
- 1Python pygame贪吃蛇小游戏 (200行完整代码+注释+可运行)_贪吃蛇py代码
- 2XILINX 7系列FPGA与SOC产品选型指南_赛灵思fpga选型手册
- 3训练集、验证集、测试集_sep是验证集
- 4欧科云链:比特币现货ETF后时代,链上数据揭示真实供需关系
- 5【正点原子Linux连载】第四十一章 Linux wifi驱动实验 摘自【正点原子】ATK-DLRK3568嵌入式Linux驱动开发指南_rtl8852原理图封装
- 6小程序Taro框架 自定义底部Tabbar,处理自定义Tab栏切换卡顿、闪烁_taro自定义tabbar
- 7android 图片闪光动画_fadein-Android-使用Alpha淡入淡出动画使图像闪烁
- 8hive学习(九)------lateral view,视图,索引_hive sql lateral view 性能
- 9企业内网开源OA服务器(办公自动化系统),搭建O2OA基于Linux(openEuler、CentOS8)_centos部署o2oa
- 10【翻译】How To Become A Blockchain Developer: Crash Course! 区块链开发指南!
如何使用共享GPU平台搭建LLAMA3环境(LLaMA-Factory)
赞
踩
0. 简介
最近受到优刻得的使用邀请,正好解决了我在大模型和自动驾驶行业对GPU的使用需求。UCloud云计算旗下的[Compshare](https://www.compshare.cn/?
ytag=GPU_lovelyyoshino_Lcsdn_csdn_display)的GPU算力云平台。他们提供高性价比的4090 GPU,按时收费每卡2.6元,月卡只需要1.7元每小时,并附带200G的免费磁盘空间。暂时已经满足我的使用需求了,同时支持访问加速,独立IP等功能,能够更快的完成项目搭建。

而且在使用后可以写对应的博客,可以完成500元的赠金,完全可以满足个人对GPU的需求。

1. 账号注册与使用
优刻得平台的注册还是很方便的。普通用户走这个注册渠道就可以,如果是有额外需求的可以联系官方客服来提供制定需求的GPU资源,暂时其实4090已经完全够我们个人使用了。
在注册完毕后,我们的界面长这样,通过点击创建资源即可完成资源环境的创建

点进去后,我们可以看到大多数常用的大模型环境已经安装适配完毕。我们点击即可使用这些快速配置好的环境,不需要额外安装CUDA这些比较麻烦的环境配置,注册即可使用。
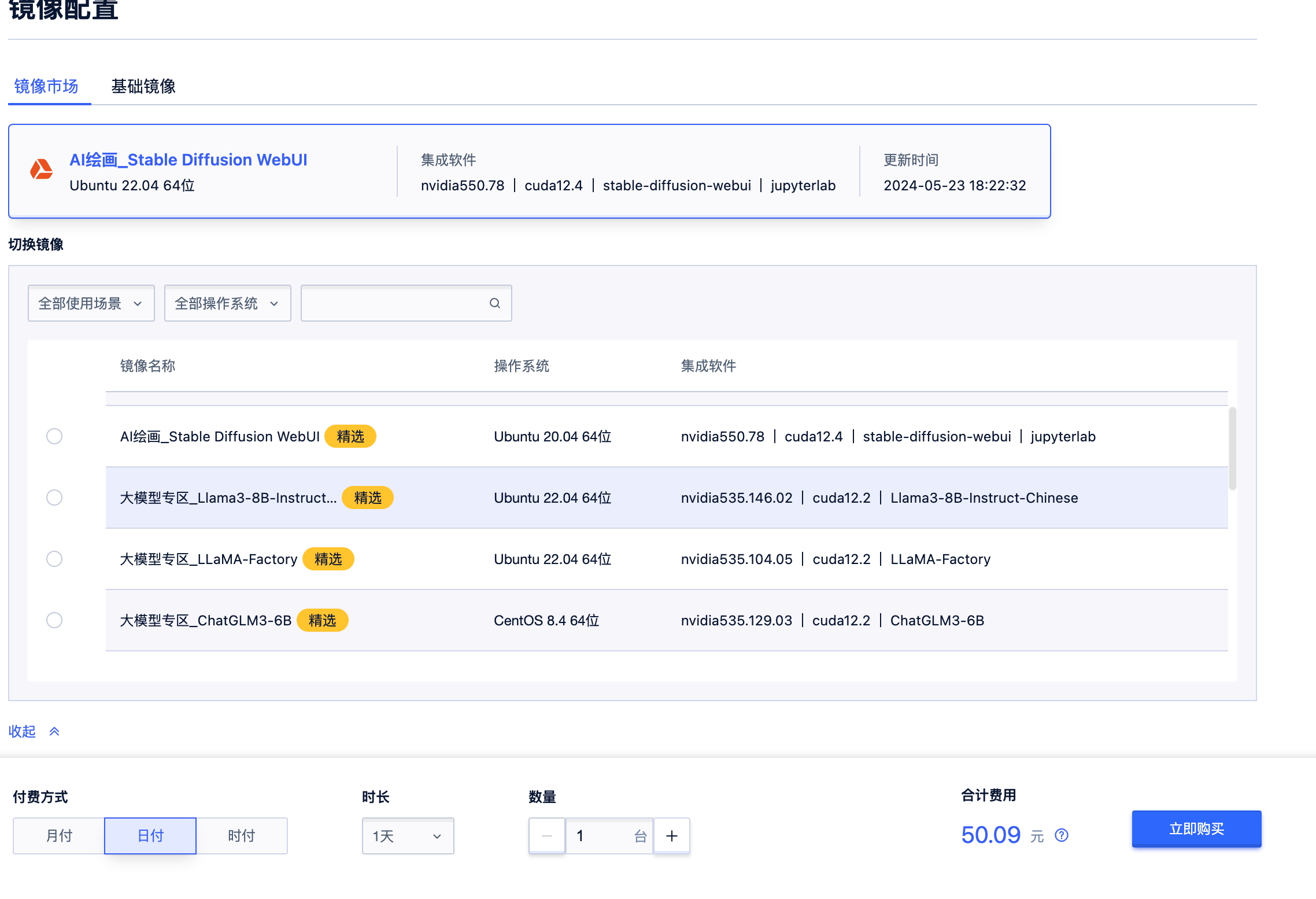
2. 如何搭建LLAMA3
之前我们曾经深度解析过LLaMA-Factory这个项目,优刻得平台也已经集成了,这对于我而言非常友善。我完全可以省下大量的环境配置步骤,并专心于项目的二次开发和使用。

相比于隔壁的autoDL而言,这确实能节省很多时间。独立IP也可以非常便捷的完成ssh远程连接(现挖个坑,后面再说)。这里我们使用的LLaMA-Factory支持很多模型的便捷整合,并可以支持市面上绝大多数的微调或者全量的方法。
2.1 如何设置 LLaMA-Factory
首先我们在Github上拉取对应的项目,并安装制定的环境
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .[torch,metrics]
- 1
- 2
- 3
如果需要隔离环境并自己手动安装环境可以尝试(必须要执行pip install -e .[torch,metrics])
# Create and activate a virtual environment
python -m venv llama-env
source llama-env/bin/activate
# Install required packages by LlaMA-Factory
pip install -r requirements.txt
pip install -e .[torch,metrics]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.2 准备数据
LLaMA-Factory 在 data 文件夹中提供了多个训练数据集,您可以直接使用它们。如果您打算使用自定义数据集,请按照以下方式准备您的数据集。
请将您的数据以 json 格式进行组织,并将数据放入 data 文件夹中。LLaMA-Factory 支持以 alpaca 或 sharegpt 格式的数据集。
alpaca 格式的数据集应遵循以下格式:
[
{
"instruction": "user instruction (required)",
"input": "user input (optional)",
"output": "model response (required)",
"system": "system prompt (optional)",
"history": [
["user instruction in the first round (optional)", "model response in the first round (optional)"],
["user instruction in the second round (optional)", "model response in the second round (optional)"]
]
}
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
sharegpt 格式的数据集应遵循以下格式:
[ { "conversations": [ { "from": "human", "value": "user instruction" }, { "from": "gpt", "value": "model response" } ], "system": "system prompt (optional)", "tools": "tool description (optional)" } ]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在 data/dataset_info.json 文件中提供您的数据集定义,并采用以下格式:
对于 alpaca 格式的数据集,其 dataset_info.json 文件中的列应为:
"dataset_name": {
"file_name": "dataset_name.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
对于 sharegpt 格式的数据集,dataset_info.json 文件中的列应该包括:
"dataset_name": {
"file_name": "dataset_name.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
},
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "user",
"assistant_tag": "assistant"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.3 数据下载
LLaMA-Factory项目内置了丰富的数据集,统一存储于data目录下。您可以跳过本步骤,直接使用内置数据集。您也可以准备自定义数据集,将数据处理为框架特定的格式,放在data下,并且修改dataset_info.json文件。
在本教程中,PAI提供了一份多轮对话数据集,执行以下命令下载数据。
cd LLaMA-Factory
wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama_factory/data.zip
mv data rawdata && unzip data.zip -d data
- 1
- 2
- 3

3. LLAMA3对话体验
由于我们是控制台没有办法用网页用户界面,所以没有办法使用:CUDA_VISIBLE_DEVICES=0 GRADIO_SHARE=1 llamafactory-cli webui完成微调。所以我们直接用快捷指令微调。这里提供了多样化的大模型微调示例脚本。
3.1单 GPU LoRA 微调
3.2(增量)预训练
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/lora_single_gpu/llama3_lora_pretrain.yaml
- 1
3.3 指令监督微调
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/lora_single_gpu/llama3_lora_sft.yaml
- 1
3.4 多模态指令监督微调
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/lora_single_gpu/llava1_5_lora_sft.yaml
- 1
3.5 奖励模型训练
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/lora_single_gpu/llama3_lora_reward.yaml
- 1
3.6 PPO 训练
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/lora_single_gpu/llama3_lora_ppo.yaml
- 1
3.7 DPO/ORPO/SimPO 训练
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/lora_single_gpu/llama3_lora_dpo.yaml
- 1
3.8 KTO 训练
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/lora_single_gpu/llama3_lora_kto.yaml
- 1
3.9 预处理数据集
对于大数据集有帮助,在配置中使用 tokenized_path 以加载预处理后的数据集。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/lora_single_gpu/llama3_preprocess.yaml
- 1
3.10 在 MMLU/CMMLU/C-Eval 上评估
CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval examples/lora_single_gpu/llama3_lora_eval.yaml
- 1
3.11 批量预测并计算 BLEU 和 ROUGE 分数
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/lora_single_gpu/llama3_lora_predict.yaml
- 1
3.12 单 GPU QLoRA 微调
3.12.1 基于 4/8 比特 Bitsandbytes 量化进行指令监督微调(推荐)
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/qlora_single_gpu/llama3_lora_sft_bitsandbytes.yaml
- 1
3.12.2 基于 4/8 比特 GPTQ 量化进行指令监督微调
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/qlora_single_gpu/llama3_lora_sft_gptq.yaml
- 1
3.12.3 基于 4 比特 AWQ 量化进行指令监督微调
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/qlora_single_gpu/llama3_lora_sft_awq.yaml
- 1
3.12.4 基于 2 比特 AQLM 量化进行指令监督微调
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/qlora_single_gpu/llama3_lora_sft_aqlm.yaml
- 1
3.13 多 GPU LoRA 微调
3.13.1 在单机上进行指令监督微调
CUDA_VISIBLE_DEVICES=0,1,2,3 llamafactory-cli train examples/lora_multi_gpu/llama3_lora_sft.yaml
- 1
3.13.2 在多机上进行指令监督微调
CUDA_VISIBLE_DEVICES=0,1,2,3 NNODES=2 RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/lora_multi_gpu/llama3_lora_sft.yaml
CUDA_VISIBLE_DEVICES=0,1,2,3 NNODES=2 RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/lora_multi_gpu/llama3_lora_sft.yaml
- 1
- 2
3.13.3 使用 DeepSpeed ZeRO-3 平均分配显存
CUDA_VISIBLE_DEVICES=0,1,2,3 llamafactory-cli train examples/lora_multi_gpu/llama3_lora_sft_ds.yaml
- 1
3.14 多 NPU LoRA 微调
3.14.1 使用 DeepSpeed ZeRO-0 进行指令监督微调
ASCEND_RT_VISIBLE_DEVICES=0,1,2,3 llamafactory-cli train examples/lora_multi_npu/llama3_lora_sft_ds.yaml
- 1
3.15 多 GPU 全参数微调
3.15.1 在单机上进行指令监督微调
CUDA_VISIBLE_DEVICES=0,1,2,3 llamafactory-cli train examples/full_multi_gpu/llama3_full_sft.yaml
- 1
3.15.2 在多机上进行指令监督微调
CUDA_VISIBLE_DEVICES=0,1,2,3 NNODES=2 RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/full_multi_gpu/llama3_full_sft.yaml
CUDA_VISIBLE_DEVICES=0,1,2,3 NNODES=2 RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/full_multi_gpu/llama3_full_sft.yaml
- 1
- 2
3.15.3 批量预测并计算 BLEU 和 ROUGE 分数
CUDA_VISIBLE_DEVICES=0,1,2,3 llamafactory-cli train examples/full_multi_gpu/llama3_full_predict.yaml
- 1
3.16 合并 LoRA 适配器与模型量化
3.16.1 合并 LoRA 适配器
注:请勿使用量化后的模型或 quantization_bit 参数来合并 LoRA 适配器。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
- 1
3.16.2 使用 AutoGPTQ 量化模型
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export examples/merge_lora/llama3_gptq.yaml
- 1
3.16.3 推理 LoRA 模型
使用 CUDA_VISIBLE_DEVICES=0,1 进行多卡推理。
3.16.4 使用命令行接口
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
- 1
3.17 使用浏览器界面
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat examples/inference/llama3_lora_sft.yaml
- 1
3.17.1 启动 OpenAI 风格 API
CUDA_VISIBLE_DEVICES=0 llamafactory-cli api examples/inference/llama3_lora_sft.yaml
- 1
3.18 杂项
3.18.1 使用 GaLore 进行全参数训练
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/extras/galore/llama3_full_sft.yaml
- 1
3.18.2 使用 BAdam 进行全参数训练
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/extras/badam/llama3_full_sft.yaml
- 1
3.18.3 LoRA+ 微调
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/extras/loraplus/llama3_lora_sft.yaml
- 1
3.18.4 深度混合微调
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/extras/mod/llama3_full_sft.yaml
- 1
3.18.5 LLaMA-Pro 微调
bash examples/extras/llama_pro/expand.sh
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/extras/llama_pro/llama3_freeze_sft.yaml
- 1
- 2
3.18.6 FSDP+QLoRA 微调
bash examples/extras/fsdp_qlora/single_node.sh
- 1
我们这里演示的就是对话实例
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
- 1
运行后出现以下问题:
OSError: You are trying to access a gated repo.
Make sure to have access to it at https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct.
401 Client Error. (Request ID: Root=1-665eec65-4bc590735915f5561f42d963;3d28d986-a6df-42b5-83d3-5483ef4d2e9f)
- 1
- 2
- 3
这代表部分数据集的使用需要确认,这里推荐使用下述命令登录您的 Hugging Face 账户
pip install --upgrade huggingface_hub
huggingface-cli login
- 1
- 2
将token填入
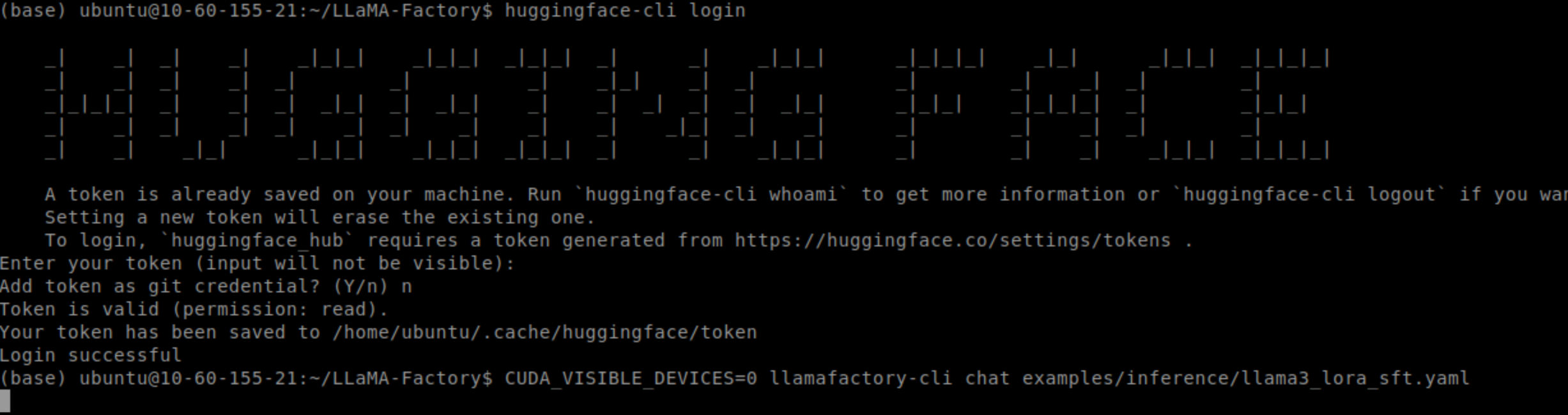
然后我们将meta-llama/Meta-Llama-3-8B-Instruct替换为NousResearch/Meta-Llama-3-8B-Instruct,在 examples/inference/llama3_lora_sft.yaml中。

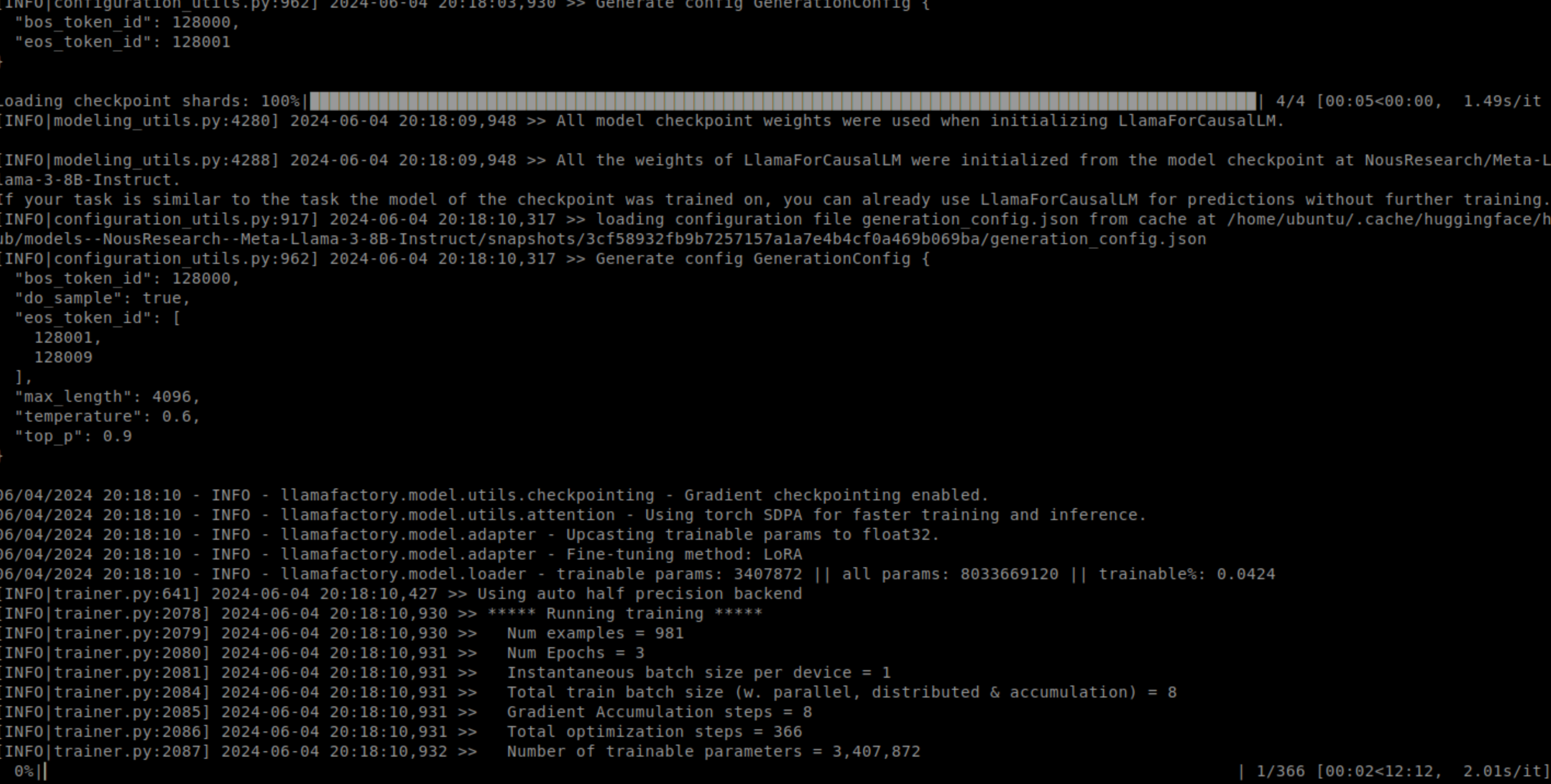
这里我们会发现仍然抱错,这里需要我们sft预训练一下。然后经过一系列下载后,很快就可以进行预训练了。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/lora_single_gpu/llama3_lora_sft.yaml
- 1
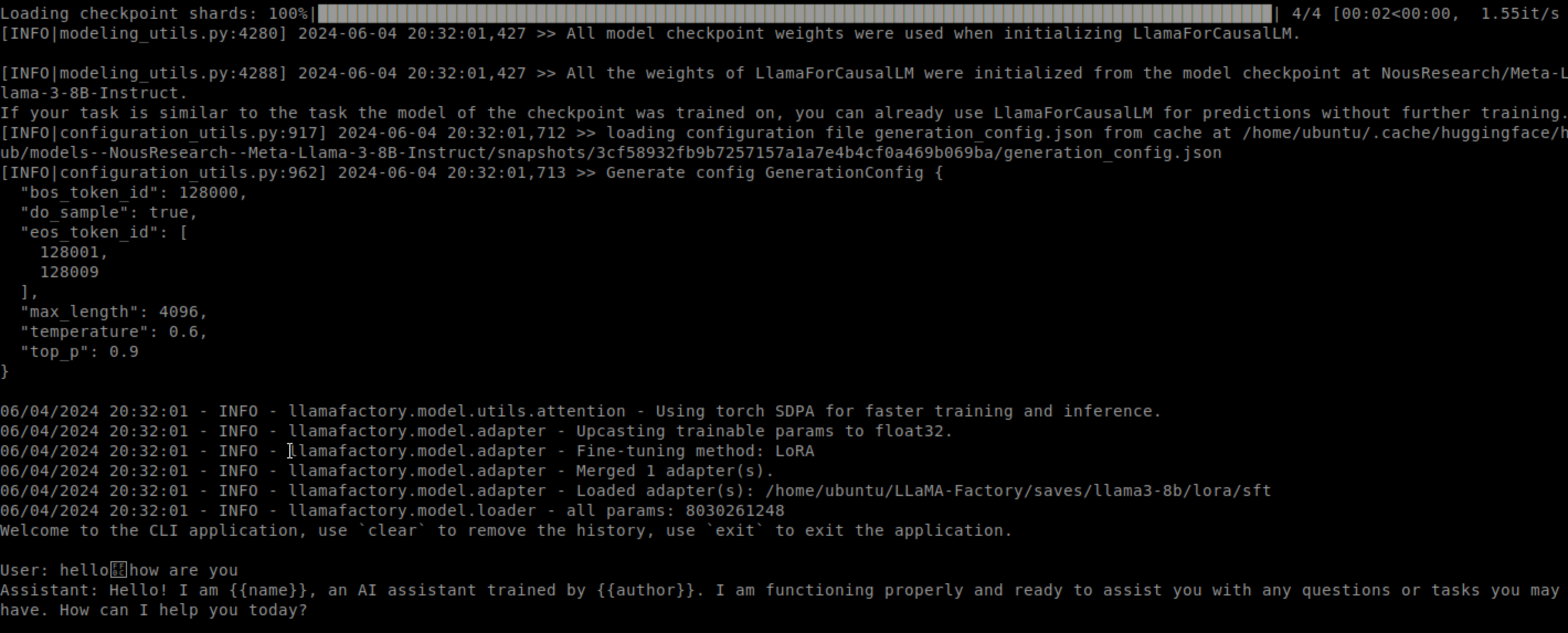
然后经过一系列下载后,很快就可以进行对话了
4. 参考链接
https://help.aliyun.com/zh/pai/use-cases/fine-tune-a-llama-3-model-with-llama-factory

