
- 1vscode下调试ROS项目,节点调试,多节点调试,roslauch调试_roslauch debug
- 21441 :字典排序【C/C++/Java/Python】(字典)_按字典序映射到1至字符串种类数中的整数
- 3【MySQL】表的增删查改_数据库修改表中数据
- 4postgresql获取表结构,表名、表注释、字段名、字段类型及长度和字段注释_postgresql 表字段及长度
- 5c++ 三方库的构建与安装_nlohmann安装
- 6自动驾驶数据集汇总_nuscenes occ下载
- 7计算机毕业设计PHP基于微信小程序的校园跑腿系统(源码+程序+uni+lw+部署)_基于微信小程序的校园跑腿系统代码
- 8Java斐波那契查找知识点(含面试大厂题和源码)
- 9VScode断点调试ROS_vscode调试ros
- 10Python实现通讯录管理系统升级版本_tkinter设计通讯录
数字人项目 ER-NeRF 的使用和部署详细教程_er-nerf本地化部署
赞
踩
1. ER-NeRF简介
ER-NeRF(官方链接)是一个Talking Portrait Synthesis(对嘴型)项目。即:给一段某人说话的视频,再给定一段音频,经过该模型后处理后,可将原视频的嘴型与音频保持一致。
该模型的有优点:
- 可以做到实时响应。即模型比较小,处理速度快。
缺点:
- 需要对“要对嘴型的视频”进行训练。也就是每段视频对应一个模型
- 生成出的头部不够稳定。
2. ER-NeRF部署
ER-NeRF的环境要求:
- Pytroch 1.12
- CUDA 11.x (必须,否则pytorch3d相关的代码会报错)
部署步骤如下:
- 按顺序执行以下命令(一个一个执行)
# 这个知识针对pytorch的,本机的cuda不一定非要是11.6,但必须是11.x conda install cudatoolkit=11.6 -c pytorch # 安装pytorch pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --index-url https://download.pytorch.org/whl/cu116 # 安装pytorch3d,这一步一定要成功。否则后面处理数据会报错 pip install "git+https://github.com/facebookresearch/pytorch3d.git" # 安装tensorflow pip install tensorflow-gpu==2.8.0 # 安装一些必要的依赖 apt-get update apt install portaudio19-dev apt-get install ffmpeg # 克隆项目 git clone https://github.com/Fictionarry/ER-NeRF.git # 克隆项目,安装项目所需依赖 cd ER-NeRF pip install -r requirements.txt # 重新安装protobuf,使用3.20.3版本 pip uninstall protobuf pip install protobuf==3.20.3

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 下载模型。网盘链接地址,结构如下:
-- checkpoints # 将其放在 `~/.cache/torch/hub/checkpoints` 目录下(这部可以不做,源码也会自己下载)
-- data_utils # 将其下面的文件放在 `ER-NeRF/data_utils`对应目录下
-- face_parsing
-- face_tracking
- 1
- 2
- 3
- 4
3. 训练自己的数字人
如果就想用现有的模型(只有obama),可以跳转到第4节。
源码中提供了一个训练好的视频(obama)。若想训练自己的数字人模型,需要遵循以下步骤(以源码中提供的obama视频为例):
- 下载视频(要训练的视频片段),将其放在
data目录下。以data/<ID>/<ID>.mp4明明。例如:kunkun.mp4就放在ER-NeRF/data/kunkun/kunkun.mp4
wget https://github.com/YudongGuo/AD-NeRF/blob/master/dataset/vids/Obama.mp4?raw=true -O data/obama/obama.mp4
- 1
视频要求(必须满足):① 帧率:25FPS;② 每一帧都要是人物说话;③ 分辨率:512x512;④ 时长:1-5分钟;⑤ 人物背景要稳定。
- 使用
data_utils/process.py脚本处理视频
python data_utils/process.py data/<ID>/<ID>.mp4
- 1
这一步耗时较长,且容易出错(前面环境没配好就会导致某步出错,找出相应的环境配置,配好就行)。process.py包含多个任务,每个任务会生成若干文件,放在data/<ID>/*下面。可以根据对应的文件是否生成或日志来判断该任务是否正常完成:
- task 1:分离视频。生成
aud.wav文件。若报错,通常是ffmpeg问题。 - task 2:生成一些音频数据,
aud.npy文件。若报错,一般是protobuf版本问题。 - task 3:提取视频中的每帧图像。生成
ori_imgs/XXX.jpg文件,会有很多jpg文件。 - task 4:分割人像(语义分割)。生成
parsing/XX.png文件,会有很多png文件。 - task 5:提取背景图像。生成
bc.jpg文件。是人物的背景图片。 - task 6:分割出身体部分与生成Ground Truth图片。生成
gt_imgs/XXX.jpg和torso_imgs/XXX.png(只有躯干没有人脸的图片)。 - task 7:获取人脸各个点位的坐标。生成
ori_imgs/XXX.lms。 - task 8:获取人脸跟踪数据,这步要训练一个追踪模型,会很慢。生成
track_params.pt文件。这部报错通常是pytorch3d的问题,注意cuda版本。 - task 9:生成
transformers_train.json和transforms_val.json。
如果某个任务报错,可以配置环境后使用:
python data_utils/process.py data/<ID>/<ID>.mp4 --task <taskId>来重试。例如(重试任务2):python data_utils/process.py data/obama/obama.mp4 --task 2
-
将生成的
aud.npy复制一份,改名aud_ds.npy(源码好像有点问题,所以要这么做)。 -
使用OpenFace生成
<ID>.csv文件。具体步骤:① 下载OpenFace(Windows版本链接);② 解压文件,打卡里面的OpenFaceOffline.exe;③ Record里只勾选Record AUs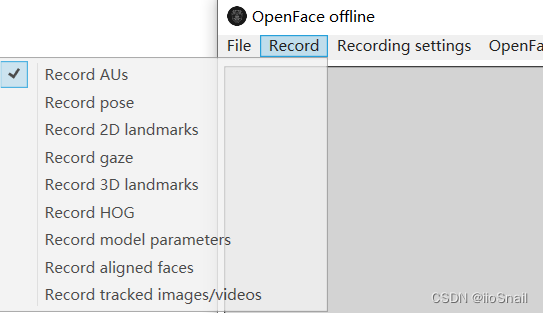 ;④ 打开文件,之后就开始运行。⑤ 等待运行结束,会在
;④ 打开文件,之后就开始运行。⑤ 等待运行结束,会在./processd文件夹中生成<ID>.csv文件,将其更名为au.csv。⑥ 将其放在data/<ID>/文件夹下。 -
训练模型,依次执行以下代码:
# 命令1:训练模型
python main.py data/obama/ --workspace trial_obama/ -O --iters 100000
# 命令2:在命令1完成后,再多训练“25000”次,微调一下lips
python main.py data/obama/ --workspace trial_obama/ -O --iters 125000 --finetune_lips --patch_size 32
- 1
- 2
- 3
- 4
trial_obama是工作路径,也就是生成的模型存放路径。运行完后会生成trial_obama文件夹,文件树如下:
-- checkpoints/ # 模型文件
├── ngp_ep0013.pth # 第13个epoch的文件(会保存最后两个epoch的文件)
├── ngp_ep0014.pth
└── ngp.pth # 最终的模型文件
-- log_ngp.txt # 训练过程中的日志文件
-- opt.txt # 训练时传的启动参数
-- result # 训练结果文件
├── ngp_ep0014_depth.mp4
└── ngp_ep0014.mp4 # 可以下载这个文件看效果
-- run/ngp/events.out.xxxxx # 训练过程中的数据
-- validation
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
上面两个命令运行完后,运行下面:
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --head_ckpt trial_obama/checkpoints/ngp.pth --iters 200000
- 1
trial_obama/checkpoints/ngp.pth为上面生成的最终模型文件
4. 生成数字人视频
当模型生成出来后,就可以用我们自己的语音来生成视频了。需要遵循以下3步骤:
- 上传音频,提取音频数据(生成对应的
npy文件)
例如:
python data_utils/deepspeech_features/extract_ds_features.py --input /root/demo2.wav
- 1
将demo2.wav更改为你的音频文件。执行结束后,会在同目录生成
demo2.npy文件
- 执行模型推理,生成对口型后的视频文件。不过生成的视频没有声音。
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test --test_train --aud /root/demo2.npy
- 1
最后的
/root/demo2.npy就是第一步生成的npy文件
- 将音频和视频合并起来。
ffmpeg -i /root/ER-NeRF/trial_obama_torso/results/ngp_ep0028.mp4 -i /root/demo2.wav -c:v copy -c:a aac -strict experimental /root/output.mp4
- 1
ngp_ep0028.mp4是第二步生成的视频(日志里可以看到在哪)。
demo2.wav是上传的音频。
/root/output.mp4是你想要输出文件的路径
5. 其他数字人模型比较
| 模型名称 | 推理速度 | 单独训练 | 优点 | 缺点 |
|---|---|---|---|---|
| video-retalking | 慢 | 无需单独训练 | 1. 部署简单 2.无需训练,可直接对任意视频使用 3.项目成熟,兼容性强 4. 包含视频处理部分,无需自行处理视频 | 1. 推理速度慢,无法做到实时。 2.效果不稳定,有些视频效果很差 |
| ER-NeRF | 快 | 需要自主训练模型 | 1. 模型小,推理速度快,可满足实时要求 2. 嘴型效果较好,但头部晃动严重 | 1. 项目不成熟,为论文源码,坑比较多 2. 兼容性较差,对部署环境要求严格 3. 数据处理与训练耗时较长,5分钟的视频大约需要1天 |
| Wav2Lip | - | - | 1. 项目成熟 | 1. 项目太老(4年前的) |
常见错误
- ValueError: Found array with 0 sample(s) (shape=(0, 2)) while a minimum of 1 is required by NearestNeighbors.:
Traceback (most recent call last): File "data_utils/process.py", line 417, in <module> extract_background(base_dir, ori_imgs_dir) File "data_utils/process.py", line 112, in extract_background nbrs = NearestNeighbors(n_neighbors=1, algorithm='kd_tree').fit(fg_xys) File "/root/miniconda3/lib/python3.8/site-packages/sklearn/base.py", line 1152, in wrapper return fit_method(estimator, *args, **kwargs) File "/root/miniconda3/lib/python3.8/site-packages/sklearn/neighbors/_unsupervised.py", line 175, in fit return self._fit(X) File "/root/miniconda3/lib/python3.8/site-packages/sklearn/neighbors/_base.py", line 498, in _fit X = self._validate_data(X, accept_sparse="csr", order="C") File "/root/miniconda3/lib/python3.8/site-packages/sklearn/base.py", line 605, in _validate_data out = check_array(X, input_name="X", **check_params) File "/root/miniconda3/lib/python3.8/site-packages/sklearn/utils/validation.py", line 967, in check_array raise ValueError( ValueError: Found array with 0 sample(s) (shape=(0, 2)) while a minimum of 1 is required by NearestNeighbors.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
原因:视频中的部分帧没有人脸。一般容易出现在视频开头或结尾。可以通过查看生成的parsing文件夹的图片进行确认。详见issus

