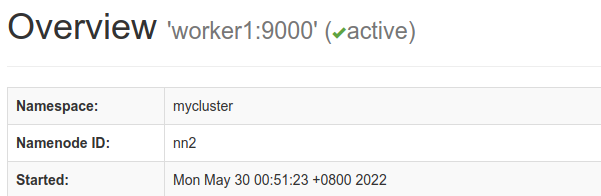
把nn2干掉试试看
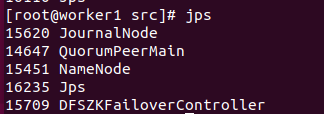
kill -9 15451
- 1
再次查看
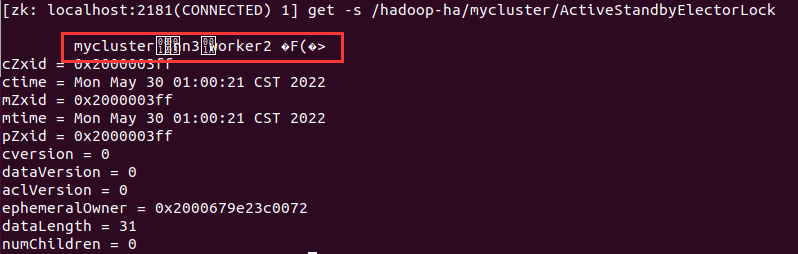
active自动切换到了nn3
二、YARN-HA 配置
和HDFS HA思想一样,配置多个ResouceManager,一个Active,其余Standby。
先启动的RM会将状态写入ZK,然后Active,其余Standby将继续循环轮询,一旦Active挂掉立马夺权篡位。
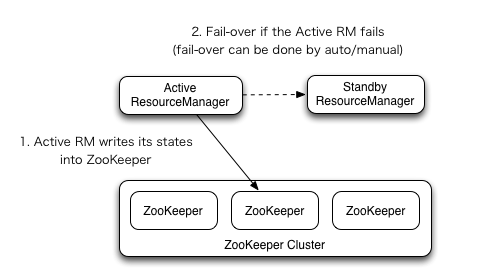
集群规划
| master | worker1 | worker2 |
|---|---|---|
| ResouceManager NodeManager Zookeeper | ResouceManager NodeManager Zookeeper | ResouceManager NodeManager Zookeeper |
1. yarn-site.xml
<!-- nodemanager获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 启用resourcemanager ha --> <property <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 声明resourcemanager的地址 --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn1</value> </property> <!-- 指定resourcemanager的逻辑列表 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2,rm3</value> </property> <!-- rm1的配置=-========= --> <!-- 指定rm1的主机名 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master</value> </property> <!-- 指定rm1的web端地址 --> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>master:8088</value> </property> <!-- rm2的配置=-========= --> <!-- 指定rm2的主机名 --> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>worker1</value> </property> <!-- 指定rm2的web端地址 --> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>worker1:8088</value> </property> <!-- rm3的配置=-========= --> <!-- 指定rm3的主机名 --> <property> <name>yarn.resourcemanager.hostname.rm3</name> <value>worker2</value> </property> <!-- 指定rm3的web端地址 --> <property> <name>yarn.resourcemanager.webapp.address.rm3</name> <value>worker2:8088</value> </property> <!-- 指定zookeeper集群地址 --> <property> <name>hadoop.zk.address</name> <value>master:2181,worker1:2181,worker2:2181</value> </property> <!-- 启用自动恢复 --> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!-- 指定resourcemanager的状态信息存储在zookeeper集群 --> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <!-- 忽略虚拟内存检查 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
2. 分发
cd /usr/local/src/hadoop-3.3.3/etc/hadoop
scp yarn-site.xml root@worker1:$PWD
scp yarn-site.xml root@worker2:$PWD
- 1
- 2
- 3
- 4
3. 启动测试
- 启动yarn
start-yarn.sh
- 1
保证每个节点都有这两个进程
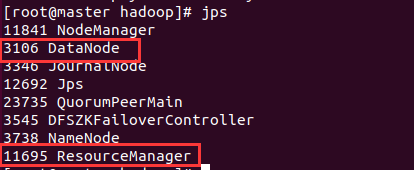
- 查看节点状态
yarn rmadmin -getServiceState rm1
- 1
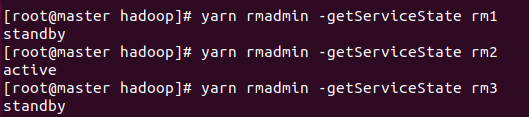
此时在浏览器访问master:8088和worker2:8088都会直接跳转到worker1:8088
- 干掉Active
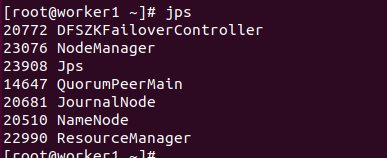
kill -9 22990
- 1
此时worker2【rm3】切换为了Active
~hadoop-ha集群搭建到此结束
总结
以上就是Hadoop-HA集群搭建的内容了,本文介绍了hadoop-ha集群的搭建在完全分布式的基础上更改的一些配置,可以看出配置文件的内容比较多,最终三台机器上的进程应该是这个样子的:
| master | worker1 | worker2 |
|---|---|---|
| NameNode JournalNode DataNode Zookeeper ZKFC ResourceManager NodeManager | NameNode JournalNode DataNode Zookeeper ZKFC ResourceManager NodeManager | NameNode JournalNode DataNode Zookeeper ZKFC ResourceManager NodeManager |

