
- 1winsock教程- windows下的socket编程(c语言实现)_c语言winsock
- 2SVM算法(Support Vector Machine)
- 3Linux下的版本控制系统——Git:初学者指南
- 4centos8拉取nginx最新版本到本地
- 5信息安全--一: 绪言_对计算机系统的硬摧毁主要手段有
- 6CleanMyMac2024许可证激活码激活步骤教程_mycleanmymac 激活号码
- 7计算机网络涉及的思维导图,真的太详细了,收藏!_计算机网络思维导图
- 8Linux密码忘了怎么办!_linux忘记密码
- 9Python----科学计数法、同时给多个变量赋值、eval函数、math库函数、复数(complex())、内置的数值运算函数、内置的数值运算操作符_python科学计数法
- 10Webdriver常用及基础方法_webdriver用法
嵌入式linux mysql_嵌入式linux 项目开发(一)——SQLite数据库
赞
踩
嵌入式linux项目开发(一)——SQLite数据库
一、SQLite数据库简介
SQLite是一个开源的嵌入式关系数据库,是一种轻量级的、自给自足的、无服务器的、无需配置的、事务性的SQL数据库引擎,其特点是高度便携、使用方便、结构紧凑、高效、可靠,体积小,支持ACID(原子性、一致性、独立性及持久性Atomicity、Consistency、Isolation、Durability)事物。
SQLite数据库采用模块化设计,由8个独立的模块构成,构成三个主要的子系统。SQLite的基本架构:
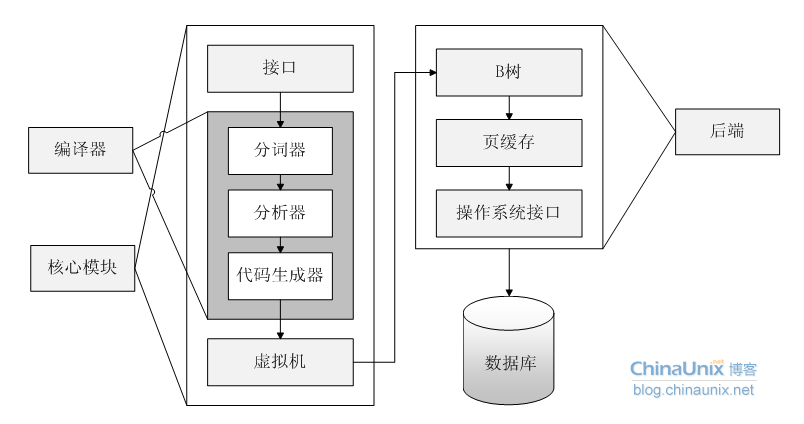
sqlite主要由8个构件子系统(模块)组成,分为两部分:前端解析系统和后端引擎。
前端:
前端预处理应用程序传递过来的SQL语句和SQLite命令。对获取的编码分析、优化,转换为后端能够执行的SQLite内部字节编码并执行。前端可分为5个模块:
A、接口(Interface)
所有的SQLite API命名以sqlite3_为前缀,接收SQL语句和sqlite命令
B、标识分析(Tokenizer)
tokenizer是负责把SQL语句解析为一个个的“串”,将输入的SQL语句分成标识符。
C、语法分析(Parser)
Paser根据tokenizer分割的“串”的前后序列关系来生成相应的语法结构。解析器分析通过标识器产生的标识分析语句的结构,并且得到一颗语法树。解析器同时也包含了重构语法树的优化器,因此能够找到一颗产生一个高效的字节编码程序的语法树。
D、代码生成器(Code Generator)
代码生成器遍历语法树,并且生成一个等价的字节编码程序,生成Virtual Machine可以执行的高效代码
E、虚拟机(VM)
虚拟机(Virtual Machine)是为操作数据库文件而执行的一个抽象的计算机引擎。VM模块是一个内部字节编码语言的解释器,通过执行Code Generator 生成的代码字节编码语句来实现SQL语句的工作,是数据库中数据的最终的操作者。虚拟机把数据库看成表和索引的集合,而表和索引则是一系列的元组或者记录。
后端:
后端是用来解释字节编码程序的引擎,实现数据库处理工作。后端部分由3个模块组成:
A、B/B+树
SQLite数据库文件在磁盘中是以B树的数据结构存储。B树结构,用于存储数据库到磁盘,可以通过减少磁盘的查找来达到快速访问数据的目的。B/B+树模块把每一个元组集组织进一个一次排好序的树状数据结构中,表和索引被分别置于单独的B+和B树中,帮助VM进行搜索,插入和删除树中的元组,帮助VM创建新的树和删除旧的树。
B、页面调度程序(pager)
页面调度程序模块在原始文件的上层实现了一个面向页面的数据库文件抽象,用来管理B/B+树使用的内存内缓存(数据库页的),也管理文件的锁定,并用日志来实现事物的ACID属性。页面缓冲主要处理读、写以及B树存储机制所需的数字缓冲,包括为了保证事务原子性的回退及提交操作所需的缓冲。
C、操作系统接口(system interface)
操作系统接口模块提供了对应于不同本地操作系统的统一接口,操作系统接口主要是为了方便在不同平台的操作而执行的一个底层与操作系统有关的抽象层。
后端实现了sqlite3_bind_*,sqlite3_setp,sqlite3_coloumn_*,sqlite3_reset和sqlite3_finalize API函数。
SQLite体系结构的核心是虚拟数据库引擎(VDBE)。VDBE完成与数据库操作相关的全部操作并且是客户和存储之间信息进行交互的中间单元。在SQL语句被分析之后,代码生成器将分析树翻译成一个袖珍程序,袖珍程序又被组合成用VDBE的虚拟机器语言表示的一系列指令。VDBE执行每条指令,最终完成SQL语句指定的查询请求。
二、SLQite数据库移植
1、下载SQLite源码
tar -zxvf sqlite-amalgamation-3.6.1.tar.gz
2、配置
进入SQLite源码工程顶层目录sqlite-auto,新建安装sqlite-arm目录,执行配置脚本
mkdir sqlite-arm
./configure --host=arm-linux --prefix=/home/opensource/sqlite-auto/sqlite-arm/
--host: 指定交叉编译工具,一般为arm-linux、arm-none-linux-gnueabi等,具体要和板子用的交叉编译工具对应。
--prefix: 指定安装目录,编译后的文件会全部放在安装目录中。必须是绝对路径
3、编译、安装
make & make install
4、去除调试信息
使用arm-linux-strip去除sqlite-arm目录下的bin目录和lib目录下的文件的调试信息,即去除需要移植到开发板的文件的调试信息,节省空间
5、sqlite3移植
将sqlite-arm目录下的bin目录下的sqlite3程序拷贝到开发板/usr/bin目录
将sqlite-arm目录下的lib目录下的所有文件拷贝到开发板/lib目录或/usr/lib目录
三、SQLite移植过程中错误的解决
将sqlite移植到开发板后,执行sqlite3,报错:-/bin/sh: sqlite3: not found
解决方案:将交叉编译工具的动态链接库拷贝到开发板/lib或/usr/lib
查看sqlite3所依赖的动态链接库,readelf -d sqlite3
0x00000001 (NEEDED) Shared library: [libdl.so.2]
0x00000001 (NEEDED) Shared library: [libpthread.so.0]
0x00000001 (NEEDED) Shared library: [libgcc_s.so.1]
0x00000001 (NEEDED) Shared library: [libc.so.6]
发现sqlite3依赖四个动态链接库文件,需要将这四个动态链接库文件(如果有链接文件,包括链接文件所指向的文件)拷贝到开发板/lib或/usr/lib。如果开发板存储空间允许,可以将交叉编译工具链的所有动态链接库文件拷贝到开发板。
注意所有对开发板的移植必须包括ARM交叉编译工具链的动态链接库,否则将会报错-/bin/sh: xxxx: not found
四、SQLite SQL语句
1、sqlite命令
创建或打开一个数据库:sqlite3 dbname.db(所在目录必须具有读写权限)
版本查看:sqlite3 -version
创建数据库:sqlite3 xxxx.db
退出sqlite命令行:.quit或.exit或.q
列出当前显示格式的配置:.show
查看数据库中的表:.tables
显示表结构:.schema
退出数据库:ctrl+d
.dump:生成整个数据库的脚本在终端显示.outputstdout:将输出打印到屏幕.output filename:导出数据库到SQL文件
.read filename:从SQL文件导入数据库
.outputfilename.csv:格式化输出数据到CSV格式
.import [filename.csv ] newtable:从CSV文件导入数据到表中
sqlite3 [database] .dump > [filename]:备份数据库实例:sqlite3 mytable.db .dump > backup.sql
sqlite3 [database ] < [filename ]:恢复数据库实例:sqlite3 mytable.db < backup.sql
2、字段类型
NULL: 空值
INTEGER: 整数,依据值的大小可以依次被存储为1,2,3,4,5,6,7,8个字节
REAL: 所有值都是浮动的数值,被存储为8字节的IEEE浮动标记序号
TEXT: 文本,值为文本字符串,使用数据库编码存储(TUTF-8, UTF-16BE or UTF-16-LE).
BLOB: 值是BLOB数据,如何输入就如何存储,不改变格式
SQL语句中部分的带双引号或单引号的文字被定义为文本,如果文字没带引号并没有小数点或指数则被定义为整数,如果文字没带引号但有小数点或指数则被定义为实数,如果值是空则被定义为空值,BLOB数据使用符号X'ABCD'来标识。
smallint 16位的整数。
interger 32位的整数。
decimal(p,s) 精确值p是指全部有几个十进制数,s是指小数点后可以有几位小数。如果没有特别指定,则系统会默认为p=5 s=0。
float 32位元的实数。
double 64位元的实数。
char(n) n 长度的字串,n不能超过254。
varchar(n) 长度不固定且其最大长度为n的字串,n不能超过4000。
graphic(n) 和char(n)一样,不过其单位是两个字节,n不能超过127。这个形态是为了支持两个字节长度的字体,如中文字。
vargraphic(n) 可变长度且其最大长度为n的双字元字串,n不能超过2000
date 包含了 年份、月份、日期。
time 包含了 小时、分钟、秒。
timestamp 包含了 年、月、日、时、分、秒、千分之一秒。
3、表操作
建立表
create table table_name(field type1,fieldtype1,….);
table_name是要创建数据表的名称,field是数据库表内字段名字,type则是字段类型。例如:
CREATE TABLEstudent(
ID INTEGER PRIMARY KEY,
LastName varchar(255),
FirstName varchar(255)
);
删除表
DROP TABLE tableName;
查看表
SELECT * FROM tablename WHERE someField = 'value' COLLATE NOCASE;
4、字段操作
A、向表中添加新记录
insert intotabelnamevalues (value1, value2,…);
实例:
insert into people values(1,'A',10);
insert into people values(2,'B',13);
insert into people values(3,'C',9);
insert into people values(4,'C',15);
insert into people values(5,NULL,NULL);
字符串要用单引号括起来
B、查询表中所有记录
select * fromtablename;
实例:select * from people;
按某个字段查询表中没有重复的条目
SELECT distinct someField FROM table
C、按指定条件查询表中记录
select * fromtablenamewherefield=value;
实例:
在表中搜索名字是A的项所有信息
select * from people where name='A';
在表中搜索年龄>=10并且<=15的项的所有信息
select * from people where age>=10 and age<=15;
在表中搜索名字是C的项,显示其name和age
select name,age from people where name='C';
显示表中的前2项所有信息
select * from people limit 2;
显示以年龄排序表中的信息
select * from people order by age;
D、按指定条件删除表中记录
delete from where
实例:
删除表中名字是'C'的项
delete from pople where name='C';
E、更新表中记录
update set , … where ;
实例:
将表中年龄是15并且ID是4项,名字改为CYG
update people set name='CYG' where id=4 and age=15;
用一张表TableB里的一个字段fieldB内容给另外一张表TableA里的一个字段fieldA赋值:
UPDATE TableA SET fieldA = TableB.fieldB
如果是同一张表TableA中,用一个字段field1的值给表中的另外一个字段field2值赋值:
UPDATE TableA SET field2 = field1
如果需要把一个字符串('someString')和一个字段field1的值进行连接,然后赋值给一个字段field2:
UPDATE TableA SET field2 = field1 || 'someString'
F、在表中添加字段
alter table add column ;
实例:
在people表中添加一个addr字段
alter table people add column addr;
G、删除表中的一个字段
删除people表中字段addr,操作流程如下:
将people表重命名为temp
重新创建people表
将temp表中的相应字段内容复制到people表中
删除temp表
SQL语句如下:
alter table people rename to temp;
create table people(id,name,age);
insert into people select id,name,age from temp;
drop tabletemp;
H、表的导入
把一张表TableA里的数据导入到另外一张表TableB中(两张表中的结构和字段必须一样):
INSERT INTO TableB SELECT * FROM TableA
5、分组统计
CREATE TABLE COMPANY(ID INT NOT NULL, NAME VARCHAR(20),AGE INT,ADDRESS VARCHAR(20),SALARY DECIMAL(7,2));
GROUP BY 进行分组统计数据,命令如下:
SELECT NAME, SUM(SALARY) SALARY_SUM, COUNT(1) COUNT_NUM FROM COMPANY GROUP BY NAME;
6、排序
ORDER BY 进行排序,命令如下:
SELECT NAME, SUM(SALARY) SALARY_SUM, COUNT(1) COUNT_NUM FROM COMPANY GROUP BY NAME ORDER BY SALARY_SUM ASC;
7、从excel表中导入数据
A、将Excel之中存储的数据另存为csv的格式bookroom.csv,注意不要带表头,只要数据就行
B、根据要导入的表属性创建表
create table bookroom(id integer, roomname nvarchar(20), mapfilename nvarchar(20));
C、设置数据的分隔符
.separator ',';
D、将数据导入表
.import bookroom.csv bookroom
.import
E、查阅插入的数据
select * from bookroom;
五、SQLite数据库编程
SQLite数据库编程最常用到的是sqlite3 *类型。从数据库打开开始,sqlite就要为sqlite3 *类型准备好内存,直到数据库关闭,整个过程都需要用到sqlite3 *类型。当数据库打开时开始,sqlite3 *类型的变量就代表了要操作的数据库,即句柄。
1、sqlite3_open
int sqlite3_open(char *path,sqlite3 **db);
功能:打开sqlite数据库
path:数据库文件路径(如果不存在,则创建)
db:指向sqlite句柄的指针
返回值:如果是SQLITE_OK则表示操作正常。其他的返回值参考sqlite3.h文件定义的宏。
2、sqlite3_close
int sqlite3_close(sqlite3 *db);
功能:关闭sqlite数据库
放回值:成功返回0,失败返回错误码
3、sqlite3_errmsg
const char *sqlite3_errmsg(sqlite3 *db);
返回值:返回错误信息
4、执行SQL语句
typedef int (*sqlite3_callback)(void *, int ,char **, char **);
int sqlite3_exec(sqlite3 *db , const char *sql ,
sqlite3_callback callback ,void *arg, char **errmsg );
db参数是前面sqlite3_open函数得到的指针
sql参数是一条字符串格式sql语句,以\0结尾。
callback参数是回调函数,当这条语句执行之后,sqlite3会去调用你提供的这个函数。
arg参数是可以传递的指针参数,传到回调函数里面,如果不需要传递指针给回调函数,可以填NULL。
errmsg 参数是错误信息。sqlite3里面有很多固定的错误信息。执行sqlite3_exec后,如果执行失败可以查阅这个指针。
返回值:成功返回0,失败返回错误码
如果调用sqlite3_exec失败,printf("%s\n",errmsg)可以得到一串字符串错误信息。
sqlite3_callback callback和void *arg都可以填NULL。NULL表示不需要回调。比如insert操作,delete操作,就没有必要使用回调。而当做select时,就要使用回调,因为sqlite3把数据查出来,得通过回调告诉你查出了什么数据。
typedef int (*sqlite3_callback)(void *para,int n_column,char **column_value,char **column_name);
para参数:传入的特殊指针(比如类指针、结构指针),然后操作指针指向的数据。
n_column:是记录有多少个字段(即记录有多少列)。
char **column_value:是个关键值,查出来的数据都保存在这里,它实际上可以看做是一个一维的指针数组,每个元素都是一个char *值,是一个字段的内容(用字符串来表示,以\0结尾)。
char **column_nam:跟column_value是对应的,表示这个字段的字段名称 。
程序实例sqlite3_callback.c:#include
#include
#include
#include
#define MAX 100
typedef int (*sqlite3_callback)(void *, int , char **, char **);
int show_table_info(void *arg, int n_column, char **column_value, char **column_name)
{
int i = 0;
for(i = 0; i
{
printf("%s\t", column_name[i]);
}
printf("\n*************************************\n");
for(i = 0; i
{
printf("%s\t", column_value[i]);
}
printf("\n\n");
return 0;
}
int exec_sql_string(char *sql_string, sqlite3 *db)
{
char *errmsg;
if(sqlite3_exec(db, sql_string, show_table_info, NULL, &errmsg) != 0)
{
fprintf(stderr, "Fail to exec sql(%s) : %s.\n", sql_string,errmsg);
return -1;
}
return 0;
}
int main(int argc,char *argv[])
{
sqlite3 *db;
int result;
char sql_buf[MAX];
if(argc
{
fprintf(stderr, "usage : %s argv[1].\n", argv[0]);
exit(EXIT_FAILURE);
}
result = sqlite3_open(argv[1], &db);
if(result != SQLITE_OK)
{
fprintf(stderr, "Fail to sqlite3_open %s : %s.\n", argv[1], sqlite3_errmsg(db));
exit(EXIT_FAILURE);
}
while(1)
{
printf("sqlite >");
fgets(sql_buf, sizeof(sql_buf), stdin);
sql_buf[strlen(sql_buf) - 1] = '\0';
if(strncmp(sql_buf, ".quit", 5) == 0)
break;
exec_sql_string(sql_buf,db);
}
result = sqlite3_close(db);
if(result != 0)
{
fprintf(stderr, "Fail to sqlite3_open %s : %s.\n", argv[1], sqlite3_errmsg(db));
exit(EXIT_FAILURE);
}
exit(EXIT_SUCCESS);
}
编译:gcc -o sqlite3_callback sqlite3_callback.c -lsqlite3
5、不使用回调函数执行SQL语句
int sqlite3_get_table(sqlite3 *db, const char *sql, char ***resultp,
int *nrow, int *ncolumn,char **errmsg);
功能:执行sql操作
db : 数据库句柄
sql : sql语句
resultp : 用来指向sql执行结果的指针
nrow : 满足条件的记录的数目
ncolumn : 每条记录包含的字段数目
从第0索引到第ncolumn-1索引都是字段的名称
从第ncolumn索引开始,后面都是字段的值
errmsg : 错误信息指针的地址
返回值:成功返回0,失败返回错误码
程序实例sqlite3_nocallback.c:#include
#include
#include
#include
#define MAX 100
int exec_sql_string(char *sql_string, sqlite3 *db)
{
char *errmsg, **dbResult;
int nRow, nColumn;
int result, i, j, index;
result = sqlite3_get_table(db, sql_string, &dbResult, &nRow, &nColumn, &errmsg);
if(0 != result)
{
fprintf(stderr, "Fail to exec sql(%s) : %s.\n", sql_string, errmsg);
return -1;
}
//字段名字
for(j = 0; j
{
printf("%s\t", dbResult[j]);
}
printf("\n");
index = nColumn;//从它开始是字段对应的值
for(i = 0; i
{
for(j = 0; j
{
printf("%s\t", dbResult[index]);
index++;
}
printf("\n");
}
//释放查询结果所分配的内存
sqlite3_free_table(dbResult);
return 0;
}
int main(int argc, char *argv[])
{
sqlite3 *db;
int result;
char sql_buf[MAX];
if(argc
{
fprintf(stderr, "usage : %s argv[1].\n", argv[0]);
exit(EXIT_FAILURE);
}
result = sqlite3_open(argv[1], &db);
if(result != SQLITE_OK)
{
fprintf(stderr, "Fail to sqlite3_open %s : %s.\n", argv[1], sqlite3_errmsg(db));
exit(EXIT_FAILURE);
}
while(1)
{
printf("sqlite >");
fgets(sql_buf, sizeof(sql_buf), stdin);
sql_buf[strlen(sql_buf) - 1] = '\0';
if(strncmp(sql_buf,".quit",5) == 0)
break;
exec_sql_string(sql_buf, db);
}
result = sqlite3_close(db);
if(result != 0)
{
fprintf(stderr, "Fail to sqlite3_open %s : %s.\n", argv[1], sqlite3_errmsg(db));
exit(EXIT_FAILURE);
}
exit(EXIT_SUCCESS);
}
编译: gcc -o sqlite3_nocallback sqlite3_nocallback.c -lsqlite3

