
- 1这个AI换衣项目也太惊艳了吧,看完我整个人都不好了!_ootdiffusion window
- 2Visual Studio Code使用
- 3C语言 | Leetcode C语言题解之第50题Pow(x,n)
- 4不带头结点的单链表
- 527.统一网关Gateway-路由断言工厂
- 6辅警招聘笔试考什么_应聘辅警笔试都考什么
- 7雷达杂波的基础知识_地杂波
- 8计算机毕业设计hadoop+spark+hive新能源汽车数据分析可视化大屏 汽车推荐系统 新能源汽车推荐系统 汽车爬虫 汽车大数据 机器学习 大数据毕业设计 深度学习 知识图谱 人工智能
- 9Project推荐节选|几个超级有用的学术网站和好玩的github(附带网站!)
- 10java oracle 事务_Oracle 事务控制语句
改进YOLOv8:添加CBAM注意力机制(涨点明显)_yolov8添加cbam
赞
踩
1、计算机视觉中的注意力机制
计算机视觉中的注意力机制是一种聚焦于局部信息的机制,其基本思想是让系统学会忽略无关信息而关注重点信息。这种机制在图像识别、物体检测和人脸识别等任务中都发挥了重要作用。
注意力机制的实现方法有多种,其中包括空间注意力模型、通道注意力模型、空间和通道混合注意力模型等。这些模型可以将图像中的关键信息提取出来,并通过抑制无用信息来提高模型的性能。在计算机视觉中,注意力机制被广泛应用于各种任务,如目标检测、图像分类、人脸识别等。
通过引入注意力机制,计算机视觉系统可以更加高效地处理图像数据,减少计算资源的浪费,同时提高模型的性能和准确性。在未来,随着深度学习技术的不断发展,注意力机制在计算机视觉领域的应用前景将会更加广阔。
1.1 CBAM:通道注意力和空间注意力的集成者
CBAM(Convolutional Block Attention Module)是一种注意力机制,它结合了通道注意力和空间注意力来提高卷积神经网络的性能。通道注意力模块通过计算每个通道的重要性,以区分不同通道之间的特征。空间注意力模块则计算每个像素在空间上的重要性,以更好地捕捉图像中的空间结构。
论文题目:《CBAM: Convolutional Block Attention Module》
论文地址: https://arxiv.org/pdf/1807.06521.pdf
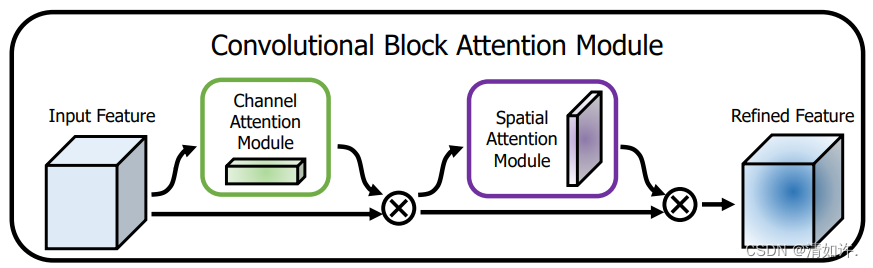
上图可以看到,CBAM包含CAM(Channel Attention Module)和SAM(Spartial Attention Module)两个子模块,分别进行通道和空间上的Attention。这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
CBAM的工作原理如下:
- 通道注意力模块:通过在通道维度上对输入特征图进行最大池化和平均池化,然后将这两个池化结果输入到一个全连接层中,最后输出一个通道注意力权重向量。这个权重向量可以用来加权输入特征图的每个通道,以增强重要的通道特征并抑制不重要的通道特征。
- 空间注意力模块:类似于通道注意力模块,空间注意力模块也是通过对输入特征图进行操作来计算每个像素的重要性。它通常使用全局平均池化来获取每个像素的特征向量,然后通过一个全连接层来输出每个像素的权重。这些权重可以用于加权输入特征图的每个像素,以强调图像中的重要区域并抑制不重要的区域。
通过将通道注意力和空间注意力模块串联起来,可以得到一个完整的CBAM模块,用于插入到卷积神经网络中以提升模型性能。CBAM可以显著提高计算机视觉任务的性能,例如目标检测、图像分类和语义分割等。
2.Yolov8加入CBAM
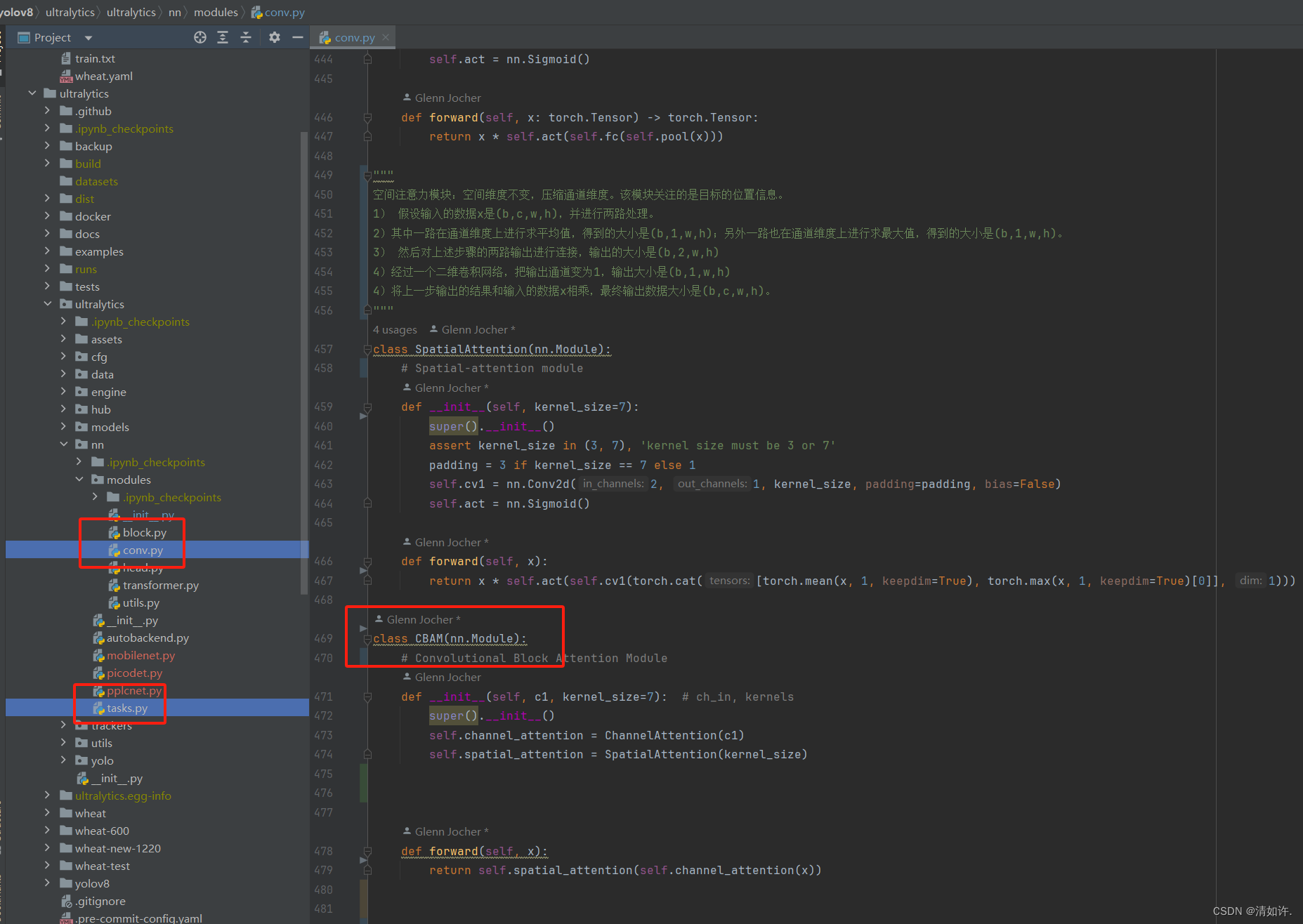
2.1 CBAM加入cony.py中(相当于yolov5中的common.py)
"""
通道注意力模型: 通道维度不变,压缩空间维度。该模块关注输入图片中有意义的信息。
1)假设输入的数据大小是(b,c,w,h)
2)通过自适应平均池化使得输出的大小变为(b,c,1,1)
3)通过2d卷积和sigmod激活函数后,大小是(b,c,1,1)
4)将上一步输出的结果和输入的数据相乘,输出数据大小是(b,c,w,h)。
"""
class ChannelAttention(nn.Module):
# Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet
def __init__(self, channels: int) -> None:
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return x * self.act(self.fc(self.pool(x)))
"""
空间注意力模块:空间维度不变,压缩通道维度。该模块关注的是目标的位置信息。
1) 假设输入的数据x是(b,c,w,h),并进行两路处理。
2)其中一路在通道维度上进行求平均值,得到的大小是(b,1,w,h);另外一路也在通道维度上进行求最大值,得到的大小是(b,1,w,h)。
3) 然后对上述步骤的两路输出进行连接,输出的大小是(b,2,w,h)
4)经过一个二维卷积网络,把输出通道变为1,输出大小是(b,1,w,h)
4)将上一步输出的结果和输入的数据x相乘,最终输出数据大小是(b,c,w,h)。
"""
class SpatialAttention(nn.Module):
# Spatial-attention module
def __init__(self, kernel_size=7):
super().__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
class CBAM(nn.Module):
# Convolutional Block Attention Module
def __init__(self, c1, kernel_size=7): # ch_in, kernels
super().__init__()
self.channel_attention = ChannelAttention(c1)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
return self.spatial_attention(self.channel_attention(x))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
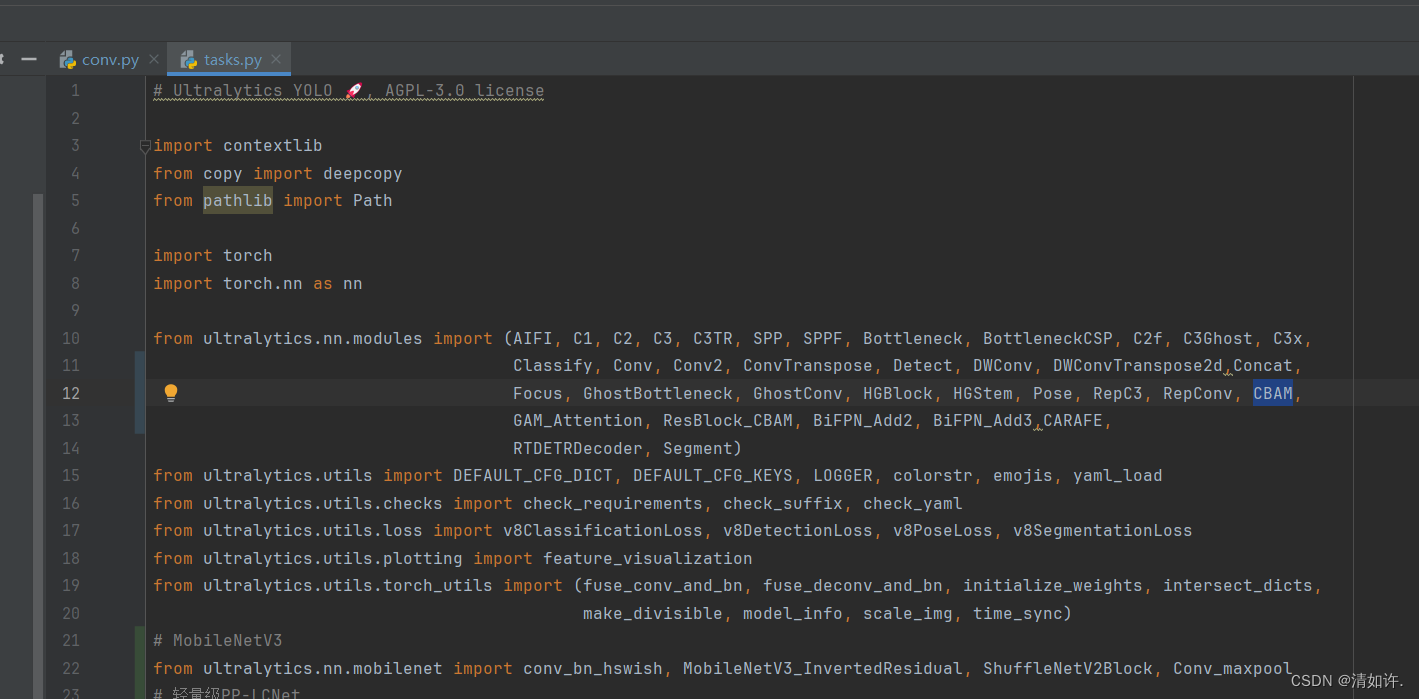
2.2 CBAM加入tasks.py中(相当于yolov5中的yolo.py)
from ultralytics.nn.modules import (C1, C2, C3, C3TR, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x, Classify,
Concat, Conv, ConvTranspose, Detect, DWConv, DWConvTranspose2d, Ensemble, Focus,
GhostBottleneck, GhostConv, Segment,CBAM, GAM_Attention , ResBlock_CBAM)
- 1
- 2
- 3
如图所示:
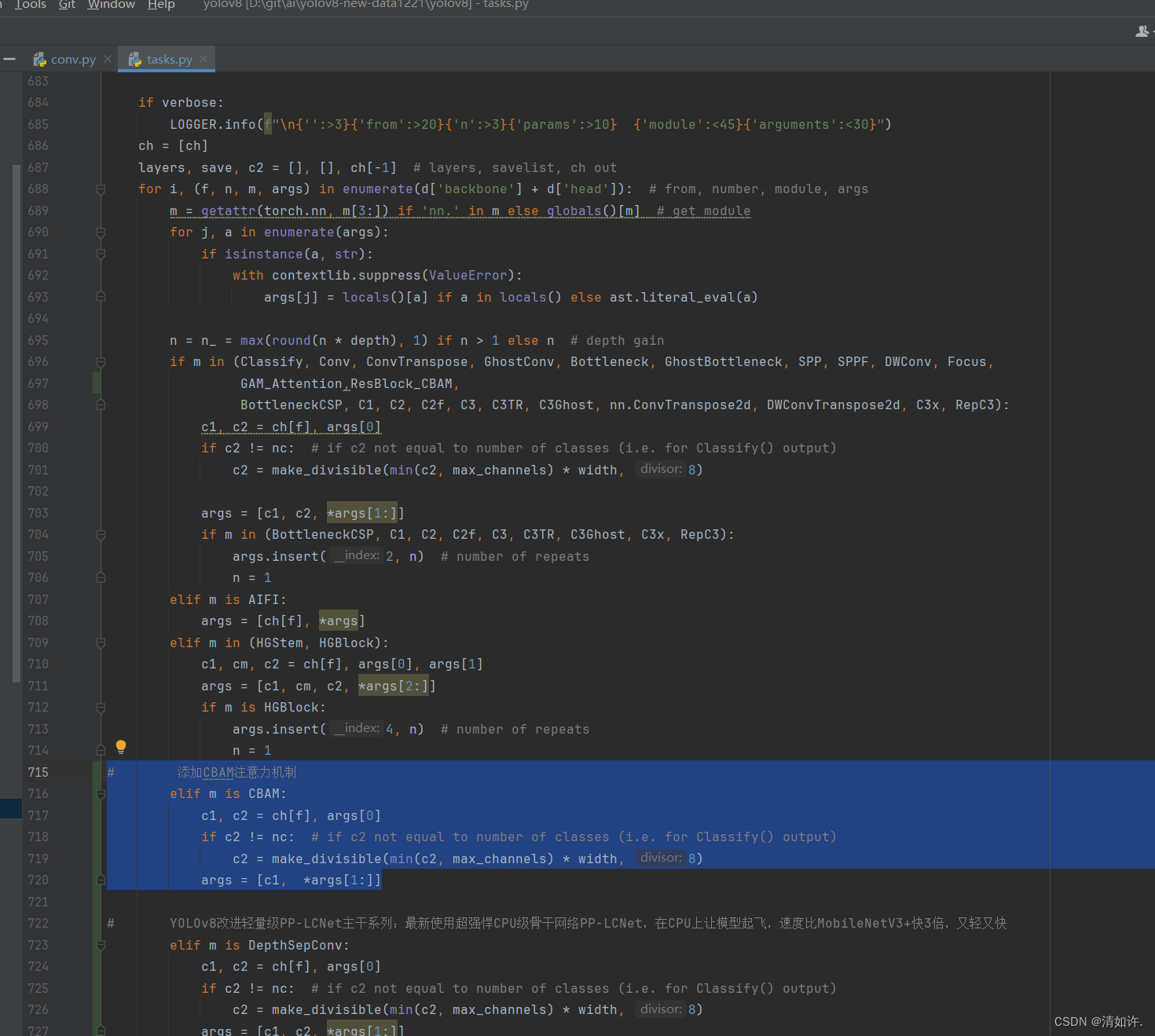
2.4 还是在tasks.py,def parse_model(d, ch, verbose=True):函数中
# 添加CBAM注意力机制
elif m is CBAM:
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, *args[1:]]
- 1
- 2
- 3
- 4
- 5
- 6
如图所示:
2.5 CBAM修改对应yaml
CBAM加入yolov8
将yolov8.yaml复制一份,改为yolov8n-CBAM.yaml
路径:ultralytics/ultralytics/cfg/models/v8/yolov8n-CBAM.yaml
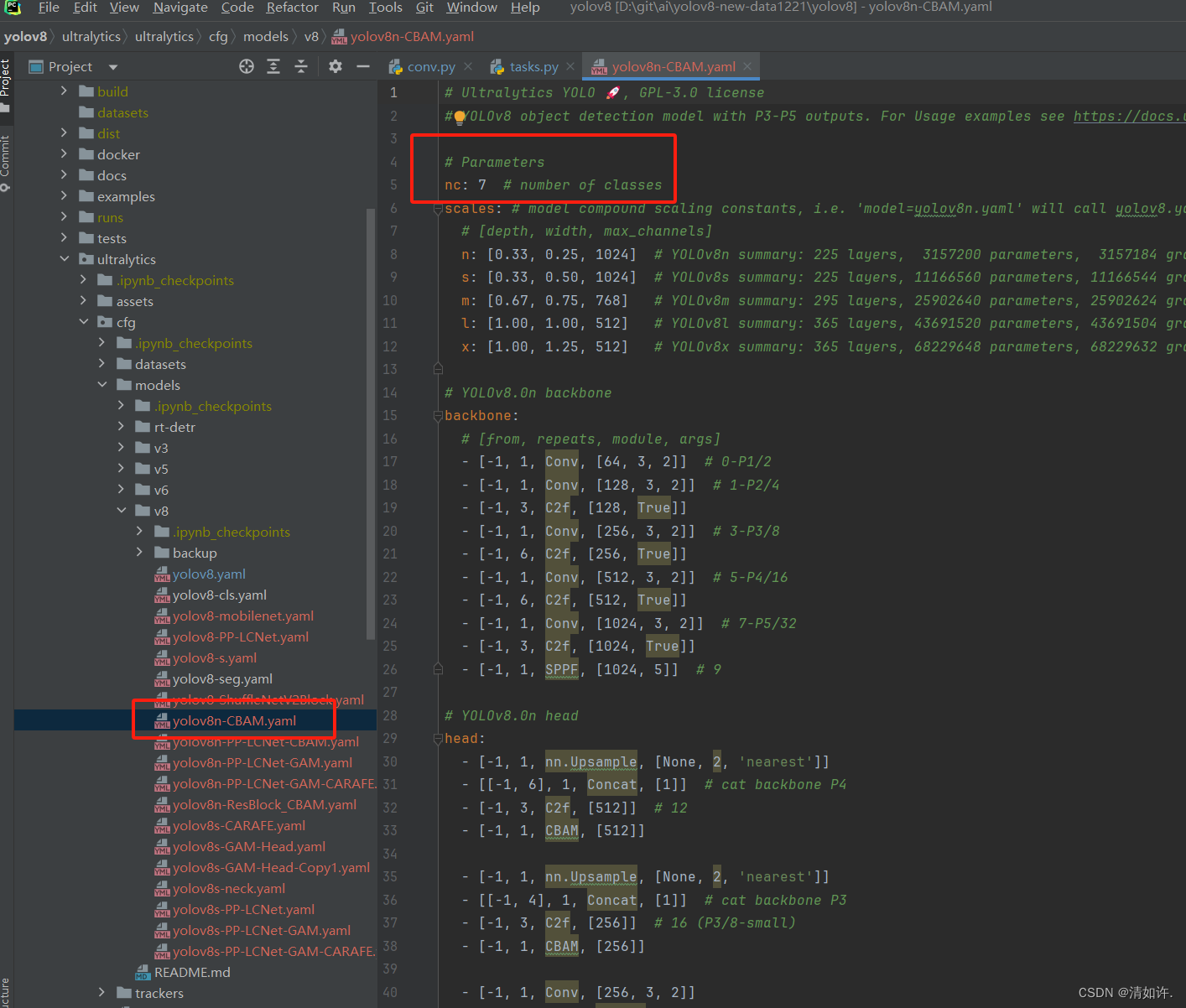
yolov8n-CBAM.yaml
# Ultralytics YOLO 本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/558477Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

