
- 1Win10更新后BUG——任务栏点不动、卡死、加载不出来解决办法_windows10资讯和兴趣打不开
- 2【YOLOv8】Yolov5和Yolov8网络结构的分析与对比_yolov5与yolov8
- 3杀毒软件误删文件了怎么办?如何恢复被杀毒软件删除的文件_ok.dll被杀毒软件删了在解压一次可以吗
- 4初识图形学
- 5信息学竞赛常用函数/模板
- 6mysql -c_mysql客户端的Windows C/C++编程实现(★firecat推荐★)
- 7学生信息管理系统的数据库设计MySQL_mysql学生管理系统数据库
- 8C++比较运算符解释_c++a=b(a,c)
- 9[论文阅读]-0.MICCAI 2023 医学图像分割开源论文_医学图像分类论文miccai
- 10Java 使用multipartFile对象解析Execl_multipartfile解析excel
ECCV2020优秀论文汇总|涉及点云处理、3D检测识别、三维重建、立体视觉、姿态估计、深度估计、SFM等方向...
赞
踩
点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达

前言
ECCV2020的oral和spotlight名单已经发布,与往年相比,accepted paper list中增加了很多3D方向相关的作品,实在值得鼓舞。
工坊对这些优秀作品进行了跟进,今天和大家分享下ECCV2020中3D方向相关的oral和spotlight,涉及点云处理、3D检测识别、三维重建、立体视觉、姿态估计、深度估计、SFM等~
点云相关
1、Quaternion Equivariant Capsule Networks for 3D Point Clouds
文章链接:https://arxiv.org/pdf/1912.12098.pdf
文章主要提出了一种用于处理点云的3D胶囊网络结构,可用于3D识别与方向估计。
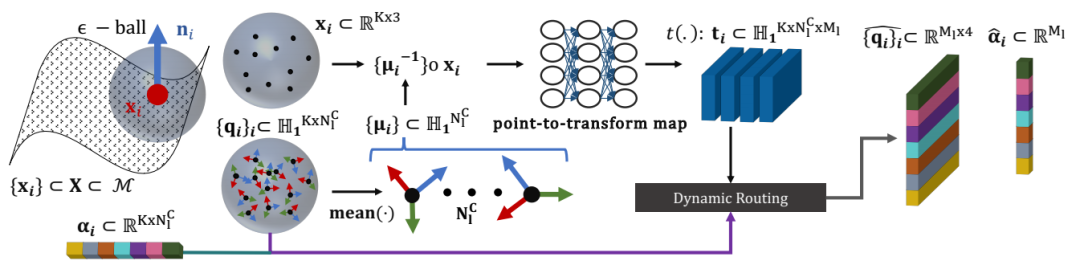
2、Intrinsic Point Cloud Interpolation via Dual Latent Space Navigation
文章链接:https://arxiv.org/pdf/2004.01661v1.pdf
论文提出了一种基于学习的方法,用于对表示为点云的3D形状进行插值,该方法可用于保留固有的形状属性。


3、PointMixup: Augmentation for Point Clouds
Paper暂未开放
4、PointContrast: Unsupervised Pretraining for 3D Point Cloud Understanding
Paper暂未开放
三维重建
1、Ladybird: Deep Implicit Field Based 3D Reconstruction with Sampling and Symmetry
Paper未开放
2、Deep Fashion3D: A Dataset and Benchmark for 3D Garment Reconstruction from Single-view Images
文章链接:https://arxiv.org/pdf/2003.12753.pdf
论文主要开源了单视图图像重建3D服装的数据集


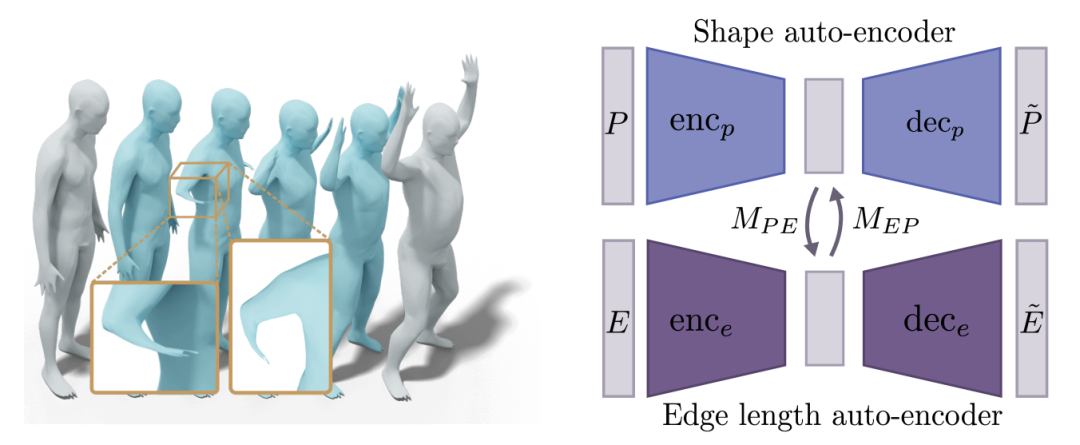
3、Combining Implicit Function Learning and Parametric Models for 3D Human Reconstruction
Paper暂未开放
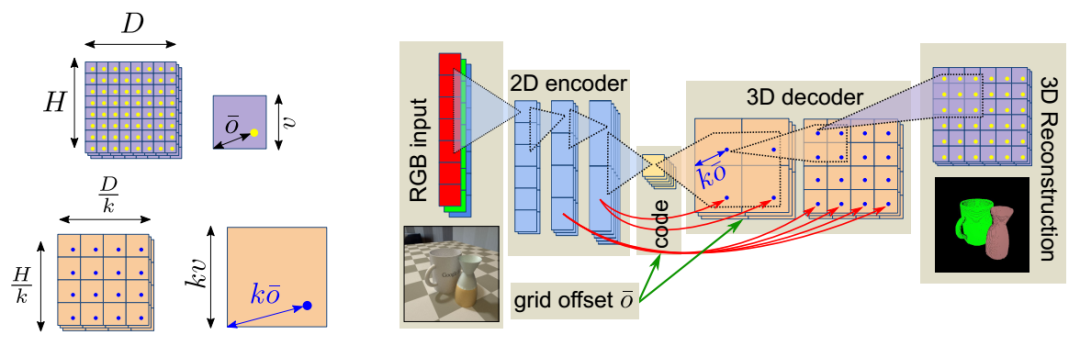
4、Coherent full scene 3D reconstruction from a single RGB image
文章链接:https://arxiv.org/pdf/2004.12989.pdf
深度学习技术的进步允许最近的工作在仅输入一个RGB图像的情况下重建单个对象的形状。基于此任务的通用编码器-解码器体系结构,论文提出了三个扩展:(1)以物理上正确的方式将本地2D信息传播到3D体积;(2)混合3D体积表示,它可以建立翻译等变模型,同时在不占用过多内存的情况下对精细的对象详细信息进行编码;(3)专为捕获整体物体几何形状而设计的重建损失。此外,论文还调整模型以解决从单个图像重建多个对象的艰巨任务。

5、Deep Reflectance Volumes: Relightable Reconstructions from Multi-View Photometric Images
Paper暂未开放
场景识别
1、ReferIt3D: Neural Listeners for Fine-Grained 3D Object Identification in Real-World Scenes
Paper暂未开放
3D检测与识别
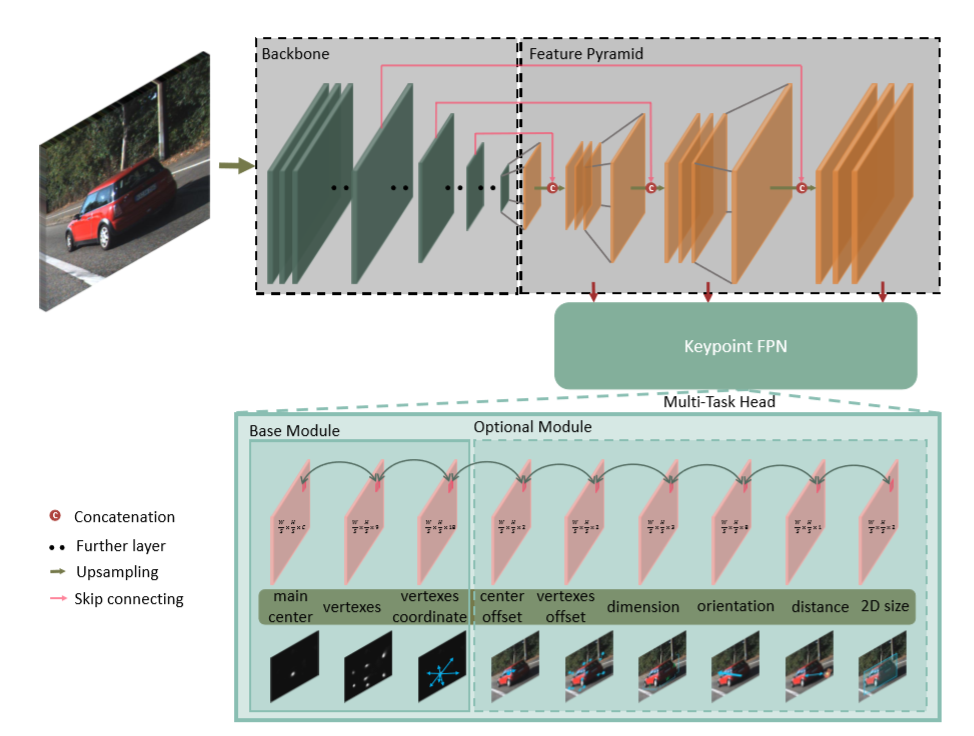
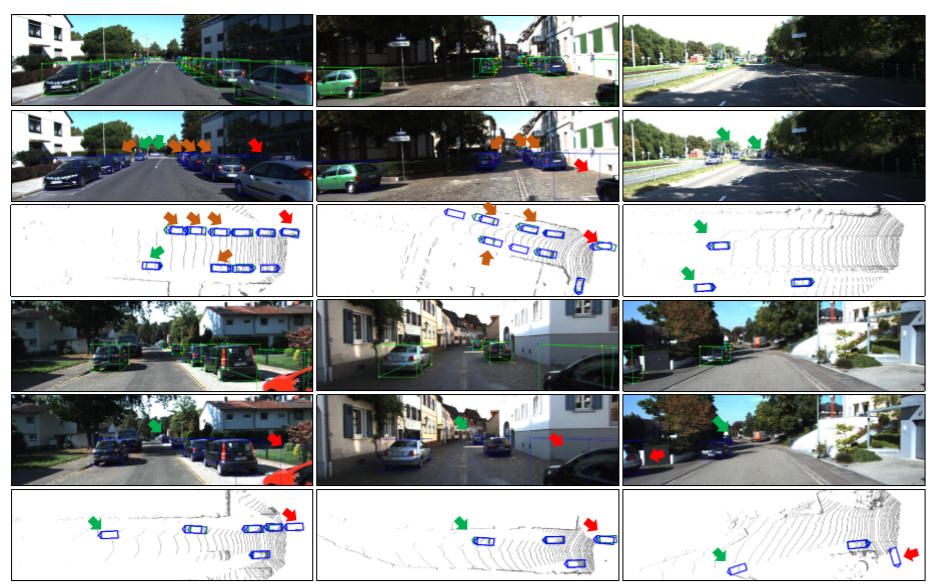
1、RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving
文章链接:https://arxiv.org/pdf/2001.03343.pdf
源码链接:https://github.com/Banconxuan/RTM3D(即将开源)
论文提出了一种有效且准确的单目3D检测框架,文中的方法预测图像空间中3D边界框的九个透视关键点,然后利用3D和2D透视的几何关系恢复3D空间中的尺寸,位置和方向。通过这种方法,即使关键点的估计非常嘈杂,也可以稳定地预测对象的属性,这使得能够以较小的架构获得快速的检测速度。该方法是第一个用于单目图像3D检测的实时系统,同时在KITTI基准上达到了SOTA。
姿态估计
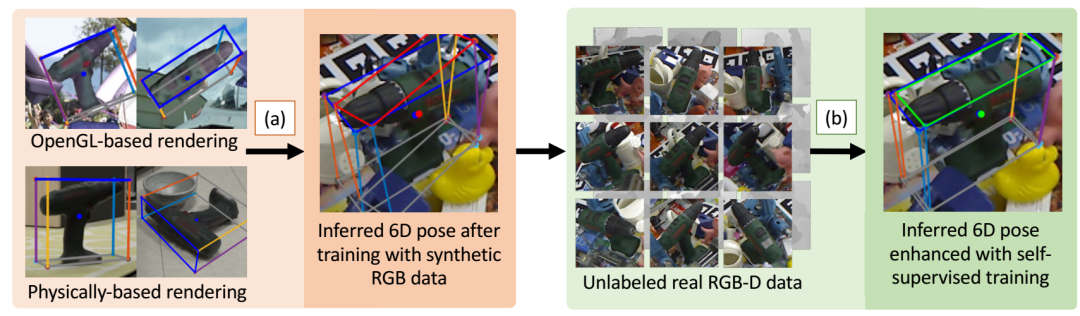
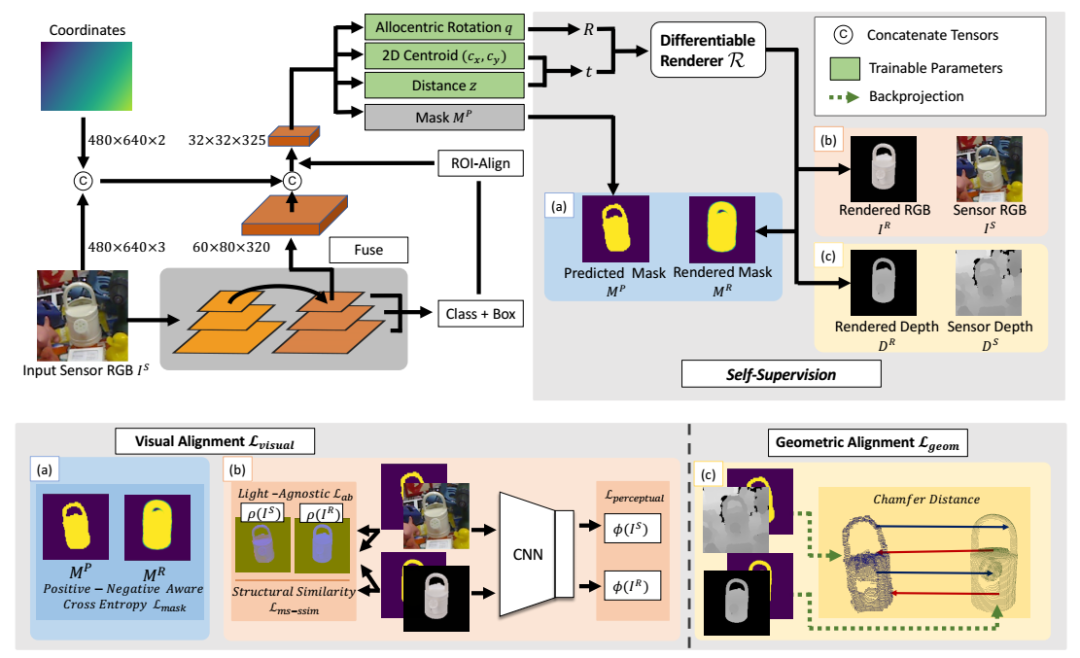
1、Self6D: Self-Supervised Monocular 6D Object Pose Estimation
文章链接:https://arxiv.org/pdf/2004.06468.pdf
针对深度学习单目姿态估计下的数据难获取这一缺点,论文提出了通过自监督学习方式进行单目6D姿态估计的方法,该方法消除了对带有注释的真实数据的需求。
2、End-to-End Estimation of Multi-Person 3D Poses from Multiple Cameras
文章链接:https://www.researchgate.net/publication/340644214_End-to-End_Estimation_of_Multi-Person_3D_Poses_from_Multiple_Cameras
论文提出了一种从多个摄像机视图估计多个人的3D姿势的方法。与之前需要基于嘈杂和不完整的2D姿势估计来建立跨视图对应关系的工作相反,论文提出了一种直接在 3 D空间运行的端到端解决方案。
3、Multi-person 3D Pose Estimation in Crowded Scenes Based on Multi-View Geometry
Paper未开放
4、Towards Part-aware Monocular 3D Human Pose Estimation: An Architecture Search Approach
Paper未开放
5、Adaptive Computationally Efficient Network for Monocular 3D Hand Pose Estimation
Paper未开放
深度估计
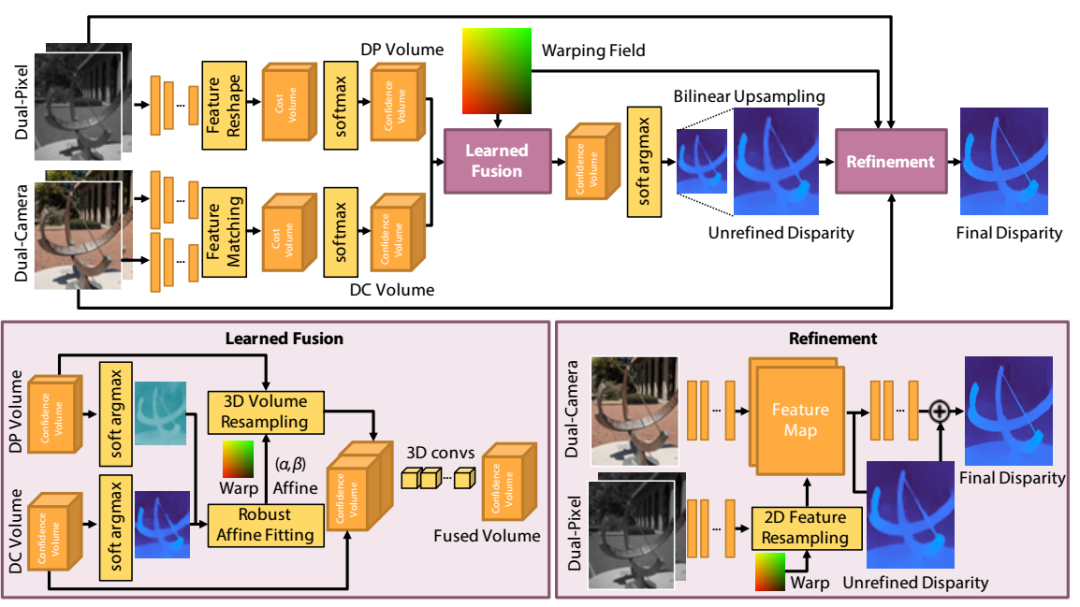
1、Du^2Net: Learning Depth Estimation from Dual-Cameras and Dual-Pixels
文章链接:https://arxiv.org/pdf/2003.14299v1.pdf
计算方式的stereo已经达到了很高的准确性,但是由于存在遮挡,重复的纹理以及沿边缘的对应误差,会降低stereo效果。论文提出了一种基于神经网络的深度估计新方法,该方法将双摄像头的stereo与双像素传感器的stereo相结合,这在消费类摄像头上越来越普遍。网络使用新颖的架构来融合这两个信息源,并且可以克服纯双目立体声匹配的上述限制。论文的方法提供了具有锐利边缘的密集深度图,这对于计算摄影应用(如合成浅景深或3D照片)至关重要。目前进行的实验和与最先进方法的比较表明,论文的方法比以前的工作有了实质性的改进。

立体视觉
1、Learning Stereo from Single Images
Paper未开放
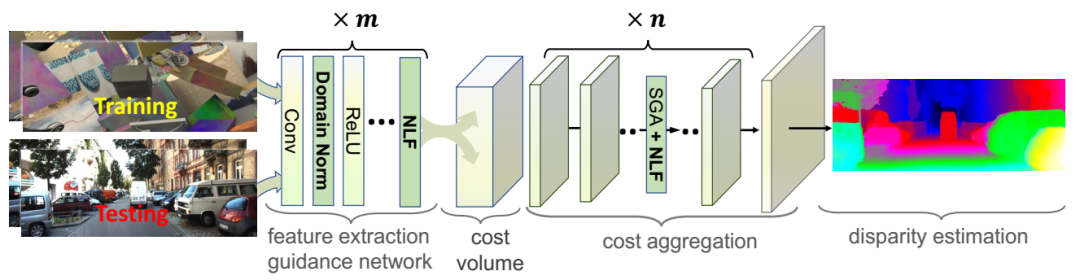
2、Domain-invariant Stereo Matching Networks
文章链接:https://arxiv.org/pdf/1911.13287.pdf
代码链接:https://github.com/feihuzhang/DSMNet
由于大量的领域差异(例如颜色,照明,对比度和纹理),最新的立体匹配网络难以推广到新的环境,本文旨在设计一种可以很好推广到陌生场景下的立体匹配网络(DSMNet)。

SFM相关
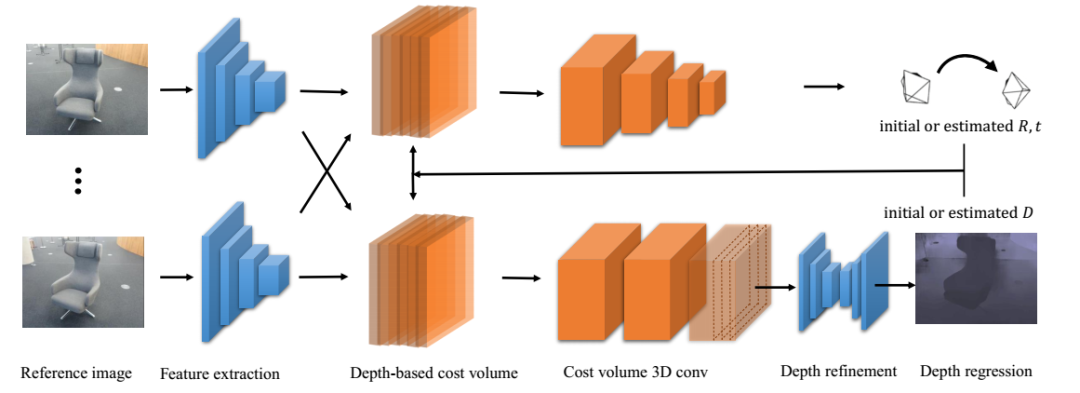
1、DeepSFM: Structure From Motion Via Deep Bundle Adjustment
文章链接:https://arxiv.org/pdf/1912.09697.pdf

2、Privacy Preserving Structure-from-Motion
Paper未开放
其它作品
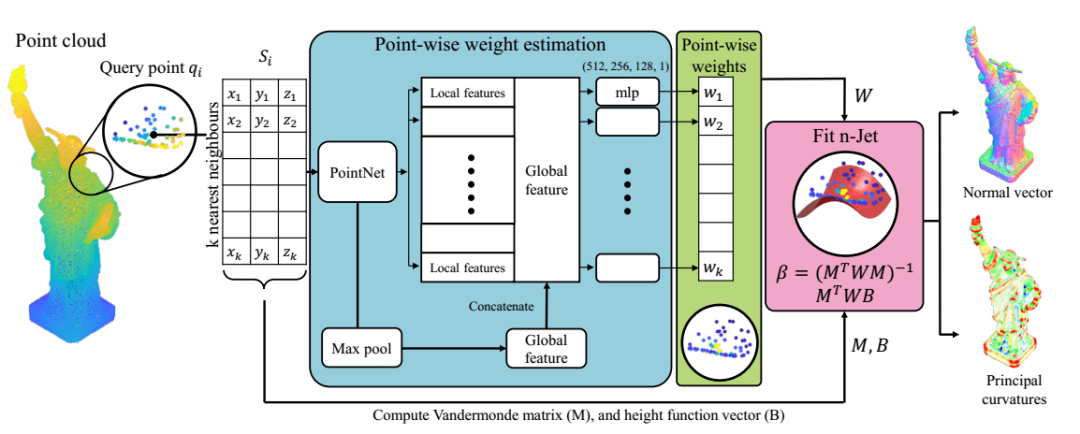
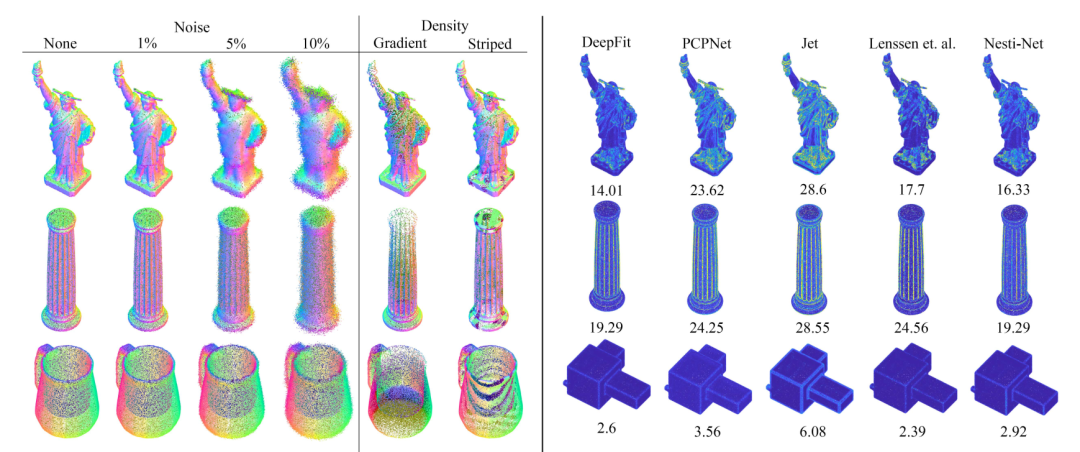
1、DeepFit: 3D Surface Fitting by Neural Network Weighted Least Squares
文章链接:https://arxiv.org/pdf/2003.10826.pdf
论文提出了一种用于非结构化3D点云的表面拟合方法,称为DeepFit的方法并入了一个神经网络,以学习加权最小二乘多项式曲面拟合的逐点权重。
2、DeepHandMesh: Weakly-supervised Deep Encoder-Decoder Framework for High-fidelity Hand Mesh Modeling from a Single RGB Image
Paper未开放
3、Mask2CAD: 3D Shape Prediction by Learning to Segment and Retrieve
Paper未开放
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「计算机视觉工坊」公众号后台回复:深度学习,即可下载深度学习算法、3D深度学习、深度学习框架、目标检测、GAN等相关内容近30本pdf书籍。
下载2
在「计算机视觉工坊」公众号后台回复:计算机视觉,即可下载计算机视觉相关17本pdf书籍,包含计算机视觉算法、Python视觉实战、Opencv3.0学习等。
下载3
在「计算机视觉工坊」公众号后台回复:SLAM,即可下载独家SLAM相关视频课程,包含视觉SLAM、激光SLAM精品课程。
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
觉得有用,麻烦给个赞和在看~ 

