
- 1一文带你读懂深度估计算法
- 2windows 系统安装mysql8.0 及错误问题处理_windowsmysql8配置器错误
- 3mediasoup基础概览_mediasoup ndi
- 4数据结构-Treap(树堆) 详解
- 57 Series FPGAs Integrated Block for PCI Express IP核 Advanced模式配置详解(一)_pcie integrated block for pci express
- 6大模型的 5 月:热闹的 30 天和鸿沟边缘
- 7JDBC之MySQL的URL_mysqljdbc的url怎么写
- 8uni-app 配置编译环境与动态修改manifest,2024非科班生的Android面试之路_manifest 动态编译
- 9struct和class区别、三种继承及虚继承、友元类_class继承struct
- 10图片和16进制 互相转换_图片转16进制
消息队列--kafka_卡夫卡消息队列
赞
踩
学习地址:消息队列-Kafka - 掘金 (juejin.cn)
一般用于离线的消息处理当中,使用场景有日志信息、Metrics数据(程序运行中状态的采集,例如搜索服务、直播服务、订单服务、支付服务),用户行为(搜索、点赞、收藏、评论)。
如何使用kafka ?
创建kafka集群 —— 新增Topic ,设置好分区数量 —— 编写生产者逻辑(引用kafka的SDK,实现上游的生产逻辑) —— 编写消费者逻辑(拉取出来进行业务的处理)
基本概念:
Topic是卡夫卡中的一个逻辑队列,每一个不同的业务场景可以理解为一个Topic,对于一个业务来说的话所有的数据都存储在Topic中。
cluster:kafka的物理集群。
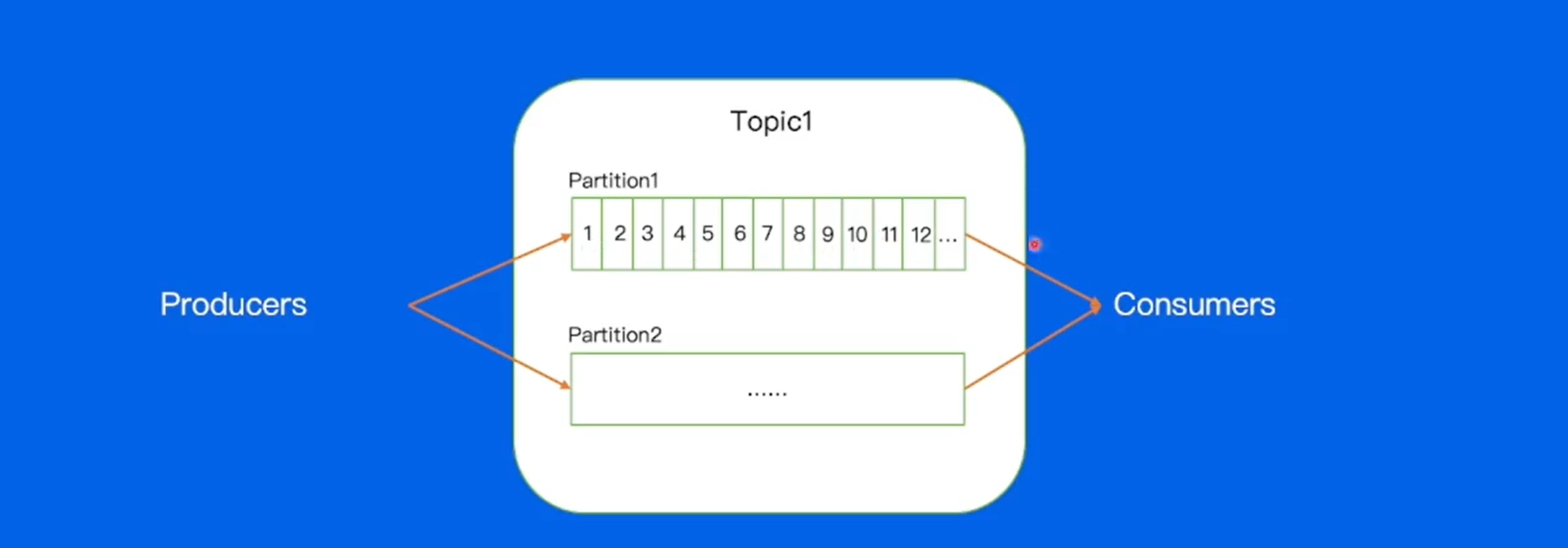
paritition:分区,不同的分区消息可以并发处理(消费进度互不干涉),提高Topic吞吐的能力。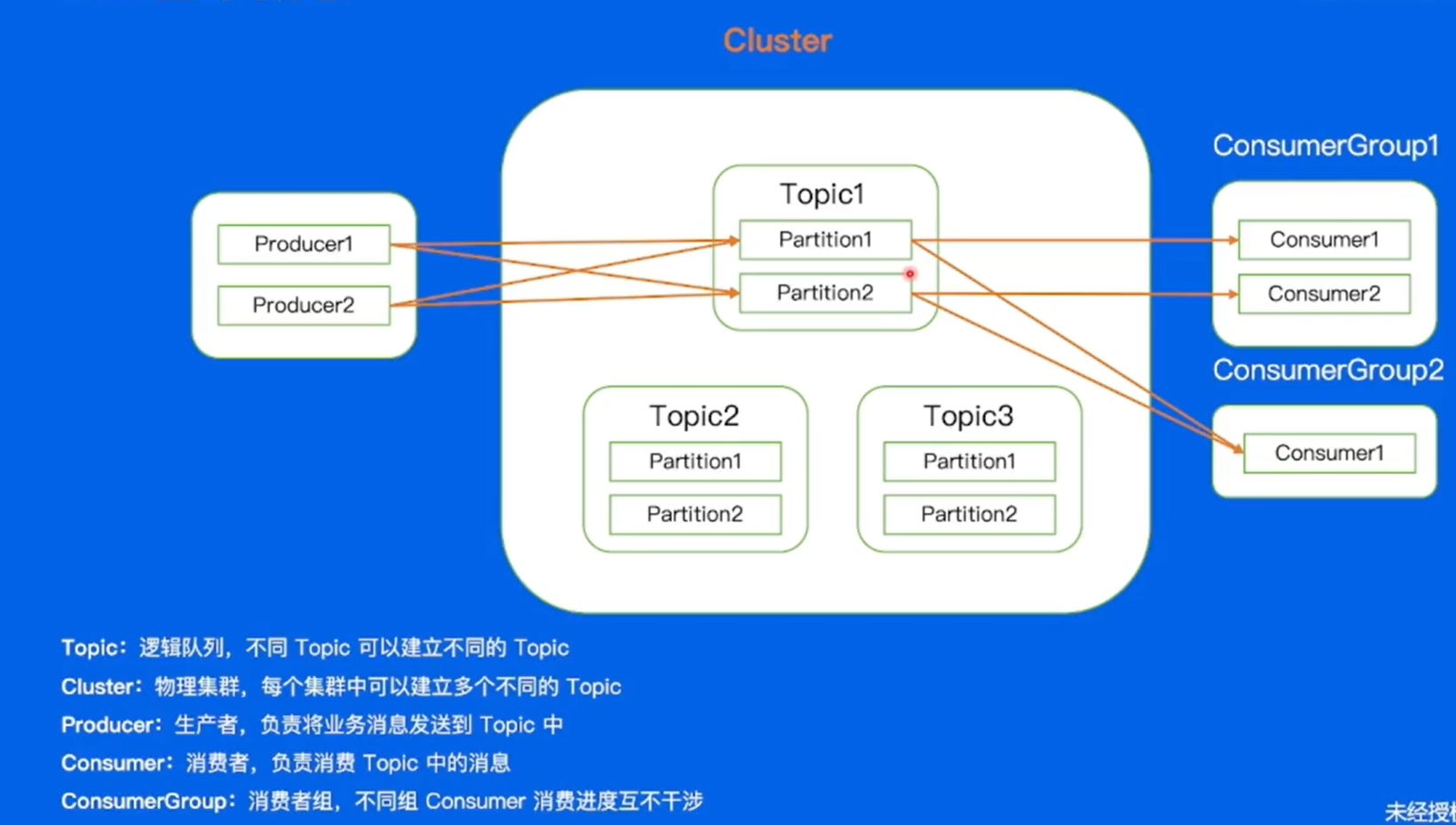
每一个partition内部都会去存储不同的消息。对于每一个消息都会有唯一的offset,是在partition中的相对位置,offset在partition内部是严格递增的。
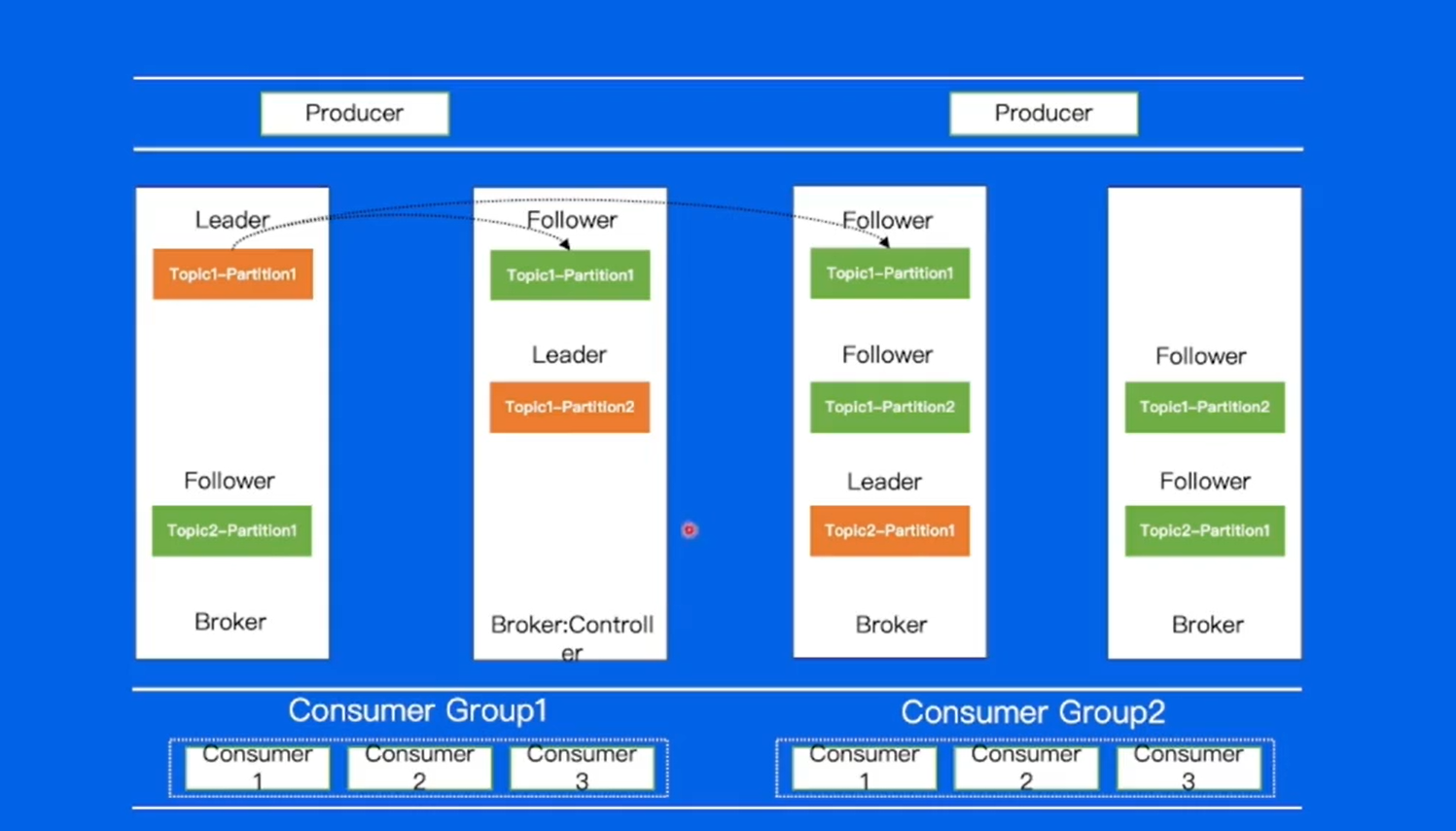
paritition:其中还有副本数的概念,多个副本会分布在集群中不同的机器上,达到容灾(数据的备份)的作用。
副本中有两个不同的角色,Leader和Follower,Leader角色用于对外写入或读取,也就是说生产者写入的消息首先会到Leader,消费也先从Leader中进行消费。Foller会不断的将数据从Leader上面拉取下来,努力和leader保持一致的状态。
ISR,对于follower,和Leader之间是有一个配置的,如果大于差距,就会被踢出ISR(在同步之中的副本)。在之前老版本中,是通过offset的差距来判断,现在通过时间的差距。
如果lelader所在机器的副本发生了宕机,那么就可以在ISR中重新选择一个副本,让其重新成为leader,来保证高可用。

数据复制
Broker代表kafka集群中的节点,所有的Broker节点组成集群。
Topic1(有两个分片),Topic2(有一个分片),每一个分区里面都是三副本的一个状态。
Broker:controller,整个集群的大脑,负责对集群中的所有partition进行分配,topic1-partition1在哪个broker上,topic1-partition2在哪个broker上,告诉broker怎么处理。
kafka架构
Zookeeper:和Controller配合,存储集群元数据信息,包括分区分配信息等。
一条消息的自述

思考:kafka为什么能支持这么高的吞吐量?
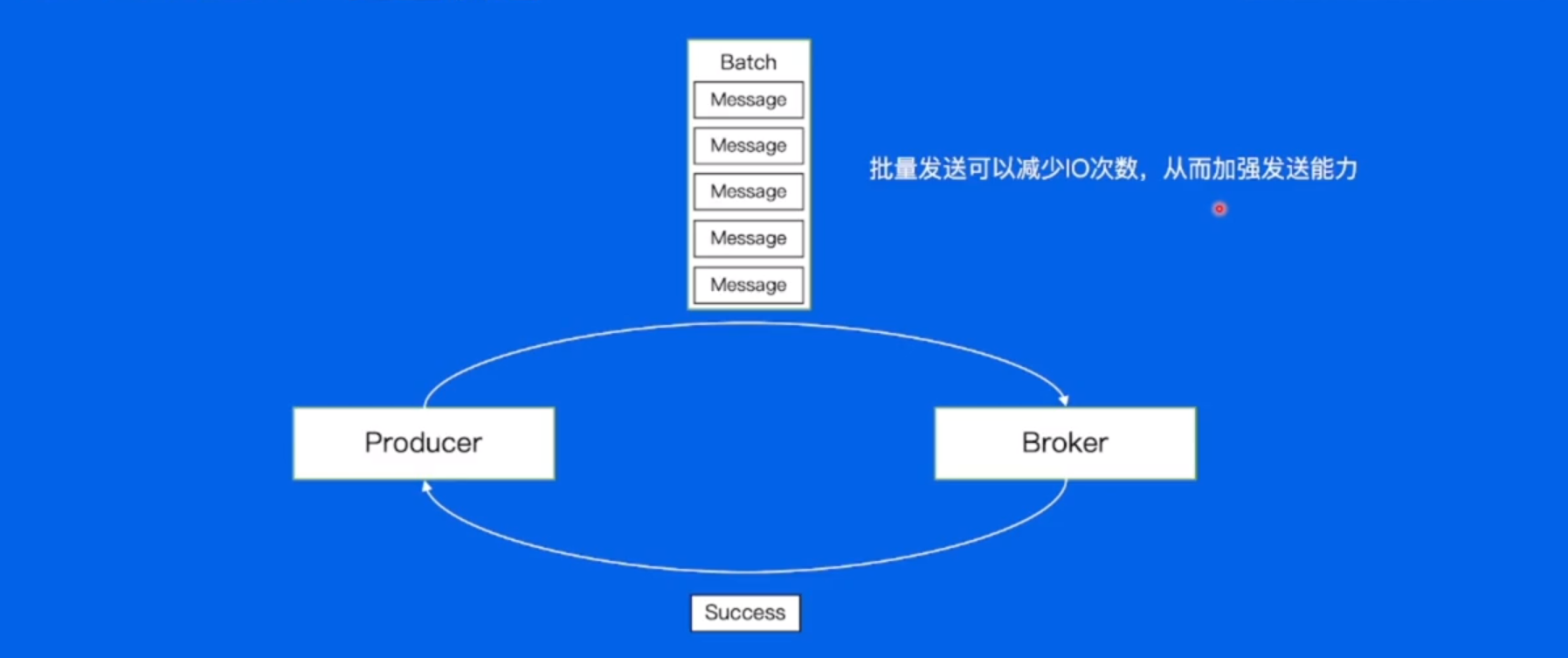
如果发送一条消息,等到返回成功后,再发送下一条消息,会有什么问题?假如发送1条消息需要发送100ms,所以1s只能发送10条消息。
先对消息做一个batch,批量发送可以减少IO次数,从而加强发送能力。
如果单个消息量很大,并发量很大,对于kafka来说带宽可能不够用,如何解决?
数据压缩
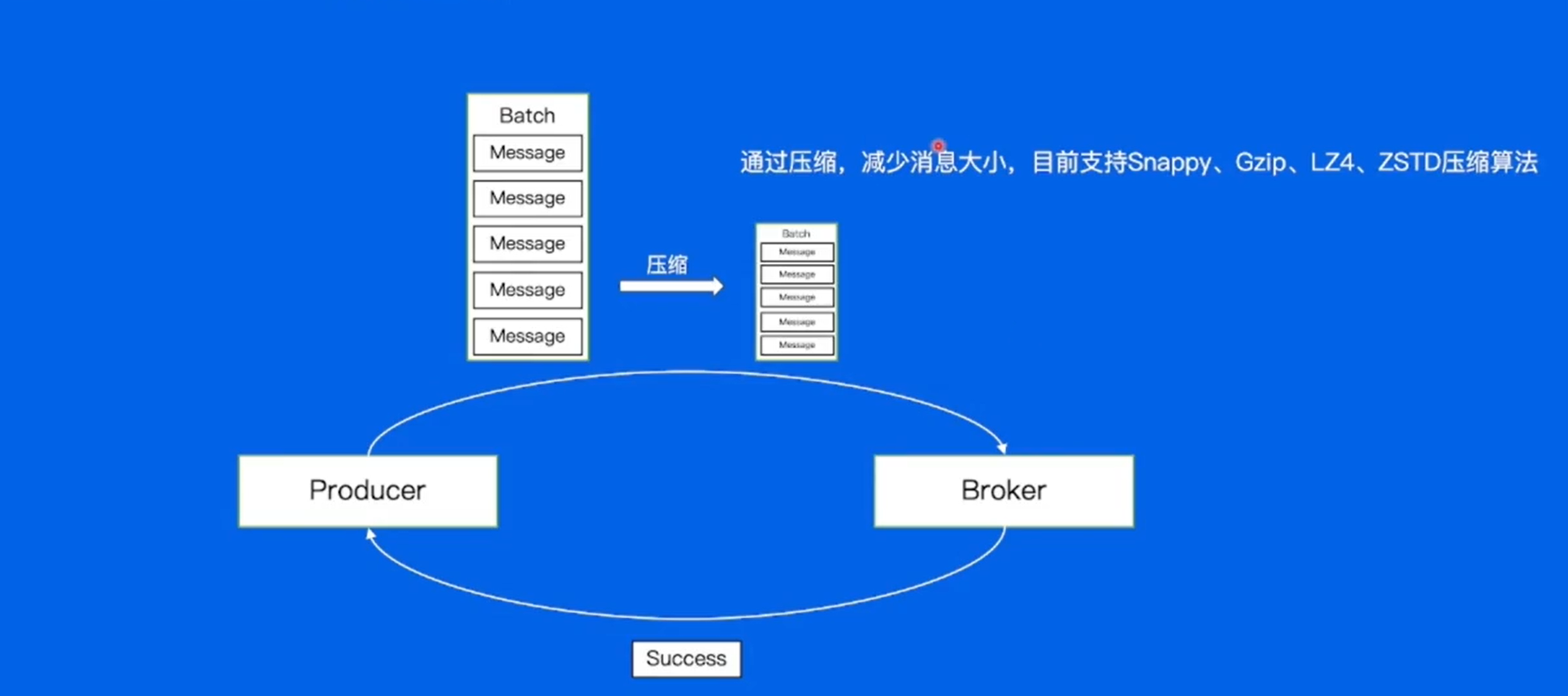
Broker -- 数据的存储(存储到本地磁盘)
Broker消息文件结构:
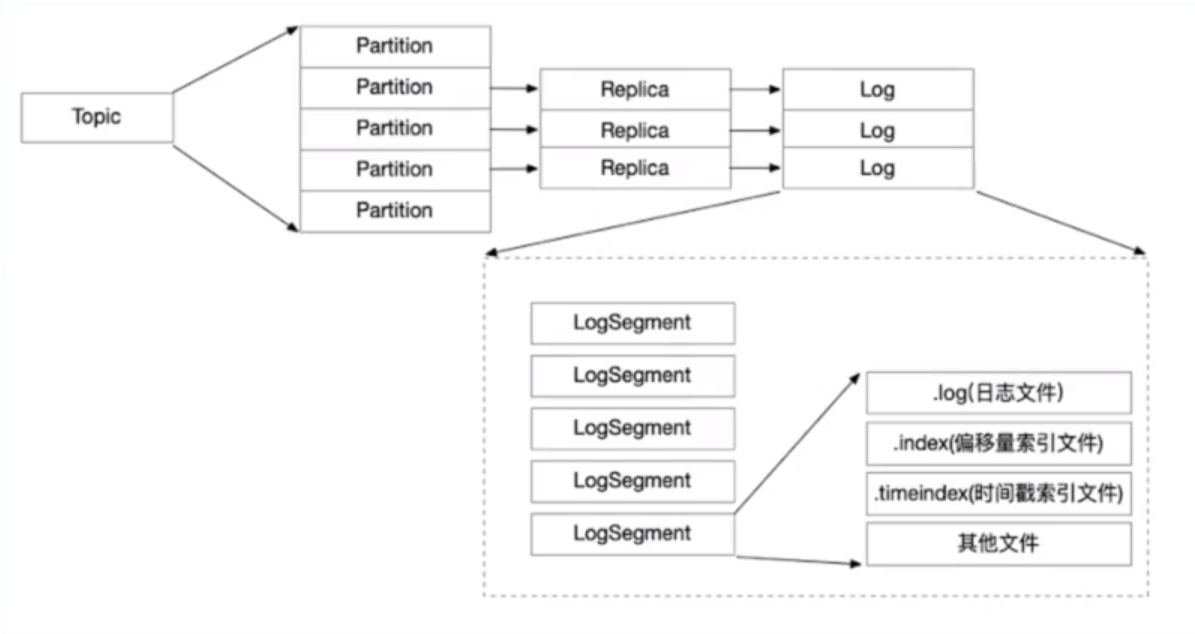
副本最终会以日志的形式写入到磁盘上,对于日志中写入的数据是存在一个过期机制的,过期的消息清除掉释放存储空间,对于log最终会切分成不同的logSegment有序日志段,.log存储真是消息的数据,.index:offset和真实的数据文件中的一个映射,知道数据在那个位置。
Broker -- 磁盘结构
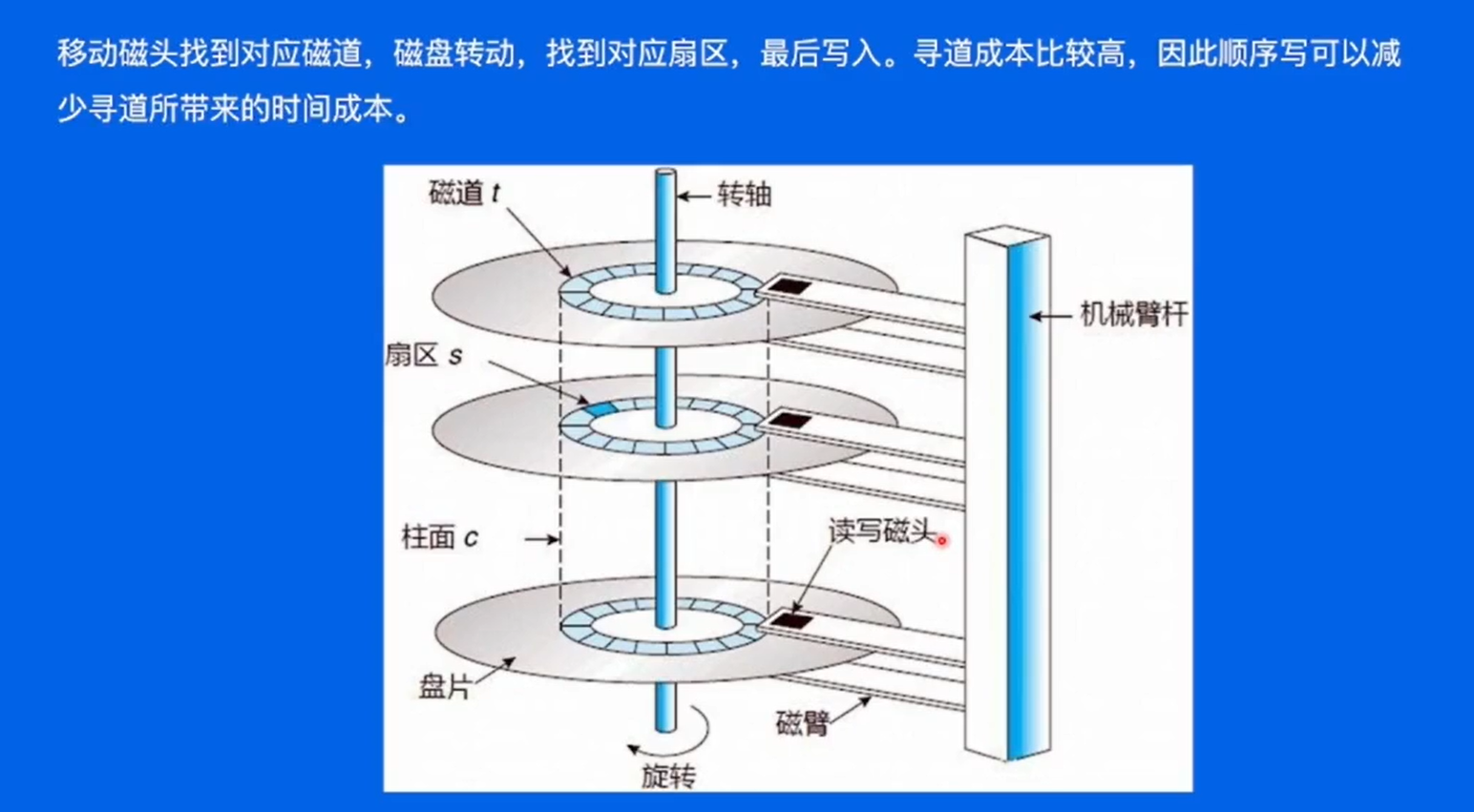 怎样找到扇区来进行数据的读写呢 ?
怎样找到扇区来进行数据的读写呢 ?
首先把磁头移动到指定的磁道上面,通过磁盘的转动找到对应的扇区,在扇区上进行消息的写入。移动磁头的时候会消耗比较大的时间。
在kafka中通过顺序写,提高写入效率,减少寻道的时间。

如何找到消息?
Consumer通过发送FetchRequest请求发送数据,Broker会将指定Offset处的消息,Broker会将指定offset处的消息,按照时间窗口和时间大小窗口发送给consumer,寻找数据这个细节是如何实现的呢?
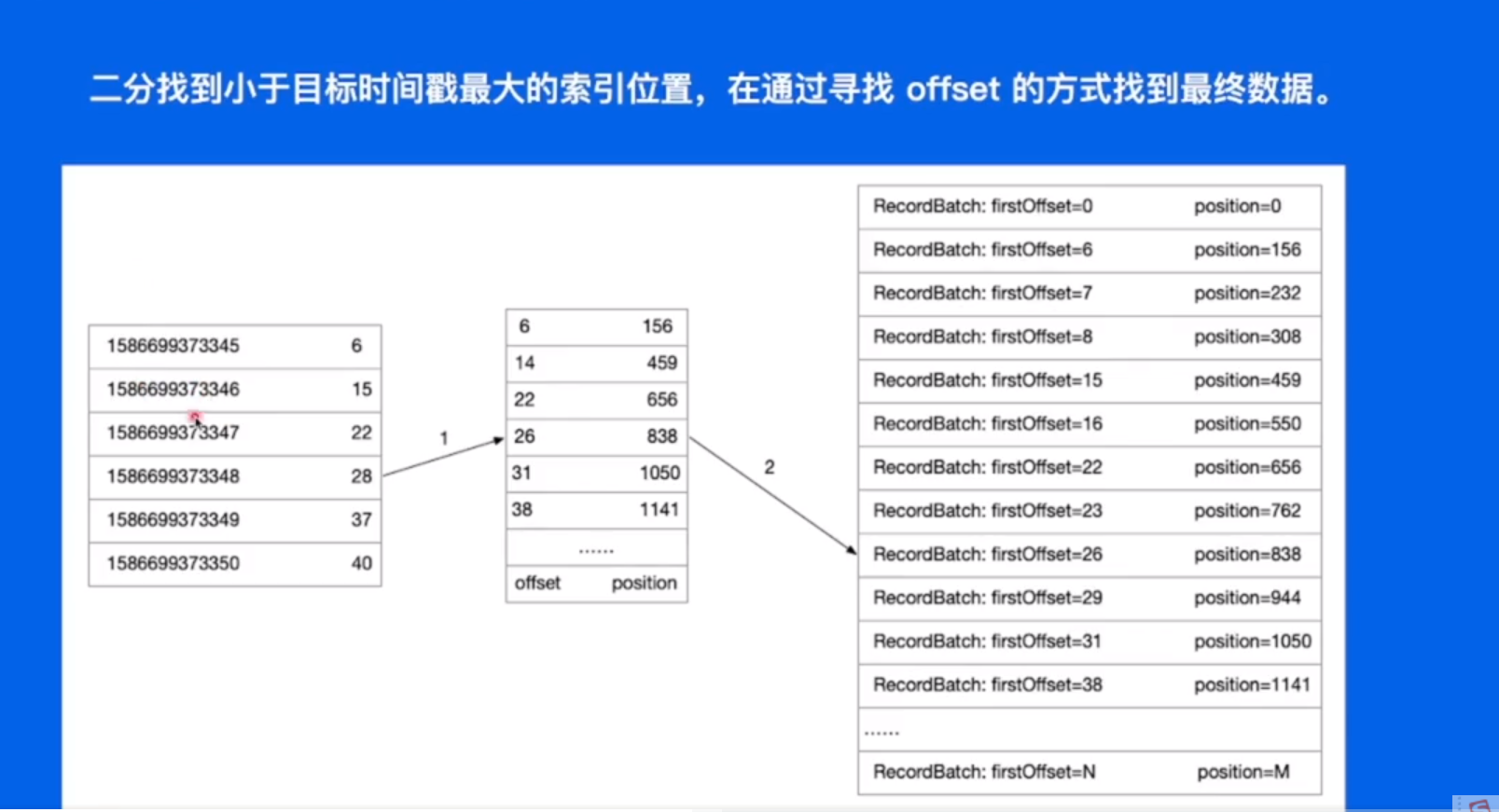
对于每一个logSegment来说都是以logsegment内的第一条消息的offset作为文件名的,先找到小于offset的最大文件,也就是6这个文件。

文件内部是一个什么样的状态 ?
kafka的文件索引采用稀疏索引的方式进行索引的构建。

保存了offset和位置的映射关系,同样,先找到小于目标offset的最大文件,将recordBatch中的数据拿出来,recordBatch里面存储了26,27,28三条数据,通过遍历找到28,在顺序的往下读。
时间索引是通过什么样的机制来找的呢?
在offset的上一层加二级索引,通过时间戳找到时间戳对应的offset,再根据如上进行数据的查询。
在找到数据并将数据发送给consume还存在什么样的优化?
传统数据拷贝:
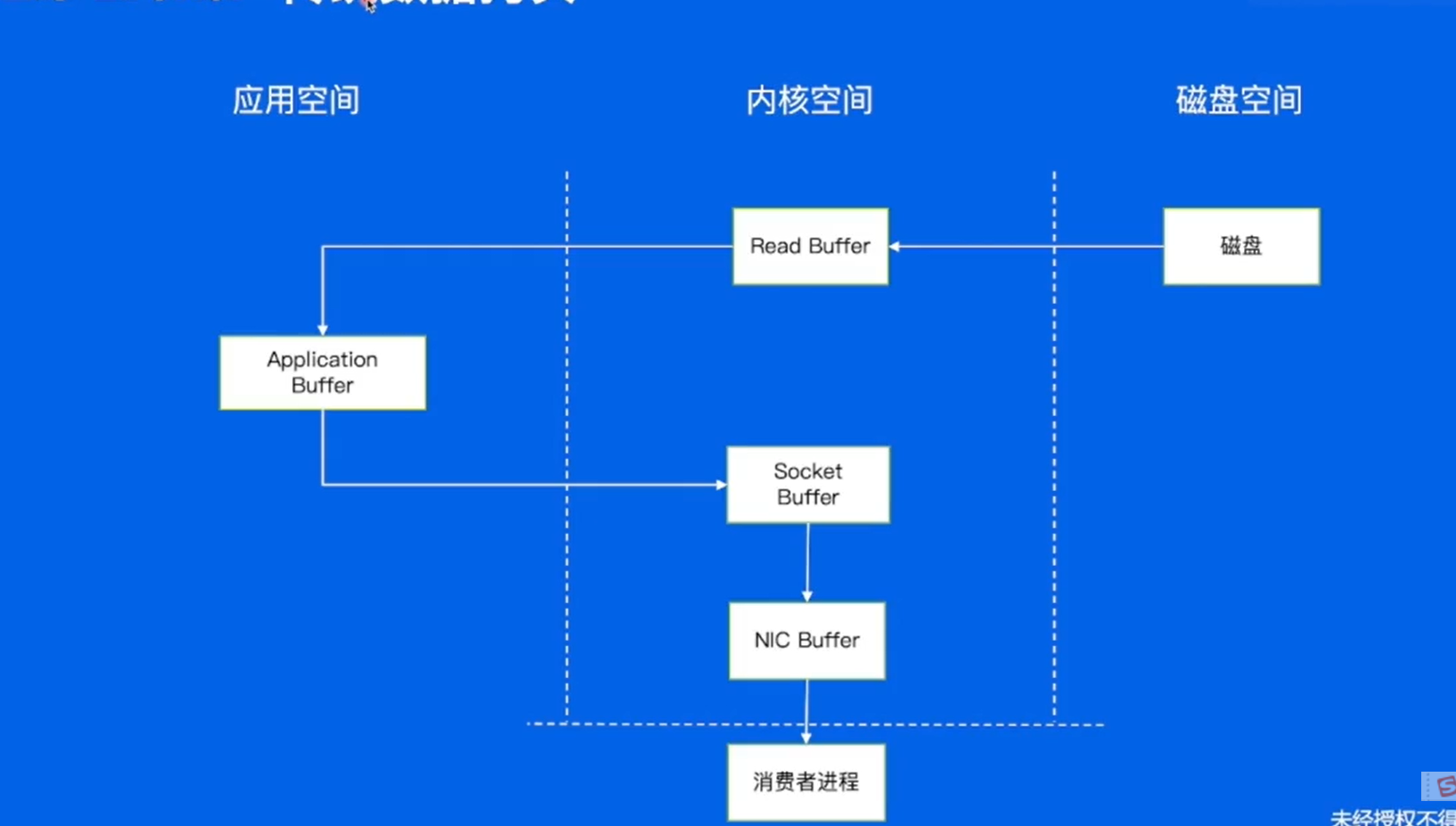
对于系统调用来讲,只能是内核态去操作,例如IO操作,如果要从磁盘中读取数据的时候,数据从内核态读取到内核空间,再拷贝到用户空间,再将数据从应用空间拷贝到socket buffer,发送给网卡内存,网卡内存发送给对端的消费者进程。有很多的内存拷贝,开销还是比较大的。
Broker -- 零拷贝
通过sendfile系统调用,把数据从磁盘读取到内核空间,内核空间可以把数据直接发送给网卡,直接发送给对端的消费者,不用经过用户空间和socket buffer对数据进行拷贝。
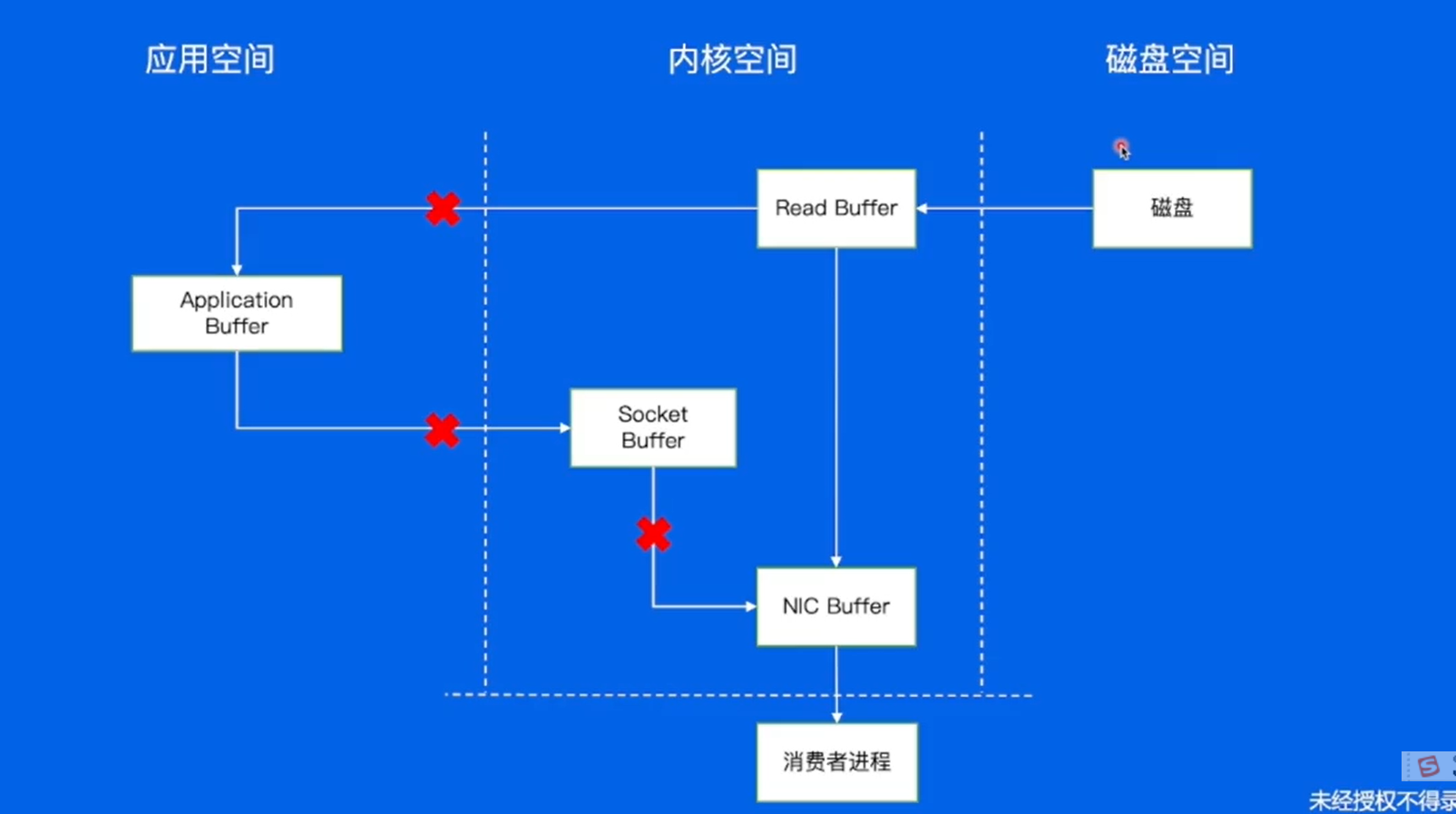
写入数据的时候也用到了零拷贝。
Consume -- 消息的接收端
如何解决Partition在consumer中分区的分配问题?
互不干扰,每一个group都要去拉取全量的数据。
两种解决办法:手动分配和自动分配 。
手动分配:在业务中规定consume这个进程要拉取哪些分支。

这样存在什么缺点呢 ?
如果Consume3进程挂掉,那么Topic中的partition7和partition8来说数据流直接断掉,对于线下业务来说是不能忍受的,不能容灾。
如果发现consumer1,2的能力不够,需要加一个机器起一个consumer4,怎样拉到Topic中的分片呢 ?
先把consumer1和consumer2进程停掉,将partition3和partition6分片让出来,再加到consumer中,启动consumer4进行消费,会存在数据中断的问题。
优点就是比较快。
自动分配
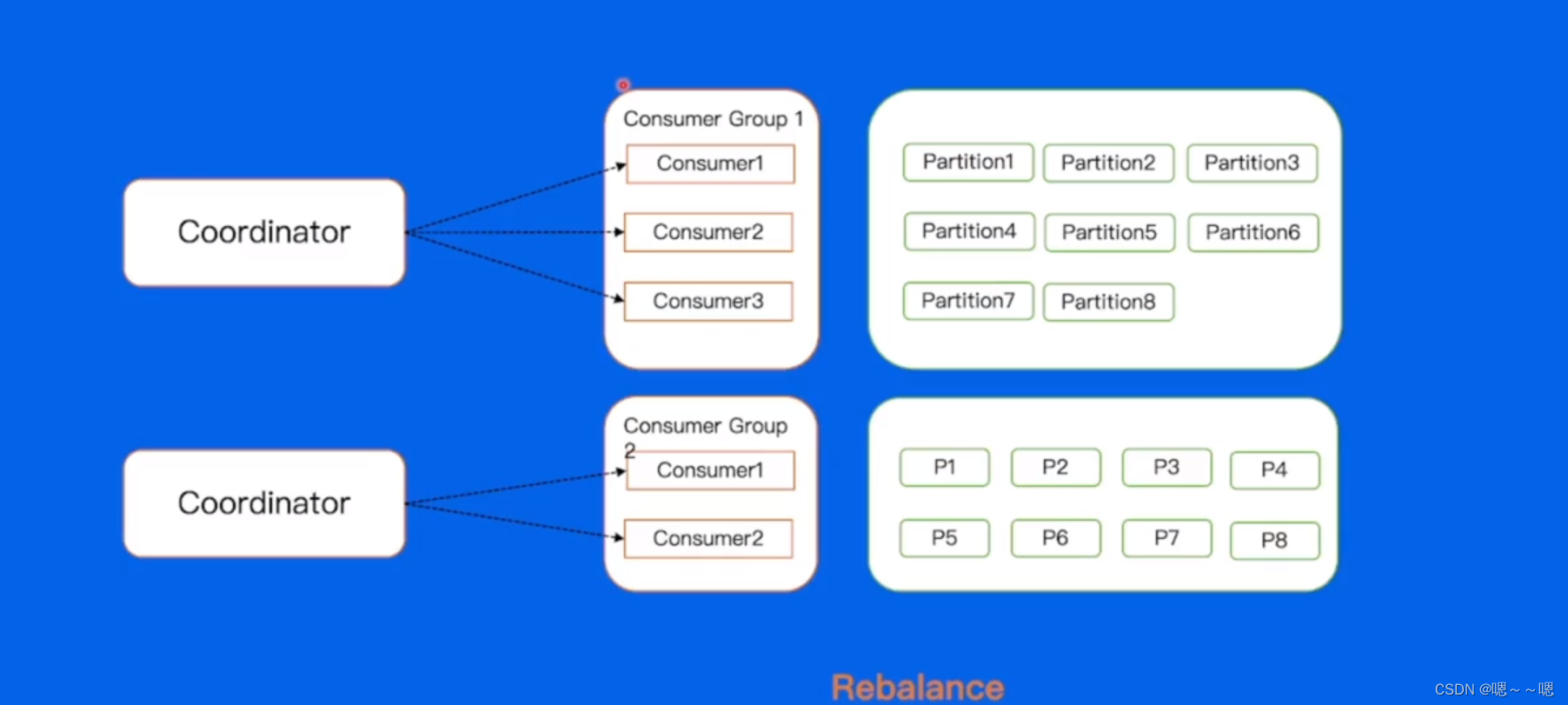
kafka提供的一个自动装配的方式,high-level,在broker集群中,对于不同的consumer group来讲,都会选举一个broker去当coordinator(协调者),帮助consumer group进行自动分配,使用这种方式,如果出现了consume3宕机,coordinator就会感知到,将consumer3踢掉,将其持有的分片均匀的分配到consumer1和consumer2上 。
如果新加入一个consumer4,同样会感知到,会将多出的分片给consumer4,重新计算每个consumer应该持有的分片。
Rebalance是如何发生的呢 ?
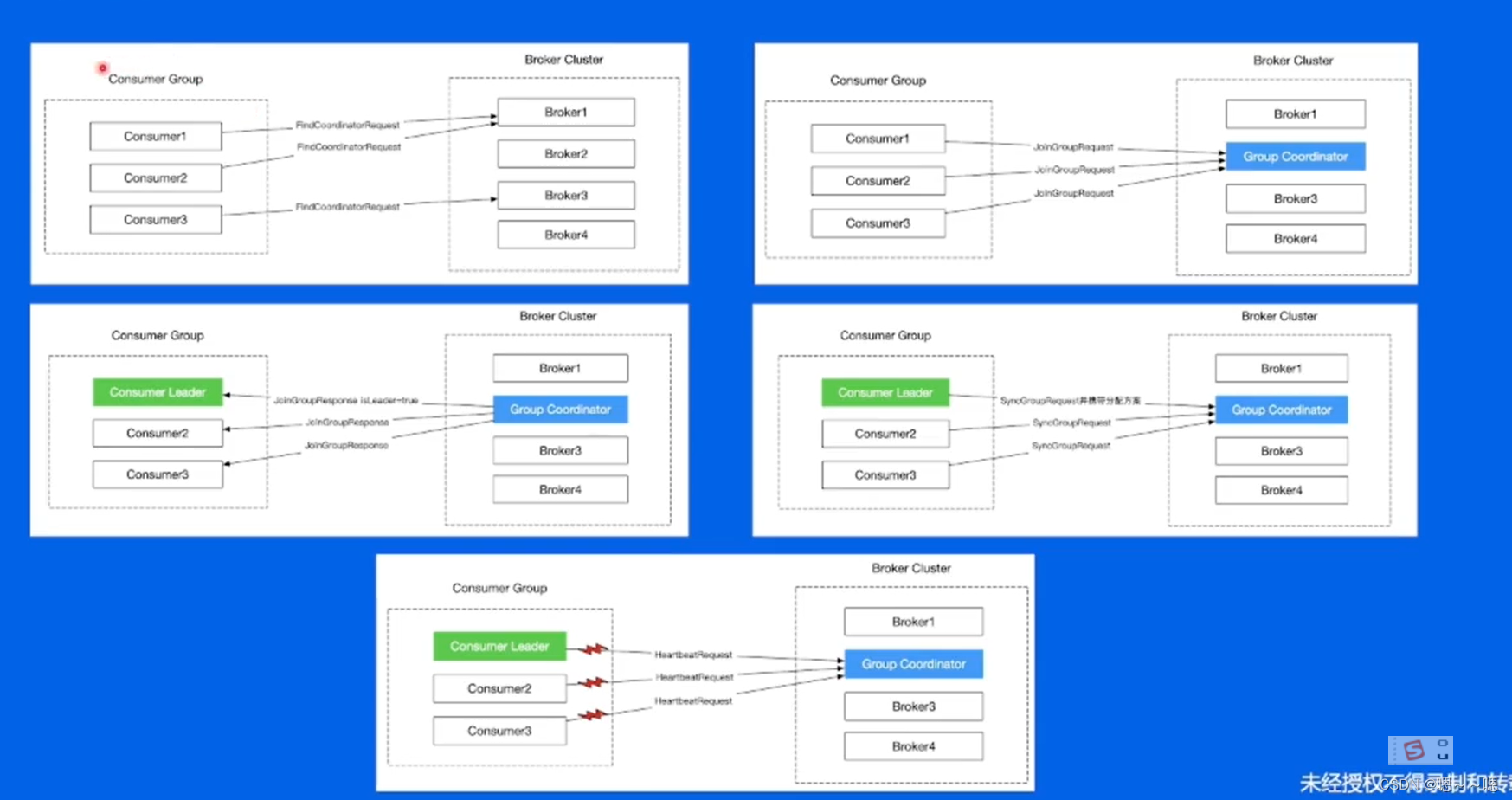
...... ...... (过几天再看)
帮助kafka提高稳定和吞吐的功能:
Producer:批量发送、数据压缩(降低带宽流量)
Broker:顺序写、消息索引、零拷贝
Consumer:Rebalance
kafka的缺点
数据复制问题
每一个Broker上面都有不同的Topic分区,分区有不同的副本,对于每一个副本来讲,它的所有数据都会存储到该节点上,对于不同节点之间通过数据复制的方式来保证数据的最终一致,达到集群高可用的目的。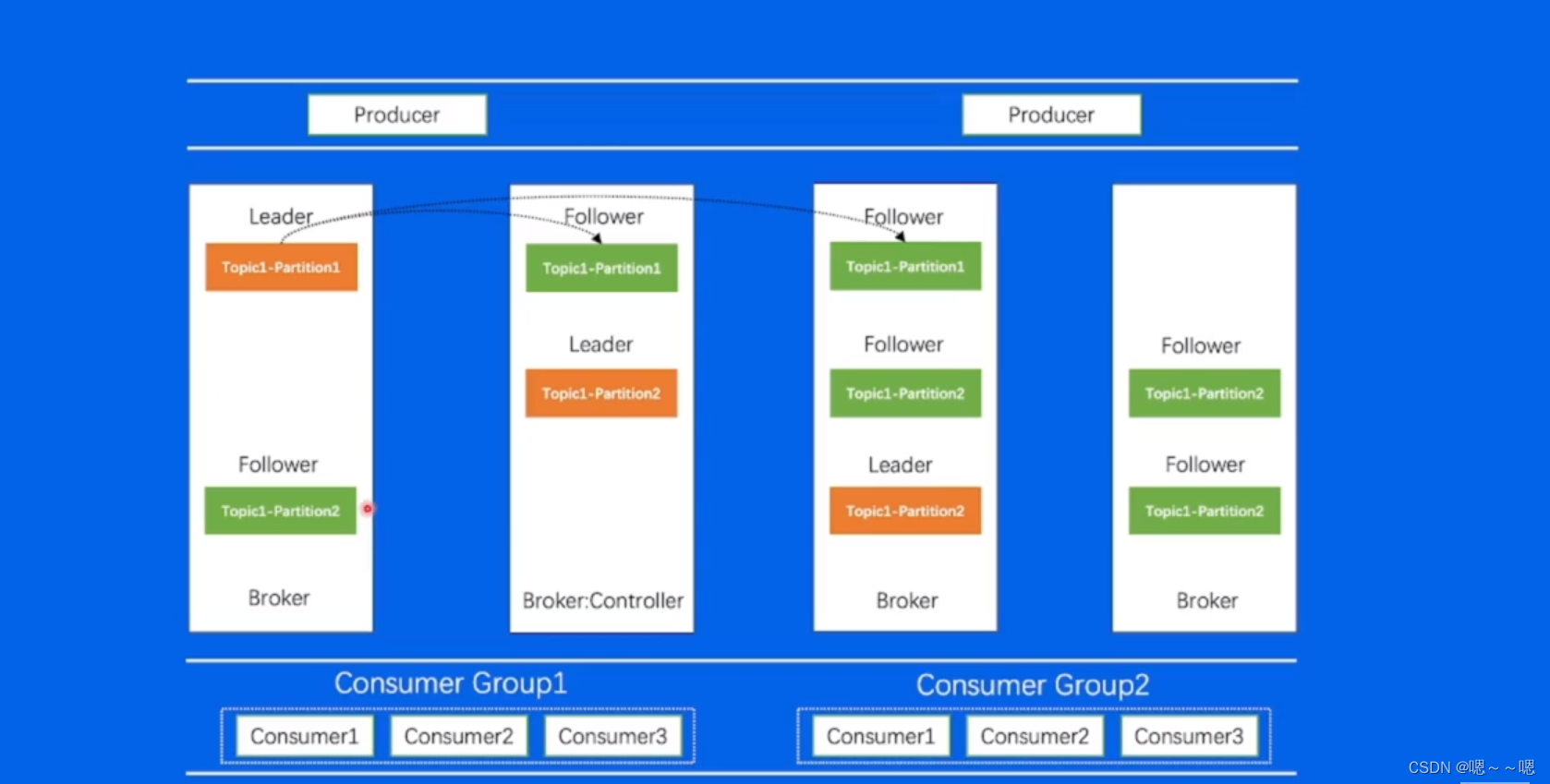
那么这样会有什么问题呢 ?
如果集群要做一个升级,会有程序的一个重启操作,会出现负载均衡的问题。
重启操作:
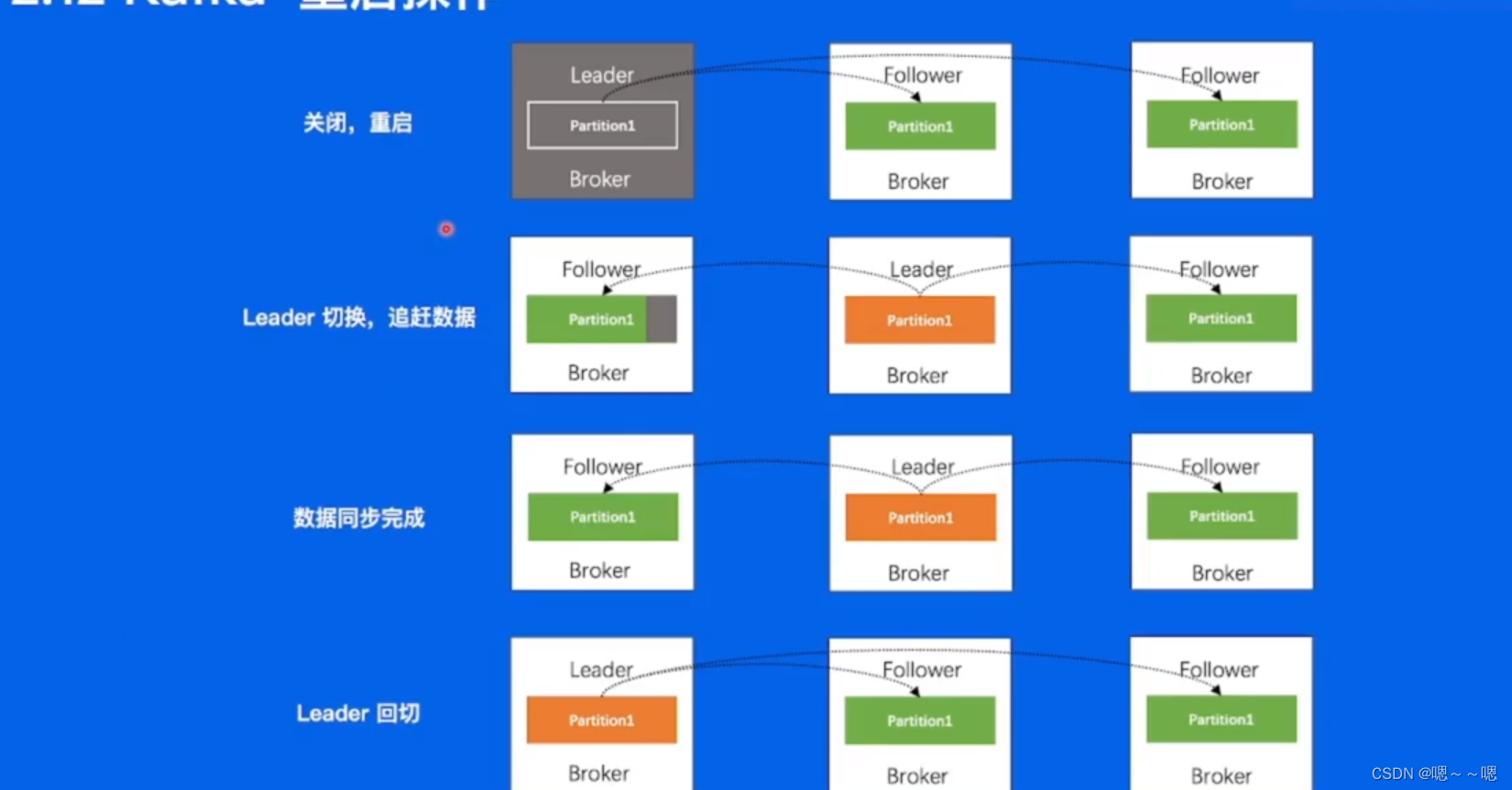
替换、扩容、缩容,从0开始进行数据的追赶。
负载不均衡
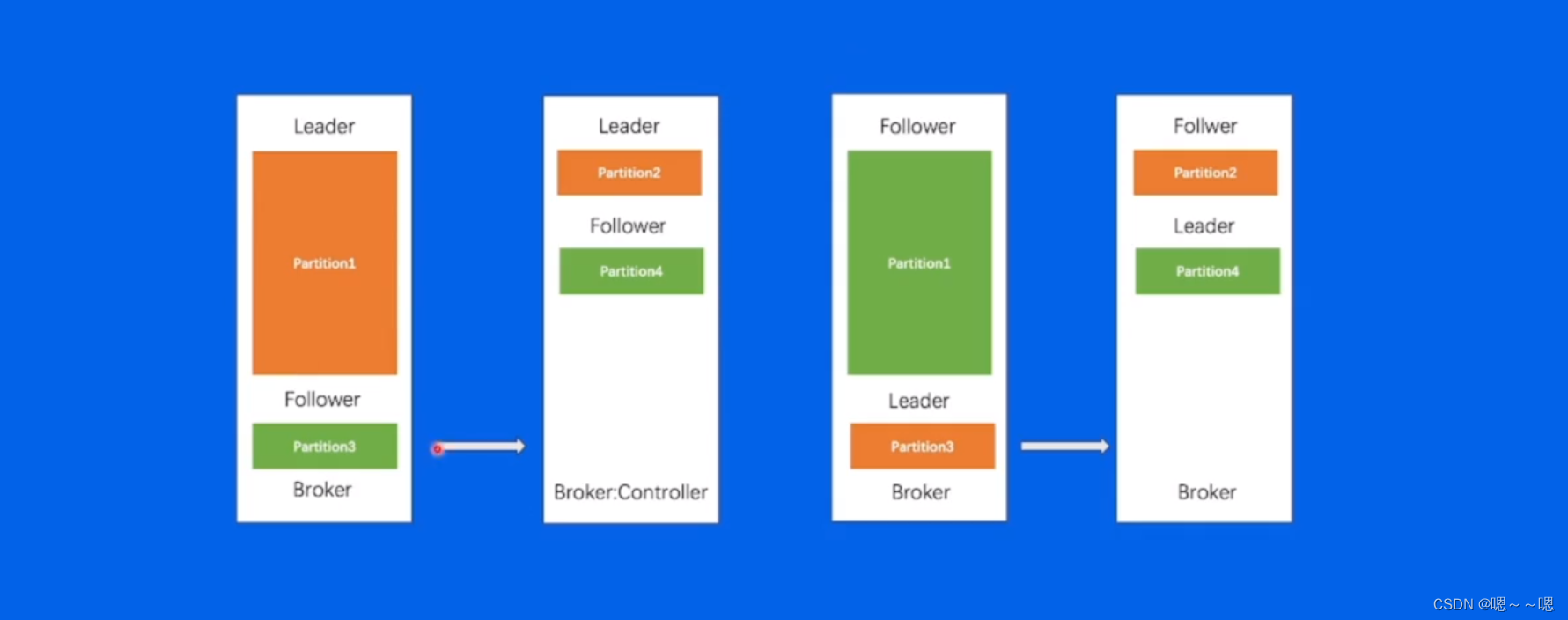
问题总结:



