
- 1AI人工智能与医疗:技术驱动下的医疗革命_医疗领域人工智能的原理
- 2naiveui 上传图片遇到的坑 Upload_navie图片上传
- 3NLP(六十三)使用Baichuan-7b模型微调人物关系分类任务_firefly-baichuan-7b
- 4MinIO单机版部署及常用功能使用_minio单机部署
- 5渗透测试实战-BurpSuite 使用入门_如何使用burpsuite进行命令注入漏洞测试
- 6hadoop大数据开发基础_大数据,Hadoop生态详解
- 7【论文阅读】【yolo系列】YOLO-Pose的论文阅读
- 8PyTorch神经网络的可视化踩坑
- 9[华为OD]C卷 给定一个数组,数组中的每个元素代表该位置的海拔高度 山脉的个数 200
- 10跑通基于YOLOv5的旋转框目标检测_yolov5旋转目标检测代码
【机器学习】R语言实现随机森林、支持向量机、决策树多方法二分类模型_r语言支持向量机预测模型
赞
踩
暑期简单学习了机器学习理论知识,当时跟着B站咕泡老师学的,内容讲得蛮详细,实例代码、资料都比较全面,但是学校Python课程开设在这学期,所以用Python进行数据分析、建模等不是很熟悉,所以决定用之前学过的R语言来实现机器学习。R语言的相关包也都比较完善,所以想分享一下近期使用R语言实现分类预测建模遇到的问题及解决方法,并且会系统地分享一下几种常见ML二分类方法实现及代码。
数据预处理
我使用的是GEO数据库中的乳腺癌转移相关的基因表达谱数据(GSE2034、GSE1456),前面一个数据集作为训练集,后面一个数据集作为测试集。
我先使用MATLAB对mat数据文件进行读入,接着进行t检验,筛选出有极显著差异(P<0.01)的基因,对两个数据集的基因作交集(并删除重复基因)得到765个特征,以及一个类标签(1表示预后好,2表示预后差)。
z-score标准化
z-score适用于数据分布过于凌乱、数据的最大值与最小值未知,或者数据中存在过多的离群值的情况。在进行聚类分析、因子分析、主成分分析等多元统计分析时,通常采用这种方法。
在R语言中,可以使用scale函数实现z-score标准化。
- GSE_train <- read.csv("train_data.csv") #以GSE2034为训练集,这里已为预处理后的差异表达数据以及预后label数据
- GSE_train <- as.data.frame(GSE_train)
- GSE_train[,2:766] <- scale(GSE_train[,2:766]) #z-score标准化,第一列为类标签不需要标准化
- View(GSE_train)
-
- GSE_test <- read.csv("test_siggene.csv") #以GSE1456为测试集,这里已为预处理后的差异表达数据以及预后label数据
- GSE_test <- as.data.frame(GSE_test)
- GSE_test[,2:766] <- scale(GSE_test[,2:766]) #z-score标准化
- View(GSE_test)
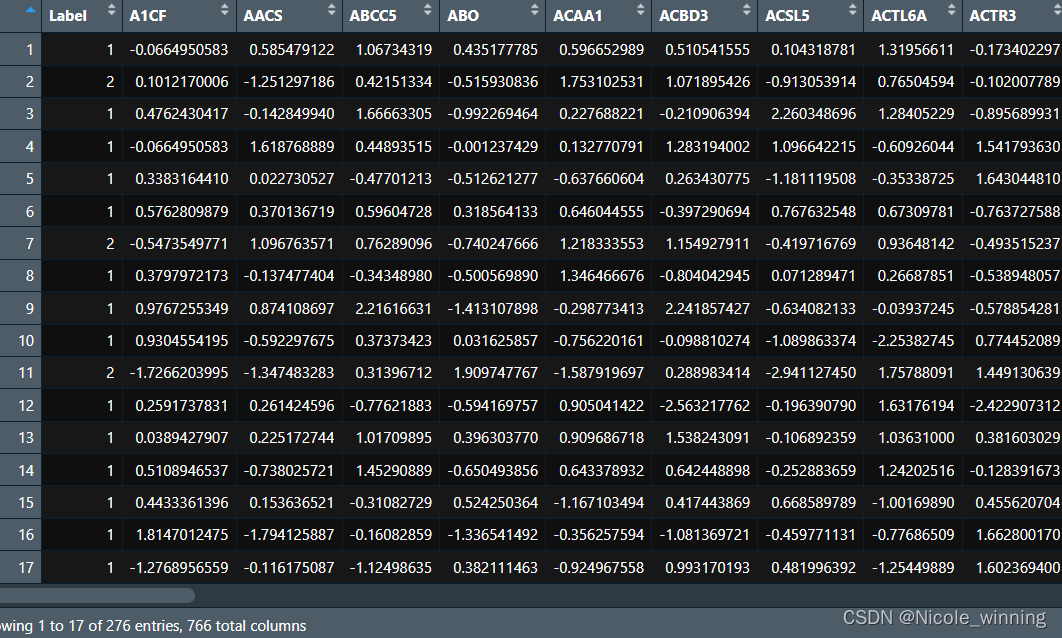
下图展示的是GSE2034的标准化后的数据
SMOTE处理样本不平衡问题
在这里我注意到,预后标签1和2的数量分布不平衡。在机器学习中,训练数据中不同类别的样本数量分布不均衡可能会导致在训练过程中过多关注数量较多的类别,忽略数量较少的类别,从而使得预测准确率降低。
重采样方法主要有两种,一种是欠采样,即减少数量较多类别的样本数量;另一种是过采样,即增加数量较少类别的样本数量。两种方法各有优劣,这里我使用过采样方法。
| 1(预后好) | 2(预后差) |
| 134 | 59 |
比较讨厌的是,我在使用R语言DMwR包来加载SMOTE函数时,发现这个包已经不存在了。在我搜索后,发现它是在DMwR2包里面的smotefamily中,所以可以安装DMwR2包来使用smote函数。需要注意的是,更新后的SMOTE算法与之前的使用方式不太相同(参数设置不同),可在安装加载smotefamily后,使用help(SMOTE)来参看具体用法。
- library(DMwR2) #加载相关包
- library(smotefamily)
-
- set.seed(123)
- sub <- sample(nrow(GSE_train),nrow(GSE_train)*0.7) #这里不能将所有训练集都进行过采样,取70%或其它
- train <- GSE_train[sub,]
- smote_data <- SMOTE(train[,-1], train[,1]) #使用DMwR2包的SMOTE函数进行过采样
- newdata <- smote_data$data #检查经过SMOTE处理后的类别分布
- table(newdata$class)
进行SMOTE平衡后,样本分布为:
| 1(预后好) | 2(预后差) |
| 134 | 118 |
随机森林(Random Forest)
模型训练和预测
- library(randomForest) #加载相关包
- library(pROC)
- #模型训练
- set.seed(123) #设置随机种子数,确保以后再执行代码时可以得到一样的结果
- newdata$class <- as.factor(newdata$class) #因变量得为因子型
-
- train.forest <- randomForest(class ~ ., data = newdata,ntree = 200) #用平衡后的数据训练
- train.forest
查看模型的结果:
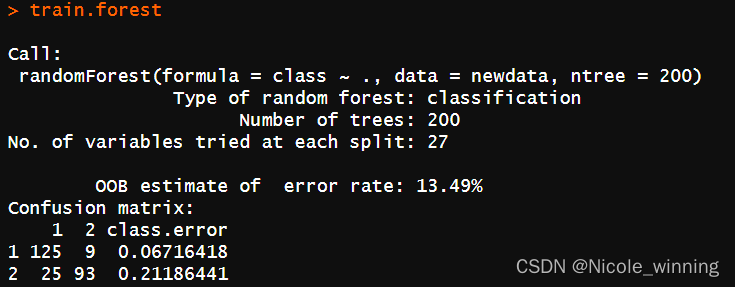
生成树时没有用到的样本点所对应的类别可由生成的树估计,与其真实类别比较即可得到袋外预测(out-of-bag,OOB)误差,即OOB estimate of error rate,可用于反映分类器的错误率。此处为为13.49%。
Confusion matrix比较了预测分类与真实分类的情况,class.error代表了错误分类的样本比例:1组(预后好)的134个样本中125个正确分类,2组(预后差)的118个样本中93个正确分类。
分别查看在训练集GSE2034和测试集GSE1456上的预测结果:
- train_probs <- predict(train.forest, GSE_train, type = "prob")[, "1"]
- test_probs <- predict(train.forest, GSE_test, type = "prob")[, "1"]
-
- #计算训练集和测试集的AUC并可视化
- train_roc <- roc(GSE_train$Label, train_probs, levels = c("1", "2"))
- test_roc <- roc(GSE_test$Label, test_probs, levels = c("1", "2"))
- plot(train_roc, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),grid.col=c("green", "red"), max.auc.polygon=TRUE,auc.polygon.col="skyblue", print.thres=TRUE,main='RF训练模型ROC曲线')
- plot(test_roc, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),grid.col=c("green", "red"), max.auc.polygon=TRUE,auc.polygon.col="skyblue", print.thres=TRUE,main='RF预测模型ROC曲线')

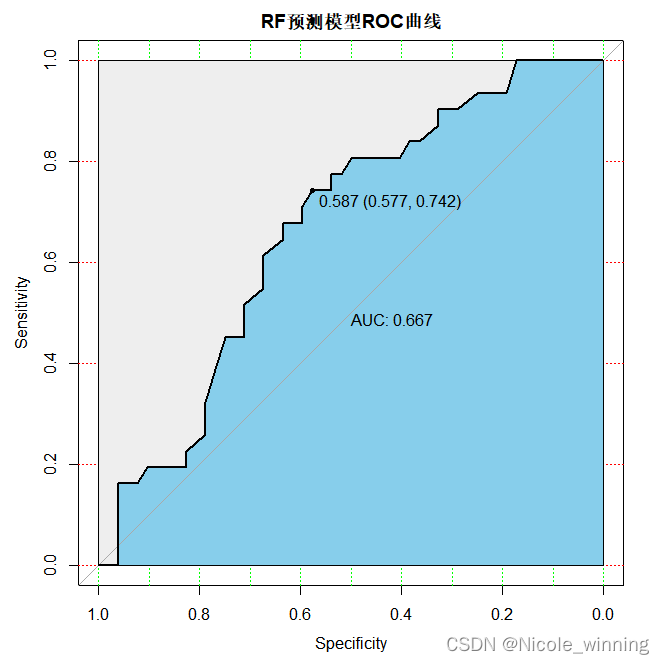
模型评估
常见的评估指标除了AUC(ROC曲线下面积),还有F1 score值,准确率,召回率等,在这里,我还计算了accuracy = 113/151 = 0.7483
| 预测1 | 预测2 | |
| 实际1 | 112(TN) | 6(FP) |
| 实际2 | 32(FN) | 1(TP) |
变量重要性
- importance_gene <- train.forest$importance
- head(importance_gene)
-
- varImpPlot(train.forest, n.var = min(30, nrow(train.forest$importance)),
- main = 'Top 30 genes- variable importance') #作图展示 top30 重要的Genes
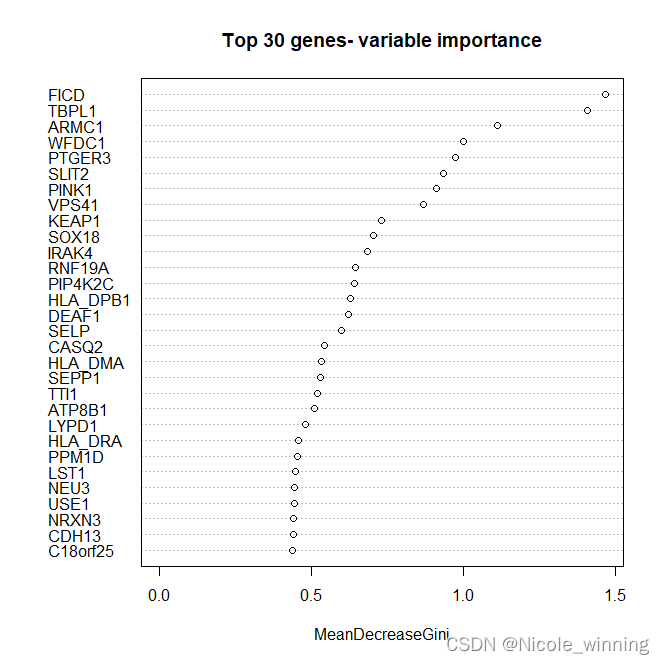
对于上述基因,可以做基因功能注释或基因本体分析(GO),以分析这些基因与乳腺癌是否有关系。
支持向量机(Support Vector Machines)
代码编写与上述类似,这里直接展示模型完整代码。
模型训练和预测
- #安装并加载相关包
- library(e1071)
- library(pROC)
-
- svm_model <- svm(class~.,data = newdata,kernel = "radial")
- summary(svm_model)
-
- ##训练集和测试集预测及AUC曲线
- train_pred <- predict(svm_model,GSE_train)
- test_pred <- predict(svm_model,GSE_test)
- train_roc <- roc(GSE_train$Label, as.numeric(train_pred), levels = c("1", "2"))
- test_roc <- roc(GSE_test$Label, as.numeric(test_pred), levels = c("1", "2"))
- plot(train_roc, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),grid.col=c("green", "red"), max.auc.polygon=TRUE,auc.polygon.col="skyblue", print.thres=TRUE,main='SVM训练模型ROC曲线')
- plot(test_roc, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),grid.col=c("green", "red"), max.auc.polygon=TRUE,auc.polygon.col="skyblue", print.thres=TRUE,main='SVM预测模型ROC曲线')
SVM有四种核函数,在这里,我分别使用四种核函数来建模以确定错误率最小的核函数。其中,线性核函数(linear)错误率为10.87%,径向基核函数(radial)错误率为10.51%,多项式核函数(polynomial)错误率为12.32%,神经网络核函数(sigmoid)错误率为19.20%,所以选择径向基核函数(radial)来建模。 (代码如下)
- svm_model <- svm(class~.,data = newdata,kernel = "radial") #通过改变kernel核函数来建模
- summary(svm_model)
-
- svm_pred <- predict(svm_model,GSE_train,decision.values = TRUE) #模型预测
- tab <- table(Predicted = svm_pred,Actual = GSE_train$Label) #展示二联表
- tab
- 1-sum(diag(tab))/sum(tab) #计算错误率
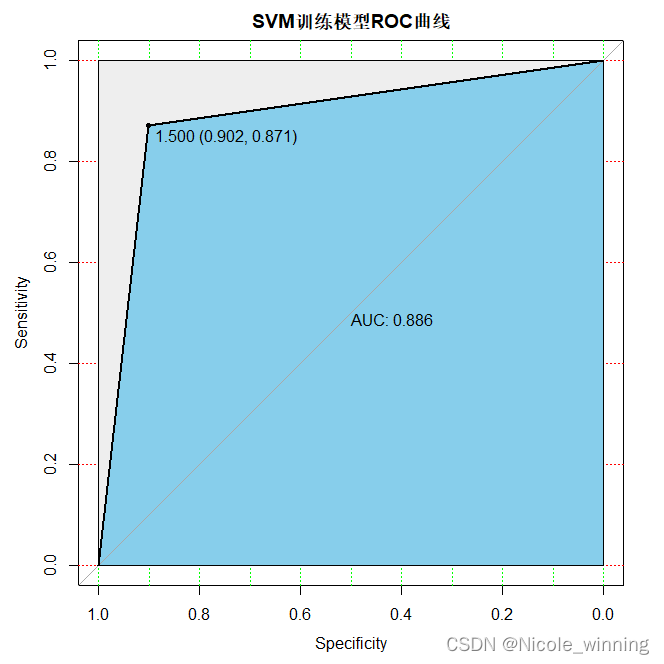

模型评估
SVM的AUC较随机森林的降低,模型的预测准确性降低,此外,SVM的Accuracy = 110/151 =0.7285
| 预测1 | 预测2 | |
| 实际1 | 110(TN) | 8(FP) |
| 实际2 | 33(FN) | 0(TP) |
决策树(Decision Tree)
模型训练和预测
- #加载相关包
- library(rpart)
- library(tibble)
- library(bitops)
- library(rattle)
- library(rpart.plot)
- library(RColorBrewer)
- library(ROCR)
-
- #构建决策树
- set.seed(123)
- newdata$class <- as.factor(newdata$class)
- dt <- rpart(class ~.,data = newdata)
- summary(dt)
-
- #训练集和测试集预测
- train.pred <- predict(dt,newdata = GSE_train,type = "class")
- test.pred <- predict(dt,newdata = GSE_test,type = "class")
- train_roc <- roc(GSE_train$Label, as.numeric(train.pred), levels = c("1", "2"))
- test_roc <- roc(GSE_test$Label, as.numeric(test.pred), levels = c("1", "2"))
-
- plot(train_roc, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),grid.col=c("green", "red"), max.auc.polygon=TRUE,auc.polygon.col="skyblue", print.thres=TRUE,main='DT训练模型ROC曲线')
- plot(test_roc, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),grid.col=c("green", "red"), max.auc.polygon=TRUE,auc.polygon.col="skyblue", print.thres=TRUE,main='DT预测模型ROC曲线')


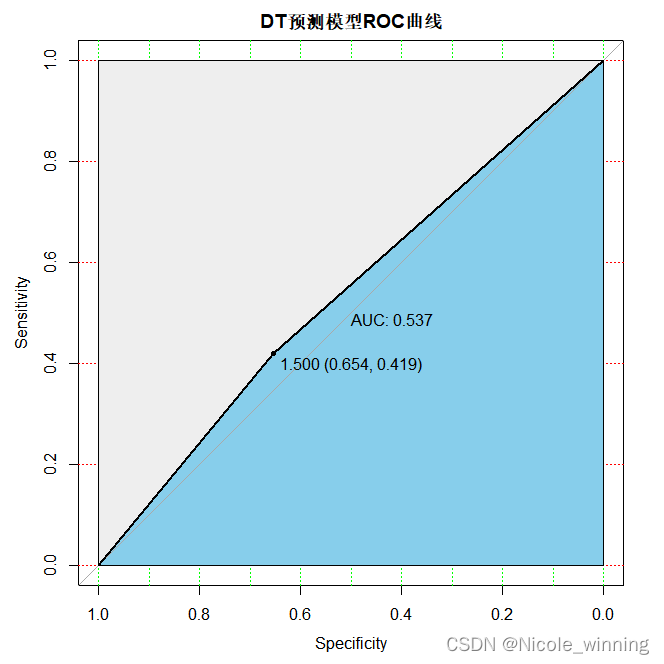
模型评估
从上述ROC曲线可以看出,决策树的预测准确性最差。再计算一下准确度,Accuracy = 96/151 =0.6358,效果相较前两种比较差。
| 预测1 | 预测2 | |
| 实际1 | 83(TN) | 35(FP) |
| 实际2 | 20(FN) | 13(TP) |
- fancyRpartPlot(dt) #看一下目前的决策树
- plotcp(dt) #画出xerror和cp值与树的节点个数的关系


可在此基础上对决策树进行剪枝,选出最优决策树,以期达到更好分类预测的效果。
总结
机器学习建模分析后,还要进行调参或交叉验证以提高模型的预测率,就是所谓的“炼丹”。评估模型也应该用多种指标,包括F1 score,Accuracy(准确率),召回率,绘制ROC曲线等。此外,机器学习是一个“黑盒子”模型,在得到模型预测结果后,还应该深一步进行生物学解释,由于目前我的生信分析能力还不足,后续学习到了再分享~

