
- 1springBoot2 请求映射原理
- 2git子模块的修改和更新操作_子模块怎么修改上传
- 3【postgresql初级使用】可以存储数据的视图-物化视图,加速大数据下的查询分析_postgresql 物化视图
- 4数据结构—基础知识:哈夫曼树
- 5【深度学习】基于tensorflow的服装图像分类训练(数据集:Fashion-MNIST)_服装数据集_基于深度学习的服装检测及分类
- 6vscode远程云服务器开发_vscode 利用tcp mqtt发布信息控制云平台执行器工作代码
- 7Kafka 3.7.0 使用源文件安装_kafka 3.7.0 版本 config
- 8Docker常用命令详解_docker操作命令
- 9切换python的默认版本_更改python默认版本
- 10Vue 表单生成器form-create的基本使用
MR的工作机制 —— Hadoop权威指南11_mr任务
赞
踩
- 之前,在学习Hadoop yarn时,有仔细分析过一个用户Application是如何在yarn部分实现任务运行的。
- 用户Application并非限定为MR作业,而是其他各种可以通过yarn实现资源管理和任务调度的Application
- 具体的运行机制,可以查看之前的博客:Hadoop YARN(入门) —— Hadoop权威指南5
- 如果想要了解MR的工作机制,从
Hadoop 2.x开始,必须要结合yarn去学习 - 《Hadoop权威指南》,第7章,就是结合yarn详细分析了MR作业的运行机制
1. MR作业运行机制
1.1 各实体的责任
client:负责提交MR作业
Resource Manager
- 负责接收clinet请求(提交Application、查询Application的运行状态)
- 管理Node Manager:接收Node Manager的资源报告信息,向Node Manager下达管理指令
- 启动并管理Application master,在Application master失败时,重启Application master
- 资源管理与分配:响应Application master的资源请求,为其分配Node Maneger上的container以运行任务
Node Manager
- 接收并处理来自Manager和Application master的启动或停止container的请求
- 启动并监管container(会在任务JVM失败时,告知Application master)
- 向Resource Manager上报自身的资源信息和所有运行中的container状态
Application master
- 向Resource Manager申请container,并将container进一步分配给Application中的具体任务
- 与Node manager通信,从而启动或停止container
- 监控task:可以在task失败时,重新申请container以重试task
分布式文件系统(一般为HDFS):在其他实体间共享作业文件
1.2 MR的运行流程
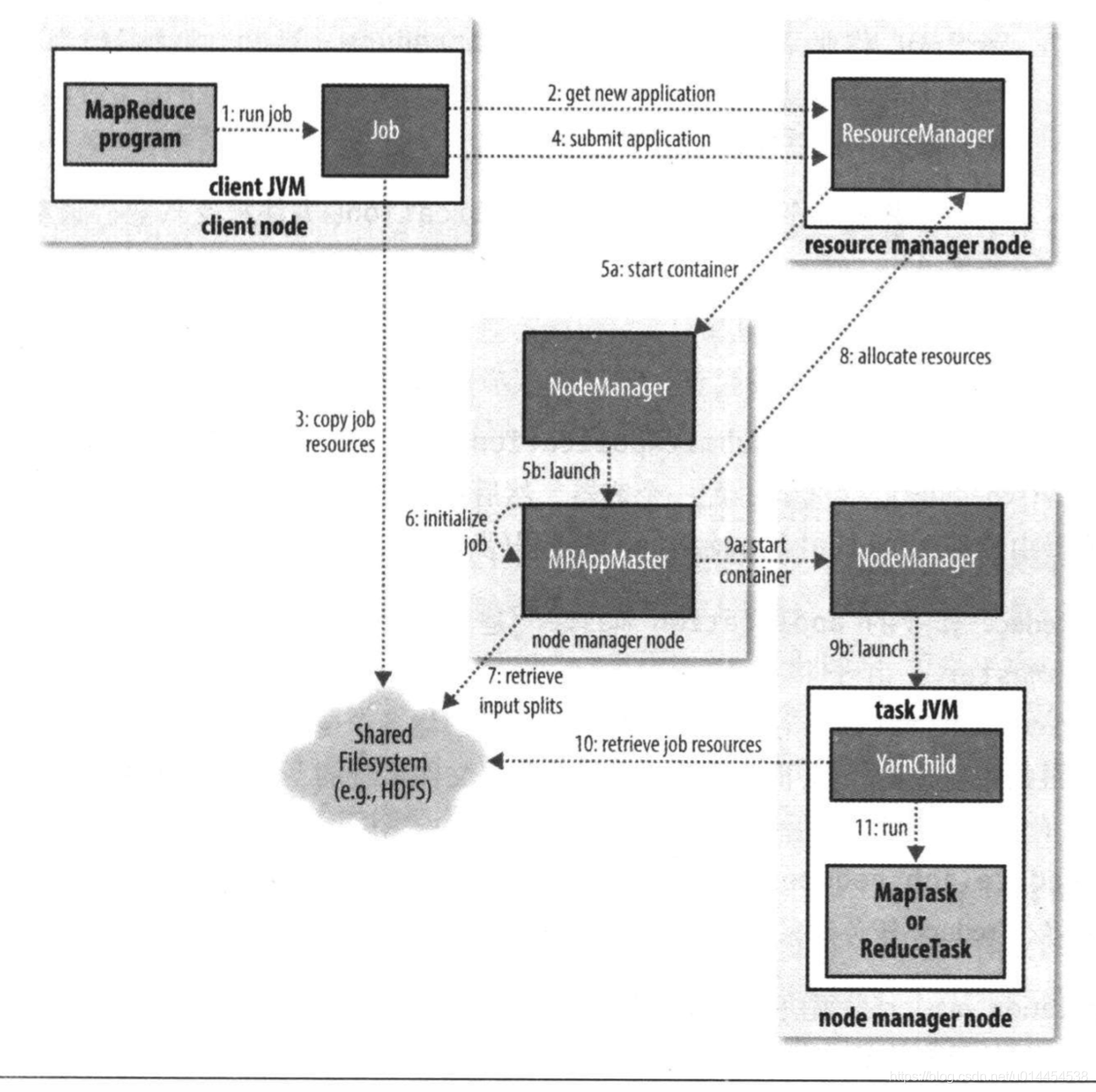
-
调用Job的
submit()方法,提交一个MR作业。实质上,submit()方法会创建一个Submitter实例,并其submitJobInternal()提交作业。 -
作业提交后,
waitForComletion()方法每隔一秒会轮询作业的状态,当作业失败或成功时,会退出该方法对应图中的步骤1
-
Submitter实例向Resource Manager申请一个新的Application ID对应图中的步骤2
-
Submitter会检查输出说明: 如果没有指定输出目录或输出目录已经存在,则不提交作业
-
Submitter计算作业的输入split: 如果输入split无法计算,如输入目录不存在,则不提交作业
-
submitter负责将作业运行所需的资源拷贝到以
job ID命名的共享目录下,包括jar文件、配置文件、计算所得的输入split对应图中的步骤3
-
Submitter调用Resource Manager的
submitApplication()方法,向yarn提交一个Application对应图中的步骤4
-
Resource Manager中的scheduler为Application master分配一个容器
-
在Resource Manger的指令下,Node Manager启动该容器并运行Application master,其主类是
MRAppMaster对应图中的步骤5
-
Application master初始化作业:创建多个簿记对象以保持对作业进度的跟踪
对应图中的步骤6
-
Application master接收共享目录中的、计算出的输入split,创建对应数量的map任务。同时,也根据设置创建确定数量的reduce任务
对应图中的步骤7
-
接下来,Application master需要根据作业的大小决定是否需要向Resource Manager申请container以运行map或reducer任务
(1)如果任务可以与Application master在同一个JVM中运行:其开销小于为这些任务单独申请container并运行的开销 —— 这样的作业称为uberized
(2)任务无法与Application master在同一个JVM中运行,则向Resource Manager为所有的map任务和reduce任务申请container
(3)container的请求顺序:首先为map任务请求container,且其优先级高于reduce任务的优先级。
(4) 实际上,直到有5%的map任务运行完成,reduce任务的资源请求才会发出对应图中的步骤8
-
一旦scheduler分配好了container,则Application master会与container所在的Node Manager建立通信,以启动container,从而运行任务
对应图中的步骤9
-
任务的运行是由名为
YarnChild的主类来执行的,YarnChild首先会将任务所需资源本地化(jar包、作业配置、输入数据等),然后再运行具体的map任务或reduce任务对应图中的步骤10和11
1.3 额外的知识
任务进度和状态的更新
- map任务的进度,使其已处理输入所占的比例;reduce任务的进度计算较为复杂,包括shuffle步骤的复制和排序、reduce的数据处理等
- map任务或reduce任务运行时,会每隔3秒、通过
umbilical接口向Application master上报自身进度和状态 - client每隔一秒轮询Application master,以获取作业的最新状态;client也可以通过Job的
getStatus()方法获取JobStatus实例,它包含作业的所有状态信息
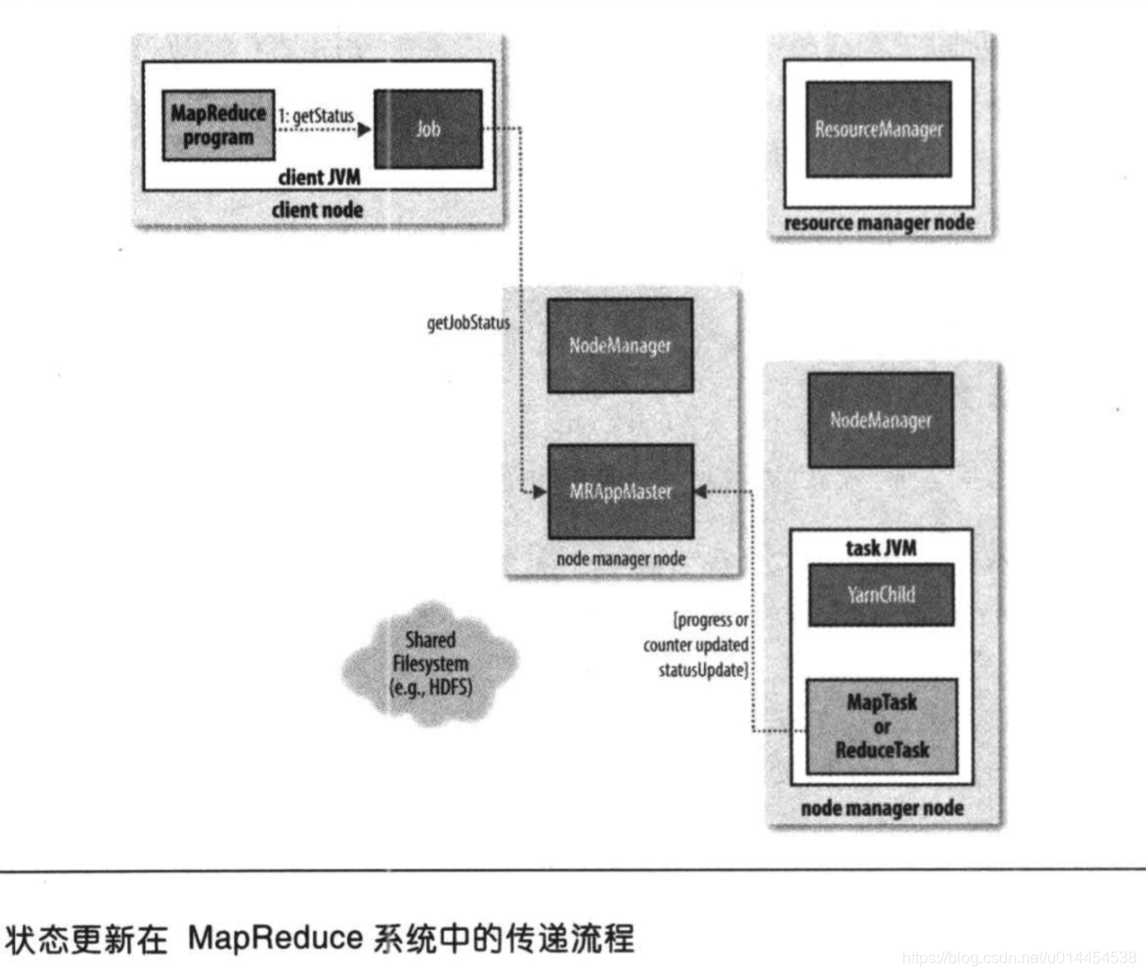
作业执行完成
- Application master收到作业的最后一个任务执行完成的报告后,会将作业状态设置为
成功 - Job中的
waitForCompletion()轮询时,发现作业已完成,退出执行 - 同时,Application master会将作业历史存储到HDFS中,以供后续查询
- 最后,Application master会向Resource Manager注销自己,允许其回收所有的container
2. 各种失败情况的处理
- MR作业的运行过程中,需要考虑 task、Application master、Node Manager、Resource Manager的失败
- 不同的失败场景,应该执行不同的操作,例如失败重试
2. task失败
task失败,实际是task attempt失败,有两种情况
- map任务或reduce中的用户代码抛出异常:
① 任务JVM在退出前,需要向Application master发送错误报告。
② 错误报告会记入用户日志,Application master会将该task attempt标记为failed并释放其占用的container - JVM突然退出:
① Node Manager会向Application master上报JVM中运行的task attempt
② Application master将task attempt标记为failed
task挂起
- task通过
umbilical接口,每隔三秒向Application master报告任务进度和状态 - 如果Application master超过10分钟,没有收到task的报告,则认为该task已失败
- Application master标记该task为failed,之后任务JVM进程会被自动kill
- task和Application master之间的超时时间,是可以通过配置进行设置的
以上三种情况,都会认为task失败
- Application master会重新向Resource Manager申请container,以重新运行失败的task
- 一般,一个任务不可能永远都进行失败重启,任务会有一个
maxattempts属性,控制其最多尝试次数 maxattempts的默认值为4,当任务失败4次后,则不会再失败重启。这意味着,整个MR作业失败
特殊情况
- 如果通过某些方式中止(
killed)task attempt,则任务会被标记为killed。 - 被killed的任务,不会记入尝试次数
2.2 Application master失败
- 与作业的
maxattempts一样,Application master也有自己的最大尝试次数,默认为2
Application master的失败与恢复
- Application master与Resource Manager之间存在周期性的心跳,当Resource Manager检测到Application master失败时,会重启一个新的Application master
- Application master通过作业历史来恢复Application所运行的任务状态,而无需重新运行任务
- 作业初始化时,client就会从Resource Manager出获取并缓存Application master的地址。如果Application master失败重启,client需要重新向Resource Manager请求Application maste地址
2.3 Node Manager的失败
- Node Manager 与Resource Manager之间存在心跳
- 如果因为Node Manager崩溃或运行非常缓慢,导致Resource Manager在10分钟内未收到来自Node Manager的心跳,则认为Node Manager失败
- Node Manager与Resource Manager之间的心跳超时,可以通过配置进行设置
Node Manager失败的处理
- Node Manager上正在运行的任务和Application master,按照各自对应的策略重新启动
- 个人理解: 任务会因为长时间未向Application master发送心跳而被认为失败,Application master会因为长时间未向Resource Manager发送心跳而被认为失败
- 特殊情况: 由于map任务的输出会存储在本地磁盘,如果Node Manager上存在已成功执行的、属于未完成作业的map任务,很可能它们的输出将无法访问 —— 需要重新执行这类map任务
2.4 Resource Manager失败
- 从学习yarn以来,我们了解到的都是只有Resource Manager。
- 因此,在默认配置下,Resource Manager将会是一个单点故障
- 为了支持HA,可以为集群配置一对Resource Manager。主Resource Manager失败,备Resource Manager可以迅速接管,让用户无明显感知
Resource Manger在HA下的失败处理
- 所有处于运行中的Application信息都会存储到一个高可用的状态区,如Zookeeper或HDFS
- 主Resource Manager失败,备Resource Manager通过读取这些状态信息,可以迅速恢复主Resource Manager的状态
- Resource Manager重启后,会将集群中运行的所有Application master重启 —— 不计入Application master的重启次数中
Resource Manager的状态区,需要存储的信息相对MR的jobtracker非常少:
- 状态区不会存储Node Manager的相关信息,因为当新的Resource Manger接收到Node Manager的心跳后,可以快速重构Node Manager的信息
- Application master所负责的task信息也不会被状态区存储
3. Shuffle
- 在同事的技术分享中,我发现无论是MR的shuffle还是spark的shuffle都是其
灵魂 - 所谓shuffle,英文意思是洗牌。这不是发牌者的那种混洗,而是持牌人的合并、排序
- 针对MR,从map任务的输出到reduce任务的输入,这一中间过程就是shuffle
- 具体来说,包括map端的shuffle和reduce端的shuffle
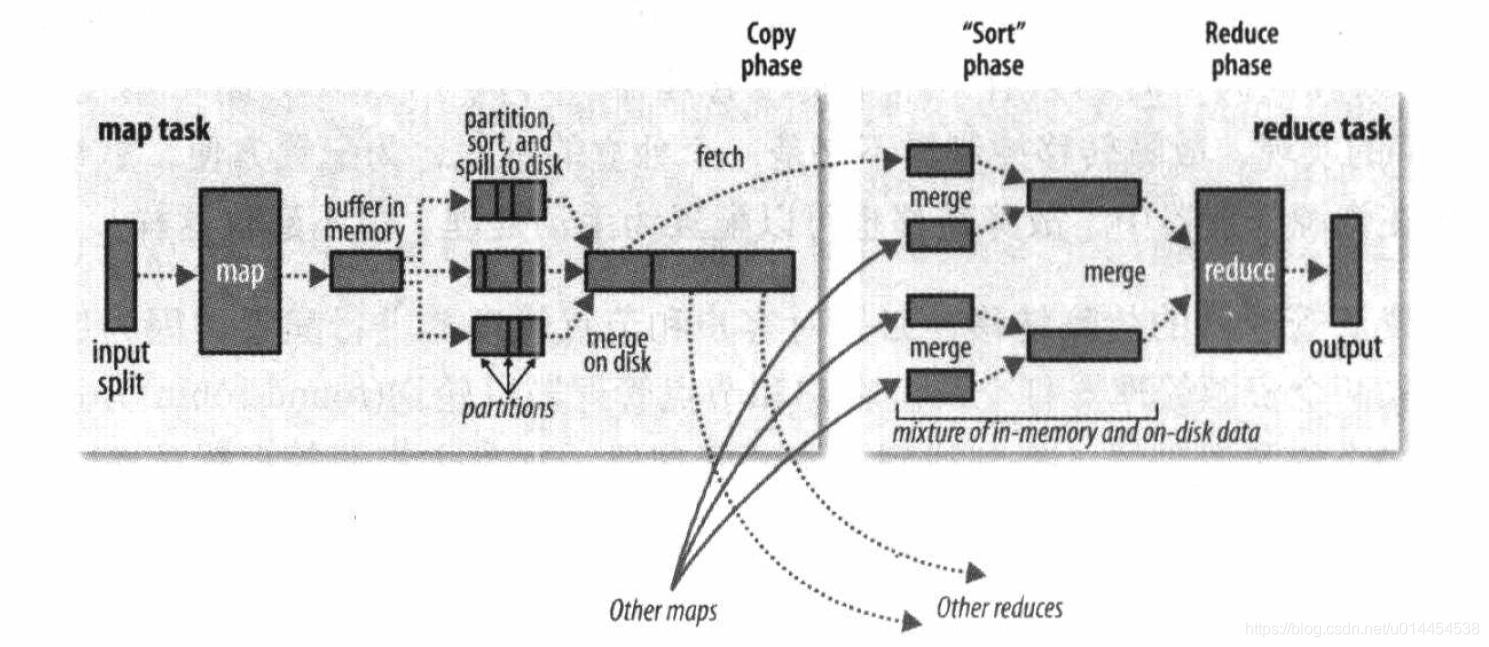
3.1 map端的shuffle
-
每个map任务都有一个环形的缓冲区,一般为
100 MB,用于缓存map任务的输出。 -
数据写入缓冲区前,会按照reduce任务的个数计算其对应的分区编号,存入元数据中
-
当缓存内容达到设定的阈值,一般为 80 % 80\% 80%,即
80 MB时,会将缓冲区中的内容溢写到磁盘。对应图中,map端的spill操作
-
将数据溢写到磁盘前,会按照数据的分区编号,将相同分区的数据合并到一起
对应图中,map端的partition操作
-
针对同一分区的数据,会对其按照key进行排序。
-
如果存在combiner函数,还会对排序后的结果进行处理,时map任务的输出更紧凑
对应图中,map端的sort操作
-
直到map任务结束,一般会产生多个溢写文件。
-
这些溢写文件会合并成一个大的的输出文件,这个输出文件是已经分区且排序的文件
-
如果溢写文件超过3个(该值可以设置),combiner函数会在溢写文件合并到磁盘前,再次执行combine操作
对应图中,map端的merge on disk 操作
3.2 reduce端的shuffle
-
reduce任务通过HTTP从多个map输出中获取对应分区的数据,这也就是reduce任务的复制阶段。
-
reduce任务存在少量的copy线程,可以实现分区的并行复制
-
reduce任务如何知道map输出地址的?
① map任务通过心跳告知Application master,map输出与主机之间的映射关系址。
② reduce任务存在一个线程,定期询问Application master,以获取map输出的地址对应图中,reduce端的copy阶段
-
reduce任务将从不同map输出获取到的分区进行排序,准确的说是合并。这也就是reduce任务的排序阶段
-
排序阶段,会将多个map输出进行合并,直到产生一个reduce输入。
-
如果有50个map输出,合并因子为10,则每次合并10个map输出,最终产生5个中间文件
-
注意:map输出个数和合并因子的比值,并非一定是合并次数。
-
例如,40个map输出,可以使用5次合并,最后一次的合并来自磁盘和内存
对应图中,reduce端的sort阶段
3.3 shuffle调优
- 《Hadoop权威指南》还介绍了,如果通过调优shuffle过程来提高MR的效率
- 但是自己使用的并不多,因此没有仔细阅读
4. 总结
-
结合yarn,描述MR任务的具体工作流程
- client提交作业,获取到一个submitter实例;执行
waitForCompletion()轮询作业状态,作业失败或成功,退出该方法 - submitter向Resource Manager申请Application ID
- submitter负责检查作业的输出说明;计算split;将运行作业所需的各种资源组copy到一个共享目录下
- submitter调用
submitApplication()方法,向yarn提交一个application - Resource Manager分配一个容器,用于运行Application master,其主类为
MRAppMaster - Application master进行作业的初始化:创建簿籍对象以跟踪作业进度
- Application master从共享目录获取资源,从而计算出map任务和reduce任务数
- Application master向Resource Manager申请container:可能是uber任务,与Application master运行在同一个JVM;先申请map任务的container,再申请reduce任务的container
- Application master与Node Manager通信,使其启动container以运行任务
- 任务放到
YarnChild中运行,YarnChild会先从共享目录获取资源,然后再执行任务
- client提交作业,获取到一个submitter实例;执行
-
MR任务再运行过程中,可能出现的各种失败情况
- 任务失败:
- 三种情况会被视为任务失败:① 用户代码抛出异常,导致任务失败;② JVM突然退出;③ task在规定时间未向Application master上报信息
- 失败的任务会记入重试次数,如果超过重试次数,则整个作业失败
- 任务被kill不会记入重试次数
- Application master失败
- 由Resource Manager负责检测Application master的运行情况
- Node Manager的失败
- Node Manager崩溃或运行缓慢导致心跳超时,则被Resource Manager认为失败
- 重新运行Node Manager上未完成的任务、已完成的map任务
- Resource Manager失败
- 需要提供高可用的Resource Manager,避免单点故障
- 任务失败:
-
关于shuffle
- map端的shuffle:环形缓冲区、分区、排序(可能存在combiner)、溢写、溢写文件的合并(可能存在combiner)
- reduce端的shuffle:map输出中对应分区的copy、分区的合并

