
- 1Ubuntu20.04网络&&网络源配置_ubuntu如何安装networking服务的源
- 2想学编程,但不知道从哪里学起,应该怎么办?
- 3【nginx实战】通过nginx实现http 长连接(即keep alive)_nginx启用长连接
- 4python基于影像Dicom标签,计算患者年龄_mri数据预测大脑年龄python
- 5DPlayer视频播放器使用方法介绍
- 6Linux宝塔详细使用教程_宝塔如何找ssh文件
- 7内网渗透之Windows反弹shell(一)_windows命令行反弹shell
- 8【计算机毕设任务书】基于VUE框架的点餐系统设计与实现_点餐系统任务书
- 9炸裂!谷歌深夜开源最强大模型Gemma!完虐LLaMA 2!
- 10讨论开源软件影响力
Python实现异步的三种方法_python 异步
赞
踩
目录
之前学习的爬虫都是一条线性的流水线形式,为了提高效率,可以使用异步爬虫,异步爬虫有以下几种方式:
- 多线程
- 多进程
- 协程
一、线程与进程
操作系统在运行程序时会开辟一块内存,这个区域可以称为“xxx进程”,进程里面则有一个个线程
进程好比一个资源单位(公司资源),而线程是一个执行单位(员工干活),CPU执行时跑的都进程里的一个个线程,每个进程至少一个线程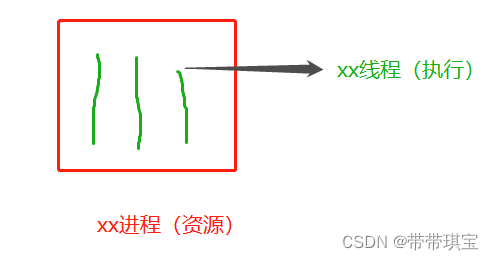
一般启动程序之后都会有一个主线程
(一)单线程
- def func():
- for i in range(5):
- print('i:',i)
-
- if __name__=='__main__':
- func()
- for k in range(5):
- print('k:',k)
-
- i: 0
- i: 1
- i: 2
- i: 3
- i: 4
- k: 0
- k: 1
- k: 2
- k: 3
- k: 4

顺序:一个单线程序
- 定义一个 func() 函数
- 执行 func()
- 执行 k 的 for 循环
(二)多线程
实现多线程的方式:
写法1
导入threading 包的 Tread 模块,这是一个线程的类,通过将这个类实例化得到一个新的线程,如下:
- # 多线程
- # ---------------1.使用Thread----------------
- from threading import Thread # 线程的类
- def func():
- for i in range(5):
- print('i:',i)
-
- if __name__=='__main__':
- # 创建一个线程类的对象,target告诉程序当前线程执行谁,安排好任务
- t=Thread(target=func)
- # 多线程状态为可以开始执行了,具体执行时间由CPU决定
- t.start()
- for k in range(5):
- print('k:',k)
执行过程可以这样示意:
这里 t.start() 的功能: 将多线程状态为可以开始执行了,但具体执行时间由CPU决定,所以执行出如下结果,结果是混乱的,对比一下
- i: 0
- i: 1
- i: 2
- i: 3
- i: 4
- k: 0
- k: 1
- k: 2
- k: 3
- k: 4
-
- i:k: 00
- i:
- k: 1
- 1k:
- 2i:
- k:2
- i:3
- k: 4
- 3
- i: 4
这是由于主线程和新的线程同时在控制台进行 print() 一起运行造成的,但至少在此时我们知道 Python 如何编写多线程了
写法2
方法重写:定义一个方法,继承 Thread 类,里面有个 run() 方法,对其重写
- # --------------2.方法重写------------------
- from threading import Thread # 线程的类
-
- class MyThread(Thread):
- def run(self): # 继承Thread类,重写run方法
- for i in range(5):
- print('i',i)
-
- if __name__=='__main__':
- t=MyThread()
- t.start() # 开启线程,不能是t.run(),这样会直接调用run(),变成单线程
- for k in range(5):
- print('k',k)
结果也是一样,且每次运行结果都不同
(三)多进程
开辟进程由于需要开辟内存,消耗的资源会比多线程消耗多很多,逻辑和多线程的两种写法是一致的
- from multiprocessing import Process
-
- def func():
- for i in range(1000):
- print('进程B', i)
-
- if __name__ == '__main__':
- p = Process(target=func)
- p.start()
- for k in range(1000):
- print('进程A', k)
二、线程池与进程池
(一)线程池
一次性开辟一些线程,我们用户直接给线程池提交任务,任务如何调度不需要去在意,由线程池处理
导入线程池与进程池
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor 线程池在 Python 里的写法:
先创建一个任务
- def mission(name): # 设置一个任务,需传一个参数name
- for i in range(10000): # 模拟线程执行过程
- print(name, i)
任务准备完毕,启动程序:
- # 任务准备完毕,启动程序
- if __name__ == '__main__':
- with ThreadPoolExecutor(50) as t:
- # 创建线程池,由50个线程组成的线程池
- for k in range(100):
- t.submit(mission, name='线程%s' % k)
- # 100个任务给线程池执行,向线程池提交mission任务,并像每个任务传入name参数
(二)进程池
逻辑与线程池类似,将 ThreadPoolExecutor 更改为 ProcessPoolExecutor 即可
三、协程
如 time.sleep() 时,操作如 input() 用户输入前,requests.get()等待请求返回数据前,程序也会处于阻塞状态,一般情况下,当程序处于IO操作时,线程都会处于阻塞状态,CPU是不在此工作的
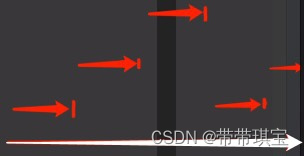
协程:如上图,白色为时间轴,当程序遇见IO操作的时候,可以选择性地切换到其他任务上(类似if-else),以这种形式提高CPU利用率,宏观上看就是多个任务一起执行(多任务异步操作)
上述一切均限定与单线程条件下
(一)async
先写一个函数,在最前面加一个 async 修饰,得到一个异步协程函数,此时函数是一个协程对象,需要借助 asyncio 库支持,以运行这个对象(函数内部代码不会直接执行)
- async def func():
- print('hello')
-
- if __name__ == '__main__':
- print(func())
-
- -----
- <coroutine object func at 0x0000019DDDD1D3C0>
-
- 运行结果是报错
(开辟了一个内存存放这个协程对象)
- import asyncio
-
- async def func():
- print('hello')
-
- if __name__ == '__main__':
- asyncio.run(func())
-
- -----
- hello
此时可以成功运行,但目前只有单个任务,效率变化不大,则写三个函数
如下:
- async def func1():
- print('你好')
- time.sleep(3)
- print('你不好')
-
- async def func2():
- print('我好')
- time.sleep(5)
- print('我不好')
-
- async def func3():
- print('大家好')
- time.sleep(7)
- print('大家不好')
-
- if __name__ == '__main__':
- t1=time.time()
- f1=func1()
- f2=func2()
- f3=func3()
- mission=[f1,f2,f3]
- asyncio.run(asyncio.wait(mission))
- # wait可以让协程加入事件循环中等待被调度执行,以异步协程的方式启动多个任务
- t2=time.time()
- print(t2-t1)
-
- ----------
- 大家好
- 大家不好
- 我好
- 我不好
- 你好
- 你不好
- 15.002882957458496
耗时15s多,异步的操作却跑出了同步的效果,这是因为sleep()这个同步操作中断了异步行为
修改代码,将 time.sleep() 修改为 await asyncio.sleep(),asyncio.sleep() 是异步操作,前面 await 意思是将这个 sleep() 任务挂起,再将其他任务切到CPU上来,一般 await 后面跟着协程对象、task对象、feature对象等
挂起之后在睡眠时就会进行切换了,requests.get() 同理
注:在未来的版本里需通过asyncio.create_task(协程对象)的方式创建 Task 对象
- async def func1():
- print('你好')
- # time.sleep(3)
- await asyncio.sleep(3)
- print('你不好')
-
- async def func2():
- print('我好')
- # time.sleep(5)
- await asyncio.sleep(5)
- print('我不好')
-
-
- async def func3():
- print('大家好')
- # time.sleep(7)
- await asyncio.sleep(7)
- print('大家不好')
-
-
- if __name__ == '__main__':
- t1=time.time()
- f1=func1()
- f2=func2()
- f3=func3()
- mission=[f1,f2,f3]
- # wait可以让协程加入事件循环中等待被调度执行,以异步协程的方式启动多个任务
- asyncio.run(asyncio.wait(mission))
- # run()创建一个事件循环,并以事件mission为程序的主入口,执行完毕后关闭事件循环
- t2=time.time()
- print(t2-t1)
-
- ----------
- 我好
- 大家好
- 你好
- 你不好
- 我不好
- 大家不好
- 7.0032734870910645
更多关于异步详细的介绍:
Python多任务—协程(asyncio详解) 一_asyncio.wait_xiaoming0018的博客-CSDN博客
Python 协程 & 异步编程 (asyncio) 入门介绍_asyncio.wait_linmeiyun的博客-CSDN博客
(二)写法
一般异步协程不直接写在主线程里,会导致任务非常多,如何修改?
写一个任务的主函数,在外部调用直接调用主函数
- async def main():
- # 让几个函数跑起来,
- # 写法
- tasks=[asyncio.create_task(func1()),
- asyncio.create_task(func2()),
- asyncio.create_task(func3())]
- # 将协程对象拿过来创建task任务
- await asyncio.wait(tasks)
- # wait()将任务装入事件循环,await挂起
- pass
主程序运行调用
- if __name__ == '__main__':
- t1 = time.time()
- asyncio.run(main())
- t2 = time.time()
- print(t2-t1)
- pass
-
- ----------
- 你好
- 我好
- 大家好
- 你不好
- 我不好
- 大家不好
- 7.003274202346802

