
- 1苍穹外卖-day12 - 工作台 - Apache POI - 导出运营数据Excel报表
- 2航空公司业务问题分析_late aircraft delay
- 3如何简单区分Python多进程与多线程_arcpy多线程
- 4开源,是RTOS的解药?
- 5在Shell中,“$“和“&“的作用_shell &
- 6【数据结构】--- 二叉树的递归遍历和非递归遍历【C语言实现】_c语言二叉树的非递归遍历
- 7锐捷交换机配置命令大全_思科交换机配置命令大全 01
- 8java多态
- 9【NLP】从WE、ELMo、GPT到Bert模型—自然语言处理中的预训练技术发展史_wegpt
- 10InternLM春节训练营笔记- L2轻松玩转书生浦语大模型趣味Demo
ECCV2022|腾讯优图开源DisCo:拯救小模型在自监督学习中的效果
赞
踩
作者丨Linz@知乎 (已授权)
来源丨https://zhuanlan.zhihu.com/p/366819594
编辑丨极市平台
导读
本文通过解读DisCo,一种基于蒸馏的轻量化模型的自监督学习方法,解释作者如何实现从Teacher到Student更有效的知识迁移,进而显著提升轻量化模型的效果。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
前言

该论文已被 ECCV 2022 录用!
论文链接:https://arxiv.org/pdf/2104.09124.pdf
代码实现:https://github.com/Yuting-Gao/DisCo-pytorch
Motivation
自监督学习通常指的模型在大规模无标注数据上学习通用的表征,迁移到下游相关任务。因为学习到的通用表征能显著提升下游任务的性能,自监督学习被广泛用于各种场景。通常来讲,模型容量越大,自监督学习的效果越好 [1,2]。反之,轻量化的模型(EfficientNet-B0, MobileNet-V3, EfficientNet-B1) 在自监督学习上效果就远不如容量相对大的模型 (ResNet50/101/152/50*2)。
目前提升轻量化模型在自监督学习上性能的做法主要是通过蒸馏的方式,将容量更大的模型的知识迁移给学生模型。SEED [2]基于MoCo-V2框架 [3,4],容量大的模型作为Teacher,轻量化模型作为Student,共享MoCo-V2框架中负样本空间(Queue),通过交叉熵迫使正样本与相同的负样本在Student与Teacher空间中的分布尽可能相同。CompRess [1]还尝试了Teacher和Student维护各自的负样本空间,同时使用KL散度来拉近分布。以上方法可以有效的将Teacher的知识迁移给Student,从而提升轻量化模型Student的效果(本文会交替使用Student与轻量化模型)。
本文提出了Distilled Contrastive Learning (DisCo),一种简单有效的基于蒸馏的轻量化模型的自监督学习方法,该方法可以显著提升Student的效果并且部分轻量化模型可以非常接近Teacher的性能。该方法有以下几个观察:
基于自监督的蒸馏学习,因为最后一层的表征包含了不同样本的在整个表征空间中的全局的绝对位置和局部的相对位置信息,而Teacher中的这类信息比Student更加的好,所以直接拉近Teacher与Student最后一层的表征可能是效果最好。
在CompRess [1] 中,Teacher 与 Student 模型共享负样本队列(1q) 与拥有各自负样本队列(2q) 差距在1%内。该方法迁移到下游任务数据集CUB200, Car192,该方法拥有各自的负样本队列甚至可以显著超过共享负样本队列。这说明,Student并没有从Teacher共享的负样本空间学习中获得足够有效的知识。Student不需要依赖来自Teacher的负样本空间。
放弃共享队列的好处之一,是整个框架不依赖于MoCo-V2,整个框架更加简洁。Teacher/Student 模型可以与其他比MoCo-V2更加有效的自监督/无监督表征学习方法结合,进一步提升轻量化模型蒸馏完的最终性能。
目前的自监督方法中,MLP的隐藏层维度较低可能是蒸馏性能的瓶颈。在自监督学习与蒸馏阶段增加这个结构的隐藏层的维度可以进一步提升蒸馏之后最终轻量化模型的效果,而部署阶段不会有任何额外的开销。将隐藏层维度从512->2048,ResNet-18可以显著提升3.5%。
Method
本文提出一个简单却很有效的框架 Distilled Contrastive Learning (DisCo) 。Student 会同时进行自监督学习和学习相同的样本在Teacher的表征空间中分布。
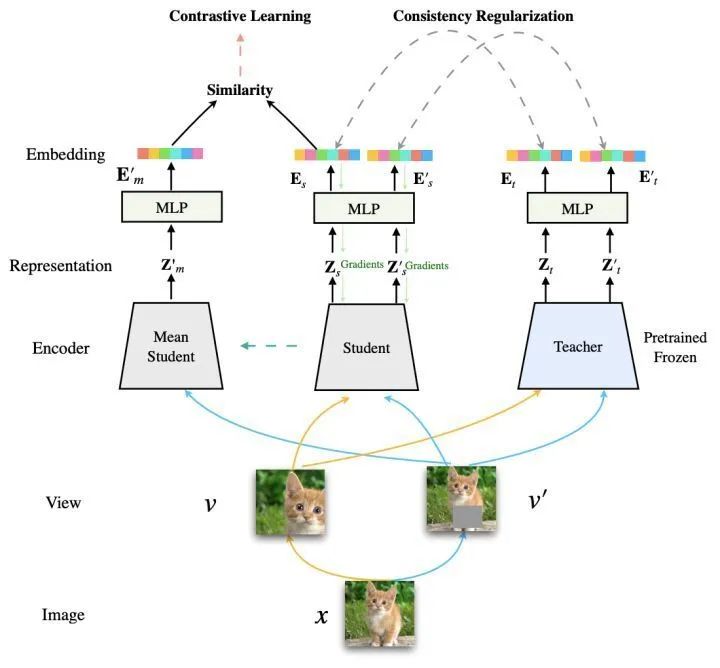
如上图所示,通过数据增广 (Data Augmentation) 操作将图像生成为两个视图 (View)。除了自监督学习,还引入一个自监督学习获得的Teacher模型。要求相同样本的相同视图,经过Student和固定参数的Teacehr的最终表征保持一致。在本文的主要实验中,自监督学习基于MoCo-V2 (Contrastive Learning),而保持相同样本通过Teacher与Student的输出表征的表征相似是通过一致性正则化(Consistency Regularization)。本文采用均方误差来使Student学习到样本在对应Teacher空间中的分布。
Experiments
此处我们列出一些重要的实验结果。
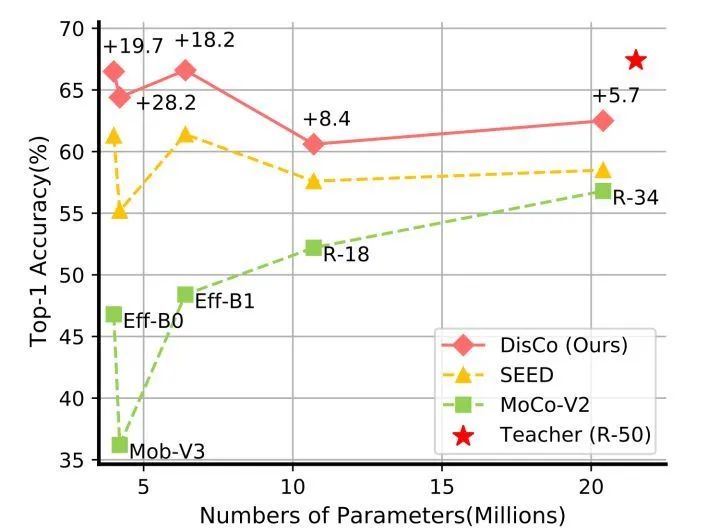
在上图,DisCo 大大超出了轻量化模型(EfficientNet-B0, MobileNet-V3, Efficient-B1, ResNet18, ResNet34)直接使用MoCo-V2的自监督学习得到的效果,并且超越了SOTA(SEED)。特别值得注意的是,EfficientNet-B0的结果非常接近作为Teacher的ResNet-50,而EfficientNet-B0的参数仅为ResNet-50的16.3%。
除了与SOTA对比,我们还从以下几个方面的实验来验证DisCo的有效性:
表征泛化能力
迁移到下游分类任务:Cifar10/100
迁移到检测/分割任务:VOC07,COCO2012
DisCo相比已有蒸馏方法,能更好的拉近Teacher与Student的表征分布。同时,与已有的蒸馏方法结合,能进一步提升蒸馏效果
半监督学习下的表现
消融实验:两部分损失函数的影响
其他实验:
Teacher采用其他的自监督学习方法的影响,包括CNN/Transformer 差异的影响
Student/Teacher同时采用其他的自监督学习方法的影响
除此之外,本文还从分析了MLP隐藏层维度的影响,使用IB理论进一步分析隐藏层的维度可以有效提升方法轻量化模型性能的原因。详情可见论文链接。
Visualization
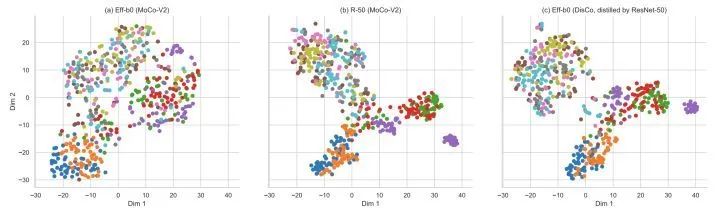
本文还可视化了相同样本在 经过MoCo-2得到的EfficientNet-B0, 经过MoCo-V2得到的ResNet-50,以及本文的方法得到的EfficientNet-B0的表征。可以观察到ResNet-50形成比EfficientNet-B0更多的分离簇,单独使用MoCo-V2,本文的方法得到的EfficientNet-B0有更清晰的分离簇,也与ResNet-50更接近。
Conclusion
针对怎么缓解轻量化的模型在自监督任务上性能远不如容量大的模型的现象,本文通过知自监督学习和知识蒸馏,约束轻量级模型Student的输出表征与容量大的模型Teacher的输出表征在空间上尽量相近。该方法可以不依赖特定的自监督方法。特别是,当ResNet101 / ResNet-50被用作教师,EfficientNet-B0在ImageNet上的 Linear Evaluation 结果非常接近ResNet-101 / ResNet-50,但EfficientNet-B0的参数量仅为ResNet101 / ResNet-50的9.4%/ 16.3%。
References
Soroush Abbasi Koohpayegani, Ajinkya Tejankar, and Hamed Pirsiavash. Compress: Self-supervised learning by compressing representations. In NeurIPS, pages 12980– 12992, 2020.
Zhiyuan Fang, Jianfeng Wang, Lijuan Wang, Lei Zhang, Yezhou Yang, and Zicheng Liu. Seed: Self-supervised distillation for visual representation. In ICLR, 2021.
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, pages 9729–9738, 2020.
Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. In CVPR, pages 9729–9738, 2020.
Hao Cheng, Dongze Lian, Shenghua Gao, and Yanlin Geng. Evaluating capability of deep neural networks for image classification via information plane. In ECCV, pages 168–182, 2018.
本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
计算机视觉工坊精品课程官网:3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

