
- 1详解Linux内核态调试工具kdump
- 2leecode-C语言实现-11. 盛最多水的容器_c语言最大容器
- 3Java IO流学习总结三:缓冲流-BufferedInputStream、BufferedOutputStream_java.io.bufferedinputstream process
- 4【项目实战】SpringBoot项目在外部tomcat环境下部署(如何基于SpringBoot将项目打包成war包,并且部署到tomcat中)_tomcat部署spring项目
- 5【C语言】自定义类型之 --- 结构体(重要~)_struct 包含自身
- 6Paper:《Graph Neural Networks: A Review of Methods and Applications—图神经网络:方法与应用综述》翻译与解读
- 7享受更舒适健康的坐姿,让工作学习更轻松,永艺XY椅月光骑士体验
- 8walden_peeping chinese
- 9【华为OD机试 2023最新 】 硬件产品销售方案(C++ 100%)_华为 机试 2023 site:csdn.net
- 102022年美赛C题 翻译+题意理解_2022美赛c题
【论文翻译】Few-Shot Object Detection via Classification Refinement and Distractor Retreatment_通过分类精炼和干扰样本重处理进行少样本目标检测
赞
踩
Few-Shot Object Detection via Classification Refinement and Distractor Retreatment
基于分类细化和干扰物再处理的少样本目标检测
论文地址:CVPR 2021 Open Access Repository
1 摘要
We aim to tackle the challenging Few-Shot Object Detection (FSOD), where data-scarce categories are presented during the model learning. The failure modes of Faster-RCNN in FSOD are investigated, and we find that the performance degradation is mainly due to the classification incapability (false positives) caused by category confusion, which motivates us to address FSOD from a novel aspect of classification refinement. Specifically, we address the intrinsic limitation from the aspects of both architectural enhancement and hard-example mining. We introduce a novel few-shot classification refinement mechanism where a decoupled Few-Shot Classification Network (FSCN) is employed to improve the final classification of a base detector. Moreover, we especially probe a commonly-overlooked but destructive issue of FSOD, i.e., the presence of distractor samples due to the incomplete annotations where images from the base set may contain novel-class objects but remain unlabelled. Retreatment solutions are developed to eliminate the incurred false positives. For FSCN training, the distractor is formulated as a semi-supervised problem, where a distractor utilization loss is proposed to make proper use of it for boosting the data-scarce classes, while a confidence-guided dataset pruning (CGDP) technique is developed to facilitate the few-shot adaptation of base detector. Experiments demonstrate that our proposed framework achieves state-of-the-art FSOD performance on public datasets, e.g., Pascal VOC and MS-COCO
我们的目标是解决具有挑战性的少样本目标检测(FSOD),其中数据稀缺的类别是在模型学习过程中提出的。对FSOD中Faster RCNN的失效模式进行了研究,我们发现性能下降主要是由于类别混淆导致的分类失效(误报),这促使我们从一个新的分类细化方面解决FSOD问题。具体来说,我们从架构增强和硬样本挖掘两个方面解决了固有的局限性。我们介绍了一种新的少样本分类细化机制,其中使用解耦的少样本分类网络(FSCN)来改进基本检测器的最终分类。此外,我们还特别探讨了FSOD中一个通常被忽视但具有破坏性的问题,即由于不完整的注释而存在干扰样本,其中来自基集中的图像可能包含新的类目标,但仍然没有标记。制定再治疗方案以消除产生的误报。对于FSCN训练,分心器被描述为一个半监督问题,其中提出了一个分心器利用率损失来适当利用它来提高数据稀缺类,同时开发了一种置信引导数据集剪枝(CGDP)技术来促进基本检测器的少样本自适应。实验表明,我们提出的框架在公共数据集(如Pascal VOC和MS-COCO)上实现了最先进的FSOD性能
介绍
Deep learning based object detection [13, 4, 2] have achieved remarkable performance outperforming traditional approaches [24, 5]. However, deep learning detection relies on the availability of a large number of training samples. In many practical applications such as robotics [22, 23], labeling a large amount of data is often time-consuming and labor-intensive. This paper focuses on a practically desired but rarely explored area, i.e., Few-Shot Object Detection (FSOD). With the aid of data-abundant base classes, the object detector is trained to additionally detect novel classes through very limited samples. Existing approaches are mainly built on top of Faster-RCNN [13]. For example, the current state-of-the-art approach TFA [17] is presented that employs a classifier rebalancing strategy for registering novel classes. During finetuning, the backbone pre-trained on the base set is reused and being frozen, while only the box classifier and regressor are trained with novel data. Despite its’ remarkable progress, its performance on challenging benchmarks such as MS-COCO, is still far away from satisfaction compared with those general data-abundant detection tasks, which deserves more research efforts as dataefficiency is practically preferred in most real-world applications.
基于深度学习的目标检测[13,4,2]取得了显著的性能,优于传统方法[24,5]。然而,深度学习检测依赖于大量训练样本的可用性。在许多实际应用中,如机器人[22,23],标记大量数据往往耗时费力。本文主要关注一个实际需要但很少探索的领域,即少样本目标检测(FSOD)。借助于数据丰富的基类,目标检测器经过训练,可以通过非常有限的样本额外检测新类。现有的方法主要建立在更快的RCNN之上[13]。例如,目前最先进的TFA方法[17]采用了一种分类器再平衡策略来注册新类。在微调过程中,在基集上预先训练的主干被重用并被冻结,而只有盒分类器和回归器使用新数据进行训练。尽管它取得了显著的进步,但与那些数据丰富的常规检测任务相比,它在MS-COCO等具有挑战性的基准上的性能仍然远远不能令人满意,这值得更多的研究工作,因为在大多数实际应用中,数据效率实际上是首选的。
To make a step towards the challenging FSOD task, it crucial to find out the major cause of performance degrada tion in novel classes. Regarding the architecture of Faster-RCNN, its localization branch is typically class-agnostic with satisfactory performance. Thus our insight is to tackle the limitations of the classification branch for FSOD in this work. Specifically, we evaluate TFA from two important aspects on few-shot classes: 1) IOU awareness, i.e., robustness to hard negatives and 2) category discriminability, i.e., robustness to category confusion. Models that are weak in the first aspect often predict poorly localized hard negatives as “confident” foregrounds of the same category, while those that are weak in the second aspect may suffer from classification confusion between categories that share similar visual features or appear in similar contexts. Next, we analyze the potential performance gain by eliminating these two types of errors separately. For example, given the classification of a poorly localized box (e.g., IOU=0.4) from category “dog”, the effect of the first type false positives (objectness error) can be eliminated by erasing the prediction score for its corresponding semantic category “dog”, while scores for other categories are preserved. To eliminate the second type false positives (confusion error), scores for all other categories except “dog” are erased. Results are shown in Fig. 1. For the 10-shot case, eliminating the objectness error only provides 1.7 points performance gain in mAP, while eliminating the confusion error can dramatically boost the performance gain to 8.0 points, which indicates that classification results of TFA is IOU-aware but less discriminative to confusable categories.
为了向具有挑战性的FSOD任务迈进一步,找出新类别中表现下降的主要原因至关重要。关于Faster-RCNN的体系结构,其本地化分支通常是类无关的,具有令人满意的性能。因此,我们的见解是在这项工作中解决FSOD分类分支的局限性。具体来说,我们从两个重要方面评估了少样本类别的TFA:1)IOU意识,即对硬负面的鲁棒性;2)类别辨别性,即对类别混淆的鲁棒性。在第一个方面较弱的模型通常将局部性较差的硬负项预测为同一类别的“自信”前景,而在第二个方面较弱的模型可能会在具有相似视觉特征或出现在相似上下文中的类别之间出现分类混淆。接下来,我们分析了通过分别消除这两种错误而获得的潜在性能增益。例如,考虑到类别“dog”中定位不良的框(例如,IOU=0.4)的分类,可以通过删除对应语义类别“dog”的预测分数来消除第一类误报(目标性错误)的影响,同时保留其他类别的分数。为了消除第二类误报(混淆错误),除“狗”之外的所有其他类别的分数都会被删除。结果如图1所示。对于10-shot的情况,消除目标性错误只会在mAP中提供1.7分的性能增益,而消除混淆错误可以将性能增益显著提高到8.0分,这表明TFA的分类结果具有IOU感知能力,但对可混淆类别的区分性较低。
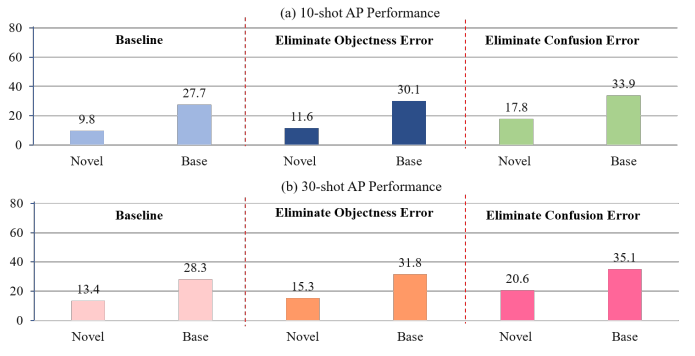
Figure 1. FSOD performance gain by eliminating classification false positives.
图1 FSOD通过消除分类误报来提高性能。
Maintaining IOU-awareness during finetuning is not supervising, as the objectness knowledge gained from a large dataset is usually universal and generalizable, thus can be reliably generalized into unseen novel classes as well. However, lacking inter-class separability often leads to the issue of category confusion. We conjecture possible reasons from the following aspects of architectural limitation: The classification branch of Faster-RCNN based detectors is not purposely designed for few-shot adaptation. For example, the shared feature representation for both classification and localization is shown to be suboptimal for learning category discriminative representations since classification requires translation-invariant features while localization prefers translation-covariant features. Such mismatched learning goals degrade the quality of categoryspecific translation invariance features [4], thus pose a tough challenge to learn discriminative classifiers when samples of novel classes are scarce.
在微调过程中保持IOU意识并不重要,因为从大型数据集中获得的对象性知识通常是通用的和可推广的,因此也可以可靠地推广到看不见的新类中。然而,缺乏类间可分性往往会导致类别混淆的问题。我们从架构限制的以下方面推测可能的原因:基于Faster RCNN的检测器的分类分支不是专门为少样本自适应而设计的。例如,分类和定位的共享特征表示对于学习类别区分性表示是次优的,因为分类需要平移不变特征,而定位偏好平移协变特征。这种不匹配的学习目标会降低类别特定的翻译不变性特征的质量[4],因此在新类别样本稀少的情况下,学习区分性分类器是一个严峻的挑战。
In this work, we propose a unified approach for addressing the above limitation. Given the fact that TFA is IOU-aware but less semantic discriminative, our key insight is to enhance the original classification results by injecting additional category-discriminative information. In this work, a novel Few-Shot Classification Refinement mechanism is proposed to handle both objectness estimation and category discriminability simultaneously. Our framework consists of two branches, named as the “IOU-aware classification branch” and the “discriminability enhancement branch”,which separately perform their efforts on estimating objectness and alleviating category confusion, respectively. As the name suggests, the IOU-aware classification branch is responsible for producing accurate IOU estimation for each object proposal, which is implemented by the original TFA. At the same time, the enhancement branch is designed as a translation-invariant classifier to produce category-discriminative classification results. After that, outputs of these two complementary branches are aggregated together to produce less confused yet IOU-aware confidence.
在这项工作中,我们提出了一种解决上述限制的统一方法。鉴于TFA具有IOU感知能力,但语义区分能力较弱,我们的主要见解是通过注入额外的类别区分信息来增强原始分类结果。在这项工作中,提出了一种新的少样本分类细化机制,以同时处理目标性估计和类别可辨别性。我们的框架由两个分支组成,分别称为“IOU感知分类分支”和“可辨别性增强分支”,它们分别在评估目标性和缓解类别混淆方面发挥作用。顾名思义,IOU感知分类分支负责为每个目标建议框生成准确的IOU估计,这是由原始TFA实现的。同时,增强分支被设计为平移不变分类器,以产生类别区分的分类结果。之后,这两个互补分支的输出被聚合在一起,以产生不那么混乱但能够识别IOU的confidence。
For exhaustively preserving the classification-preferred translation-invariant features, we design the enhancement branch as a decoupled classifier that does not share any parameters with the base detector, where we call it a Few-Shot Correction Network (FSCN). It segments region proposal from image space and provides extra classification refinement to the base detector. Therefore, the classification and localization tasks are decoupled in Faster-RCNN, which naturally solves the issue of shared feature representation. To further improve the semantic discriminability of FSCN, we train it by sampling misclassified false positives from TFA, so as to drive its focus towards the weakness of the base detector and enhance its capacity for eliminating category confusion.
为了彻底保留分类首选的平移不变特征,我们将增强分支设计为一个解耦分类器,它不与基本检测器共享任何参数,我们称之为少样本校正网络(FSCN)。它从图像空间中分割区域,并为基本检测器提供额外的分类细化。因此,分类和定位任务在Faster RCNN中解耦,这自然解决了共享特征表示的问题。为了进一步提高FSCN的语义可分辨性,我们通过从TFA中抽取误分类误报来训练它,从而使其关注基本检测器的弱点,并增强其消除类别混淆的能力。
Moreover, we focus on a unique but practically-existedproblem of FSOD in this work, i.e., the presence of distractor samples due to the incomplete annotations, where objects belonging to novel classes can exist in the base set but remain unlabelled. As shown in Fig. 2, such a situation is quite realistic for most real-world applications, e.g., in autonomous driving, FSOD is to extend the detection for a novel object “scooter”. However, “scooter” may also exist in the previous images for training the base classes with no annotations, so that such “scooter” distractors will be false emphasized as “background” continuously, which introduces destructive noise. Obviously, completely annotating all novel objects requires to repeatedly review the whole dataset upon the arrival of each novel classes, which is against the motivation of FSOD that dramatically increases the annotation cost especially when the detection tasks are evolving frequently. Hence, “distractor” is defined as those unlabelled novel-class objects in the base set, where proposals corresponding to those unlabelled novel objects are falsely supervised as negative examples. As a result, the positive gradients provided by the few-shot training samples could be easily overwhelmed by the discouraging gradients produced by the distractors during the detector finetuning, so that the resultant detector often inclines to predict novel classes with lower probabilities thus suffers catastrophic performance degradation. To the best of our knowledge, such the distractor phenomenon has not been treated in existing FSOD works without any attention to address it properly
此外,在这项工作中,我们关注一个独特但实际存在的FSOD问题,即由于标注不完整而存在干扰样本,属于新类的目标可以存在于基集中,但保持未标记。如图2所示,对于大多数实际应用来说,这种情况是非常现实的,例如,在自动驾驶中,FSOD将扩展对新目标“小型摩托车”的检测。然而,在之前的图像中也可能存在“小型摩托车”,用于训练没有注释的基类,因此这种“小型摩托车”干扰物将被持续错误地强调为“背景”,从而产生破坏性噪声。显然,完全注释所有新目标需要在每个新类到达时重复检查整个数据集,这与FSOD的动机背道而驰,FSOD会显著增加注释成本,尤其是在检测任务频繁变化的情况下。因此,“干扰物”被定义为基集中那些未标记的新类目标,其中与这些未标记的新类目标对应的正态被错误地监督为反例。因此,在检测器微调过程中,少样本训练样本提供的正梯度很容易被干扰源产生的令人沮丧的梯度所压倒,因此生成的检测器往往倾向于预测概率较低的新类,从而遭受灾难性性能降级。据我们所知,在现有的FSOD工作中,这种干扰现象没有得到适当的处理

Figure 2. Some samples to show the co-occurrence of both base and novel classes in the same image according to the commonly used dataset setting for MS-COCO, “couch”,“person” and “bottle” are novel classes while the others are base classes. Due to incomplete annotations, those novel-class objects can be unlabelled in base set
图2 根据MS-COCO的常用数据集设置,“沙发”、“人”和“机器人”是新类,而其他是基类。一些示例显示了基类和新类在同一图像中同时出现。由于注释不完整,这些新类目标可以在基集中未标记
In this work, we purposely tackle such distractor phenomenon by designing delicate retreatment approaches for both base detector and FSCN correspondingly. For the few-shot adaptation of base detector, a Confidence-Guided Dataset Pruning (CGDP) technique is proposed in this work, which utilizes the self-supervision to exclude the potential distractors to the greatest extent and form a cleaner and balanced training set for few-shot adaptation. Moreover, to sample enough hard examples, the training of FSCN has to be performed on the whole dataset, which exists distractors similarly. However, instead of eliminating the distractors, we specially propose a distractor utilization loss to make proper use of those potential unlabelled novel-class objects in the base set through a semi-supervised manner. In view of the data scarcity of the novel classes, such extra samples help to improve the final detection performance with zero additional annotation cost [15, 14]. Here, we summarize our main contributions as follow:
在这项工作中,我们通过为基本探测器和FSCN设计精细的再处理方法,有目的地解决这种干扰现象。对于基本检测器的少样本自适应,本文提出了一种置信度引导的数据集修剪(CGDP)技术,该技术利用自我监督最大限度地排除潜在的干扰因素,形成一个更干净、平衡的少样本自适应训练集。此外,为了获得足够多的硬样本,FSCN的训练必须在整个数据集上进行,而整个数据集同样存在干扰因素。然而,我们并没有消除干扰因素,而是特别提出了一种干扰因素利用损失,以通过半监督的方式正确利用这些潜在的未标记新类目标。鉴于新类的数据稀缺性,这种额外的样本有助于提高最终的检测性能,而不需要额外的注释成本[15,14]。在此,我们将主要贡献总结如下:
• We explore the limitations of the classifier rebalancing method (TFA) for FSOD problems and propose a novel few-shot classification refinement framework for exhaustively boosting its FSOD performance. A novel few-shot correction network is developed to achieve great semantic discriminability so as to eliminate false positives caused by category confusion.
• We are the first to address the destructive distractor issue for FSOD. Instead of blindly treating it, a confidence-guided filtering strategy is proposed to exclude the distractors for base detector fine-tuning.
• A semi-supervised distractor utilization strategy is proposed to cooperate with FSCN, which not only stabilizes the training process but also significantly promotes the learning on data-scarce novel classes with no extra annotation cost.
• Our proposed FSOD framework achieves the state-of-the-art results in various datasets with remarkable few-shot performance and knowledge retention abilit
•我们探讨了针对FSOD问题的分类器再平衡方法(TFA)的局限性,并提出了一种新的少样本分类细化框架,以彻底提高其FSOD性能。为了消除由于类别混淆而导致的误报,开发了一种新的少样本校正网络,以实现良好的语义区分性。
•我们是第一个解决FSOD破坏性干扰问题的公司。提出了一种置信度引导的滤波策略,用于排除干扰,从而实现基检测器的微调。
•提出了一种与FSCN合作的半监督干扰物利用策略,该策略不仅稳定了训练过程,而且显著促进了在数据稀缺的新类别上的学习,而无需额外的注释成本。
•我们提出的FSOD框架在各种数据集中实现了最先进的结果,具有显著的少样本性能和知识保留能力
2 相关工作
2.1. Decoupled Classification Refinement for Object Detection
用于目标检测的解耦分类细化
Regarding the misaligned learning goals between the proposal classification and bounding box regression tasks, many effective techniques are proposed to address this issue by introducing various detection refinement strategies. Decoupled Classification Refinement (DCR) [4] proposes to improve detection performance through a decoupled classification correction network, which is the most related work to our research.However, our application is significantly different from DCR. We specially targets the problem of FSOD, which has the additional challenge of localizing novel objects from just a few training samples, unlike the DCR limited to the data-abundant applications. Moreover, we propose the systematic approach to exploit the unique distractor phenomenon of FSOD in a semi-supervised manner for the refinement mechanism. To the best of our knowledge, we are the first to adapt the hard example mining strategy to address the FSOD problem.
针对建议框分类和回归任务之间的学习目标不一致问题,提出了许多有效的技术,通过引入各种检测细化策略来解决这个问题。解耦分类细化(DCR)[4]提出通过解耦分类校正网络来提高检测性能,这是我们研究中最相关的工作。然而,我们的应用程序与DCR有很大不同。我们专门针对FSOD的问题,它有一个额外的挑战,即仅从几个训练样本中定位新目标,而DCR仅限于数据丰富的应用。此外,我们还提出了一种系统的方法,以半监督的方式利用FSOD独特的干扰现象来实现细化机制。据我们所知,我们是第一个采用硬样本挖掘策略来解决FSOD问题的公司。
2.2. Few-Shot Object Detection (FSOD)
Most of the recent few-shot detection approaches areadapted from the few-shot recognition paradigms. A distillation-based approach is proposed in [3] with less-forgotten constraint and background depression regulaization. [7] emphasizes the class-specific information by reweighting top-layer feature maps with channel-wise attentions, so that the obtained features can be used to detect novel object effectively. YOLO-LS [7] and Meta-RCNN [19] propose to emphasize the class-specific feature informative via a meta-learning based channel-attention generator. Metric learning approaches are adopted for the detection classification [8], and [17] proposes a cosine-similarity based Faster-RCNN (TFA) with a category-balance fine-tuning set and achieves the state-of-the-art performance on public datasets. Context-transformer [20] proposes to leverage the rich source-domain knowledge and exploit useful context cues from the target-domain to tackle the challenging object confusion. ONCE [11] proposes a new research area of incremental few-shot object detection, where novel classes are added incrementally without using the samples from base classes. MPSR [18] focus on issue of scale variations caused by annotation scarcity, which generates multi-scale object pyramids to refine the prediction at various scales.
最近的大多数少样本检测方法都与少样本识别范例相适应。文献[3]提出了一种基于蒸馏的方法,具有较少的遗忘约束和背景抑制调节。[7] 通过对顶层特征图进行加权,并结合通道注意,强调类别特定的信息,从而使获得的特征能够有效地用于检测新对象。YOLO-LS[7]和Meta-RCNN[19]建议通过基于元学习的通道注意生成器来强调特定于类别的信息特征。检测分类采用了度量学习方法[8],并且[17]提出了一种基于余弦相似性的Faster RCNN(TFA),具有类别平衡微调集,并在公共数据集上实现了最先进的性能。Context transformer[20]提出利用丰富的源域知识,利用目标域中有用的上下文线索来解决具有挑战性的目标混淆问题。ONCE[11]提出了一个新的增量少样本目标检测研究领域,即在不使用基类样本的情况下增量添加新类。MPSR[18]关注注释稀缺导致的尺度变化问题,该问题生成多尺度目标金字塔,以细化不同尺度下的预测。
3 方法
3.1. Problem Definition
Our FSOD setting follows the classical formulation [7, 17]. Given a base set ![]() with sufficient annotated samples for each class, where
with sufficient annotated samples for each class, where![]() denotes an input image and
denotes an input image and ![]() denotes a list of Ni bounding-box annotations containing box location lj and category
denotes a list of Ni bounding-box annotations containing box location lj and category ![]() . Cbs is the space of base categories, Nbs = |Cbs| is the category number in Dbs. During the initial pre-training phase, an object detector F(·|θb) is trained on Dbs for detecting objects in Cbs with parameters θb. The FSOD task is performed on a k-shot novel set
. Cbs is the space of base categories, Nbs = |Cbs| is the category number in Dbs. During the initial pre-training phase, an object detector F(·|θb) is trained on Dbs for detecting objects in Cbs with parameters θb. The FSOD task is performed on a k-shot novel set ![]() with novel categories Cnv, where Cbs ∩ Cnv = ∅ and |Cnv| = Nnv. The objective of FSOD is to adapt the pre-trained detector parameters from θb to θ∗ through both sets Dbs∪Dnv, so that F(·|θ∗) can effectively detect the objects from all classes in Cbs ∪ Cnv.
with novel categories Cnv, where Cbs ∩ Cnv = ∅ and |Cnv| = Nnv. The objective of FSOD is to adapt the pre-trained detector parameters from θb to θ∗ through both sets Dbs∪Dnv, so that F(·|θ∗) can effectively detect the objects from all classes in Cbs ∪ Cnv.
我们的FSOD设置遵循经典公式[7,17]。给定一个基集![]() ,每个类有足够的带注释的样本,其中
,每个类有足够的带注释的样本,其中![]() 表示输入图像,
表示输入图像,![]() 表示包含框位置lj和类别
表示包含框位置lj和类别![]() 的Ni边界框注释列表。Cbs是基本类别的空间,Nbs=| Cbs |是Dbs中的类别编号。在初始预训练阶段,目标检测器F(·|θb)在Dbs上训练,用于检测Cbs中具有参数θb的目标。FSOD任务在具有新类别Cnv的k-shot新集合
的Ni边界框注释列表。Cbs是基本类别的空间,Nbs=| Cbs |是Dbs中的类别编号。在初始预训练阶段,目标检测器F(·|θb)在Dbs上训练,用于检测Cbs中具有参数θb的目标。FSOD任务在具有新类别Cnv的k-shot新集合![]() 上执行,其中Cbs∩ Cnv=∅ 和| Cnv |=Nnv。FSOD的目标是将预先训练好的检测器参数从θb调整到θ∗ 通过Dbs∪Dnv。所以F(·|θ∗) 能够有效地检测Cbs∪ Cnv中所有类的目标。
上执行,其中Cbs∩ Cnv=∅ 和| Cnv |=Nnv。FSOD的目标是将预先训练好的检测器参数从θb调整到θ∗ 通过Dbs∪Dnv。所以F(·|θ∗) 能够有效地检测Cbs∪ Cnv中所有类的目标。
The definition of the distractor phenomenon in FSOD is that some images ![]() in Dbs may possibly contain unlabel objects belonging to Cnv. According to previous works, those objects are unlabeled in Dbs and will be treated as the background during detector fine-tuning, which introduces dramatic confusion for detector training. However, in realworld scenarios, revisiting the massive Dbs to label out all objects belonging to Cnv is not affordable, and more importantly, conflicts the main purpose of few-shot learning. Therefore, handling the distractor through the delicate algorithm is of great significance to avoid the huge annotation cost and improve the FSOD performance.
in Dbs may possibly contain unlabel objects belonging to Cnv. According to previous works, those objects are unlabeled in Dbs and will be treated as the background during detector fine-tuning, which introduces dramatic confusion for detector training. However, in realworld scenarios, revisiting the massive Dbs to label out all objects belonging to Cnv is not affordable, and more importantly, conflicts the main purpose of few-shot learning. Therefore, handling the distractor through the delicate algorithm is of great significance to avoid the huge annotation cost and improve the FSOD performance.
FSOD中分心现象的定义是,Dbs中的某些图像![]() 可能包含属于Cnv的未标记目标。根据之前的工作,这些物体在Dbs中未标记,并将在检测器微调期间被视为背景,这给检测器训练带来了巨大的混乱。然而,在现实世界的场景中,重新访问大规模Dbs以标记出属于Cnv的所有目标是不可承受的,更重要的是,这与少样本性能具有重要意义。
可能包含属于Cnv的未标记目标。根据之前的工作,这些物体在Dbs中未标记,并将在检测器微调期间被视为背景,这给检测器训练带来了巨大的混乱。然而,在现实世界的场景中,重新访问大规模Dbs以标记出属于Cnv的所有目标是不可承受的,更重要的是,这与少样本性能具有重要意义。
3.2. Framework Overview with Few-Shot Classification Refinement
In view of the scarce training samples available forFSOD problem, the learning difficulty is significantly enlarged due to the intrinsic architecture limitation of detector, which often results in less discriminative classifier and leads to category confusion. Essentially, for object detectors, such issue actually comes down to the overwhelming number of misclassified false positives. Motivated by this, we aim to tackle the challenging FSOD problem from the view of hard example mining. Specifically, our framework exploits to alleviate the burden of differentiating false positives by leveraging a powerful few-shot classification refinement mechanism. A decoupled correction network is employed to further refine and enhance the proposal classification, which is trained from the hard false positives sampled from the box regressor of the base detector. Such error-oriented perspective plus the additional architecture-level enhancement also provide a unified way to jointly address the few-shot adaption and category confusion.
由于FSOD问题的训练样本较少,由于检测器固有的结构限制,学习难度显著增大,这往往导致分类器的区分性较差,并导致类别混淆。从本质上讲,对于物体捡测器来说,这样的问题实际上归结为大量错误分类的误报。基于此,我们的目标是从硬样本挖掘的角度解决具有挑战性的FSOD问题。具体来说,我们的框架利用一个强大的少样本分类细化机制来减轻区分误报的负担。采用解耦校正网络进一步细化和增强建议分类,建议分类由从基本检测器的框回归器中采样的硬误报进行训练。这种以错误为导向的视角,再加上额外的架构级增强,也提供了一种统一的方式来共同解决少样本的自适应和类别混淆问题。
The overall architecture of the proposed FSOD framework is shown as in Fig. 3, which consists of two parallel networks, i.e., the base detector Fd(·) and the FSCN Fr(·). In this work, Fd(·) takes Faster-RCNN as a example, the input image is processed by Fd(·) first to obtain the primary proposal information. The proposed FSCN Fr(·) takes the proposals of box regressor as inputs, which are cropped from original image according to the proposal location, denoted as Ip = Cr(I, p), where Cr(·) denotes the crop function, and I and p denotes input image and proposal boxes predicted by Fd(·), respectively. Similar as the Faster-RCNN proposal classifier in Fd(·), FSCN Fr(·) outputs a classification distribution vector sr with Nt + 1 elements, where Nt = Nbs + Nnv is the number of all base+novel classes and the additional +1 is the background class. Therefore, the proposed FSCN Fr(·) can be represented as
建议的FSOD框架的总体架构如图3所示,由两个并行网络组成,即基本检测器Fd(·)和FSCN Fr(·)。在本文中,Fd(·)以Faster RCNN为例,首先对输入图像进行Fd(·)处理,以获得主要的提案信息。建议的FSCN Fr(·)将框回归器的建议作为输入,根据建议位置从原始图像中裁剪,表示为Ip=Cr(I,p),其中Cr(·)表示裁剪函数,I和p分别表示Fd(·)预测的输入图像和建议框。与Fd(·)中Faster RCNN建议分类器类似,FSCN Fr(·)输出具有Nt+1个元素的分类分布向量sr,其中Nt=Nbs+Nnv是所有基本+新类的数量,额外的+1是背景类。因此,提出的的FSCN Fr(·)可以表示为
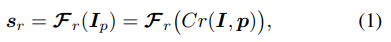
where![]() is the classification confidence vector for all Nt + 1 categories. The key idea is to augment the base detector Fd(·) with FSCN Fr(·) in parallel to enhance the proposal classification capability. Since Fr(·) is trained with false positives sampled from Fd(·), the proposed FSOD architecture,
is the classification confidence vector for all Nt + 1 categories. The key idea is to augment the base detector Fd(·) with FSCN Fr(·) in parallel to enhance the proposal classification capability. Since Fr(·) is trained with false positives sampled from Fd(·), the proposed FSOD architecture,
其中,![]() 是所有Nt+1类别的分类置信向量。其关键思想是用FSCN Fr(·)并行增强基本检测器Fd(·),以增强提案分类能力。由于Fr(·)是通过从Fd(·)中采样的假阳性进行训练的,因此提出的FSOD架构,
是所有Nt+1类别的分类置信向量。其关键思想是用FSCN Fr(·)并行增强基本检测器Fd(·),以增强提案分类能力。由于Fr(·)是通过从Fd(·)中采样的假阳性进行训练的,因此提出的FSOD架构,
![]()
is endowed with stronger discriminative capability to eliminate the false positives, which is crucial for FSOD performance.
被赋予更强的鉴别能力,以消除误报,这对FSOD性能至关重要。
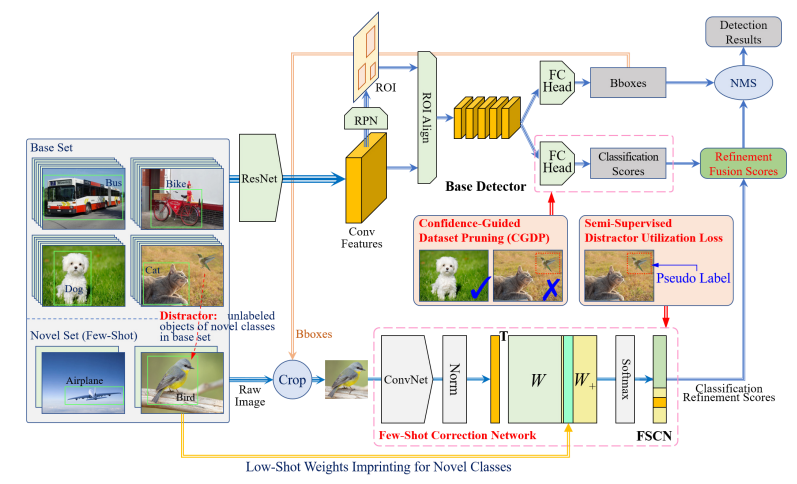
Figure 3. Illustration of the proposed FSOD framework, where the FSCN provides extra classification refinement to eliminate the false positives. When adapting to new few-shot tasks, separate strategies are proposed for the base detector and FSCN. For the fine-tuning of the base detector, CGDP is proposed to filter out those base-set images that may contain unlabeled novel-class objects, e.g., the “bird” here. In contrast, FSCN requires to train on the whole dataset for sampling enough false positives, thus a semi-supervised distractor utilization lossis proposed to encourage the FSCN to learn from those confident unlabeled distractor proposals to boost the data-scarce classes, instead of falsely treating them as negatives.
图3 建议的FSOD框架的说明,其中FSCN提供额外的分类细化,以消除误报。在适应新的少样本任务时,基本检测器和FSCN分别提出了不同的策略。为了对基本检测器进行微调,CGDP建议过滤掉那些可能包含未标记新类对象的基本集图像,例如这里的“鸟”。相比之下,FSCN需要在整个数据集上进行训练,以获得足够的误报率,因此提出了一种半监督干扰物利用损失法,以鼓励FSCN从那些自信的未标记干扰物建议中学习,从而提高数据稀缺类,而不是错误地将其视为负面。
3.3. Few-Shot Correction Network (FSCN)
3.3.1 Network Description
The proposed FSCN Fr(·) consists of two components: a feature extractor φϑ and a linear classifier ϕw. The feature extractor
建议的FSCN Fr(·)由两部分组成:特征提取程序φϑ和线性分类器φw。特征提取器
![]()
maps a 2D input image Ip to a feature embedding zp ∈ Rd , where ϑ denotes its network parameters. The linear classifier
将2D输入图像Ip映射到特征嵌入zp∈ Rd,其中ϑ表示其网络参数。线性分类器a
![]()
calculates the similarities to all classes followed by softmax, where![]() . In addition, unlike image classification task where a single large object is in the center of an image, objects in detection tasks may appear from a wide range of scales or appear at an arbitrary position. However, the effective receptive field of traditional CNNs is usually small and spatially biased to the central region. As a result, objects located at the outer area of the receptive field are more likely to be ignored. Hence, a good correction network is required to have a sufficiently large receptive field that can handle such complex appearance of region proposals. In this work, a Compact Generalized Non-Local (CGNL) module [21] is equipped with FSCN to achieve global receptive field.
. In addition, unlike image classification task where a single large object is in the center of an image, objects in detection tasks may appear from a wide range of scales or appear at an arbitrary position. However, the effective receptive field of traditional CNNs is usually small and spatially biased to the central region. As a result, objects located at the outer area of the receptive field are more likely to be ignored. Hence, a good correction network is required to have a sufficiently large receptive field that can handle such complex appearance of region proposals. In this work, a Compact Generalized Non-Local (CGNL) module [21] is equipped with FSCN to achieve global receptive field.
计算所有类的相似性,然后是softmax,其中![]() 。此外,与单个大目标位于图像中心的图像分类任务不同,检测任务中的目标可能出现在很大范围内,或者出现在任意位置。然而,传统CNN的有效感受野通常很小,并且在空间上偏向中心区域。因此,位于感受野外部区域的物体更容易被忽略。因此,一个好的校正网络需要有一个足够大的接收野,能够处理如此复杂的区域外观。在这项工作中,一个紧凑的通用非局部(CGNL)模块[21]配备了FSCN,以实现全局感受野。
。此外,与单个大目标位于图像中心的图像分类任务不同,检测任务中的目标可能出现在很大范围内,或者出现在任意位置。然而,传统CNN的有效感受野通常很小,并且在空间上偏向中心区域。因此,位于感受野外部区域的物体更容易被忽略。因此,一个好的校正网络需要有一个足够大的接收野,能够处理如此复杂的区域外观。在这项工作中,一个紧凑的通用非局部(CGNL)模块[21]配备了FSCN,以实现全局感受野。
The key point of few-shot learning is to use a good similarity metric that can be easily generalized to unseen classes. In this work, we introduce cosine similarity metric into FSCN, which can well encourage the unified recognition over all classes. Specifically, we use a zero-bias fully-connection layer in ϕw followed by softmax. Given a proposal image input![]() , the classification confidence
, the classification confidence ![]() for category j can be calculated as
for category j can be calculated as
少样本学习的关键是使用一个好的相似性度量,它可以很容易地推广到看不见的类。在这项工作中,我们将余弦相似性度量引入到FSCN中,这可以很好地鼓励对所有类别的统一识别。具体地说,我们使用了一个零偏置全连接层,单位为ɕw,后面是softmax。给出了一个提案图像输入![]() ,类别j的分类置信度
,类别j的分类置信度![]() 可计算为
可计算为

where · denotes Frobenius inner product and![]() denotes the L2-normalization, κ is a learnable scale parameter used to ensure the convergence of training [16].
denotes the L2-normalization, κ is a learnable scale parameter used to ensure the convergence of training [16].
其中·表示Frobenius内积,![]() 表示L2归一化,κ是一个可学习的尺度参数,k用于确保训练收敛[16]。
表示L2归一化,κ是一个可学习的尺度参数,k用于确保训练收敛[16]。
3.3.2 Weight Imprinting for Novel Classes
To adapt the FSCN Fr(·) from base classes to novel classes, we introduce a weight imprinting technique [12] for FSOD to directly initialize its parameters for sequential learning. Consider the Fr(·) trained from base categories Cbs to be adapted to novel categories Cnv, the weights w in ϕw is augmented from ![]() to
to![]() . Hence, for those new-coming classes, an intuitive way to set their weights is to average the corresponding normalized feature vectors zp,
. Hence, for those new-coming classes, an intuitive way to set their weights is to average the corresponding normalized feature vectors zp,
为了将FSCN Fr(·)从基类调整为新类,我们引入了一种权重印记技术[12],用于FSOD直接初始化其参数以进行顺序学习。 考虑到从基本类别Cbs训练出来的Fr(·)要适应新类别Cnv,ϕw的权重w从![]() 增加到
增加到![]() 。因此,对于那些即将出现的新类,设置权重的直观方法是平均相应的归一化特征向量zp,
。因此,对于那些即将出现的新类,设置权重的直观方法是平均相应的归一化特征向量zp,
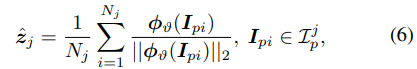
where ![]() ,
,![]() denotes the j-th class set of foreground region-proposal images extracted from Dnv, and
denotes the j-th class set of foreground region-proposal images extracted from Dnv, and ![]() . The final weights wj is calculated by normalizing the averaged features, where
. The final weights wj is calculated by normalizing the averaged features, where ![]() . Note that there is one special background class for the detection classification, which is shared among both the base and novel sets. Similarly, its weights are inferred by sampling background region proposals uniformly from Dbs ∪ Dnv similar as for those novel classes.
. Note that there is one special background class for the detection classification, which is shared among both the base and novel sets. Similarly, its weights are inferred by sampling background region proposals uniformly from Dbs ∪ Dnv similar as for those novel classes.
其中![]() ,
,![]() 表示从Dnv提取的前景区域建议图像的第j类集合,
表示从Dnv提取的前景区域建议图像的第j类集合,![]() 。通过归一化平均特征计算最终权重wj,其中
。通过归一化平均特征计算最终权重wj,其中![]() 。请注意,检测分类有一个特殊的背景类,它在基本集和新集之间共享。类似地,通过从Dbs∪ Dnv中均匀地采样背景区域来推断其权重与那些新类别类似。
。请注意,检测分类有一个特殊的背景类,它在基本集和新集之间共享。类似地,通过从Dbs∪ Dnv中均匀地采样背景区域来推断其权重与那些新类别类似。
3.4. Semi-Supervised Distractor Utilization Loss半监督干扰使用损失
Under the low-data constraint on novel classes, to tackle the above mentioned issue of category confusion, the abundant number of false positives sampled from base set become particularly valuable, especially for those producing high response to novel classes due to the shared visually-similar appearances. However, without complete annotations, those unlabeled objects presented in base set (distractors) are often falsely emphasized as negatives, which is destructive to FSCN. With the commonly-used cross-entropy loss, the encouraging gradients provided from the few-shot training samples are easily suppressed by the discouraging gradients produced from those unlabeled distractors. Inspired by this, we delve into the most fundamental but important issue for training FSCN, i.e., how to avoid blindly learning from distractors and even make proper use of them. To address this, we proposed a semi-supervised distractor utilization loss, which employs the confident unlabeled data to promote the learning of few-shot classes through a semisupervised manner, thus improves the final detection performance.
在新类数据量较少的情况下,为了解决上述类别混淆问题,从基集中采样的大量误报变得特别有价值,特别是对于那些对新类别产生高反应的目标,因为他们有着相似的视觉效果。然而,在没有完整注释的情况下,那些在基本集合中呈现的未标记目标(干扰物)经常被错误地强调为否定,这对FSCN是有害的。通过使用常用的交叉熵损失,少样本训练样本提供的鼓励梯度很容易被那些未标记的干扰源产生的令人沮丧的梯度所抑制。受此启发,我们深入探讨了训练FSCN最基本但最重要的问题,即如何避免盲目学习干扰因素,甚至正确使用它们。为了解决这一问题,我们提出了一种半监督的分心器利用率损失方法,该方法利用可靠的未标记数据,通过半监督的方式促进少样本类别的学习,从而提高最终的检测性能。
We notice that for each background proposal sampled from the base set, there is a probability for it to be an unlabeled foreground of novel class. The idea of the proposed semi-supervised distractor utilization loss is to assign positive gradients to those potential foreground novel classes as well as the original background class, so that the network training is more motivated for those under-represented novel classes. Consequently, the key issue is to determine the possible foreground class for each background proposal sampled from Dbs, we formulate it as a semi-supervised learning problem and tackle it with the pseudo hard labeling technique. Specifically, given a background proposal Ibp from Dbs, its pseudo label can be determined according to the prediction confidence of the current FSCN,
我们注意到,对于从基集中采样的每个背景方案,都有可能是新类的未标记前景。提出的半监督干扰物利用损失的思想是将正梯度分配给潜在的前景类和原始背景类,以便对代表性不足的类进行网络训练。因此,关键问题是确定从Dbs中采样的每个背景方案的可能前景类,我们将其描述为一个半监督学习问题,并使用伪硬标记技术进行处理。具体来说,给定Dbs的背景提案Ibp,其伪标签可以根据当前FSCN的预测置信度确定,
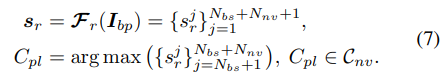
However, if all the background proposals are labeled as positive samples of novel classes, there will be no negative samples for FSCN training, which leads the FSCN to produce a highly biased prediction. Therefore, such predicted pseudo label can not be directly employed to train the network. To address this issue, we further introduce a new concept of background augmentation, which defines a Augmented Background class by merging the original background class Cb with the generated pseudo class Cp, denoted as set ![]()
然而,如果所有背景提案都被标记为新类别的正样本,那么FSCN训练将不会有负样本,这导致FSCN产生了一个高度偏颇的预测。因此,这种预测的伪标签不能直接用于网络训练。为了解决这个问题,我们进一步引入了背景增强的新概念,它通过将原始背景类Cb与生成的伪类Cp(表示为![]() )合并来定义增强的背景类
)合并来定义增强的背景类
![]()
For example, assuming there are 60 base class in Cbs, 20 novel class in Cnv and one background class Cb. For a background proposal that produces high activation to one novel classes “human” (pseudo labeled class Cpl), we merge the class “human” Cpl and the background class Cb into a new augmented background class![]() . Thus the new label space
. Thus the new label space ![]() have 60 base class Cbs, 19 novel class (Cnv\Cpl) with one augmented background class
have 60 base class Cbs, 19 novel class (Cnv\Cpl) with one augmented background class ![]() . As a result, the overall prediction score for the Augmented Background class
. As a result, the overall prediction score for the Augmented Background class![]() is to aggregate the softmax confidence from both Cb and Cpl,according to Eq. 8,
is to aggregate the softmax confidence from both Cb and Cpl,according to Eq. 8,
例如,假设Cbs中有60个基类,Cnv中有20个新类和一个背景类Cb。对于对一个新类“人类”(伪标记类Cpl)产生高激活的背景方案,我们将类“人类”Cpl和背景类Cb合并成一个新的增强背景类![]() 。因此,新的标签空间
。因此,新的标签空间![]() 有60个基类Cbs,19个新类(Cnv\Cpl)和一个增强背景类
有60个基类Cbs,19个新类(Cnv\Cpl)和一个增强背景类![]() 。因此,增强背景类别
。因此,增强背景类别![]() 的总体预测分数是从Cb和Cpl中聚合softmax置信度。根据公式8,
的总体预测分数是从Cb和Cpl中聚合softmax置信度。根据公式8,
![]()
Based on this modification, an improved cross-entropy loss, which we termed as distractor utilization loss, is proposed to not only alleviate the negative influence of distractors but also exploit the distractors to boost the training for those data-scarce novel classes,
在此基础上,提出了一种改进的交叉熵损失,我们称之为干扰物利用损失,它不仅可以减轻干扰物的负面影响,还可以利用干扰物来促进数据稀缺的新类的训练,
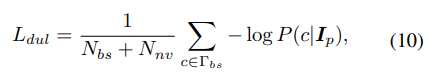
where Γbs is the reformulated category space on Dbs, defined as ![]() and
and ![]() is treated as one Augmented Background class in Γbs. The proposed distractor utilization loss Ldul assigns encouraging gradients to the potential corresponding novel classes to boost the few-shot performance when facing distractors. In the meanwhile, the original gradients to background class persist as well in regardless of distractor or not. Note that the distractor utilization loss is only needed to the proposals sampled from Dbs, since for Dnv, the standard cross-entropy loss is enough as full annotations are available under the common FSOD setting.
is treated as one Augmented Background class in Γbs. The proposed distractor utilization loss Ldul assigns encouraging gradients to the potential corresponding novel classes to boost the few-shot performance when facing distractors. In the meanwhile, the original gradients to background class persist as well in regardless of distractor or not. Note that the distractor utilization loss is only needed to the proposals sampled from Dbs, since for Dnv, the standard cross-entropy loss is enough as full annotations are available under the common FSOD setting.
其中,Γbs是Dbs上重新定义的类别空间,定义为![]() ,
,![]() 在Γbs中被视为一个增强的背景类。建议的干扰物利用率损失Ldul为潜在的相应新类别分配令人鼓舞的梯度,以提高面对干扰物时的少样本性能。同时,不管是否有干扰因素,背景类的原始梯度也会保持不变。请注意,分散剂利用率损失仅适用于从Dbs取样的提案,因为对于Dnv,标准交叉熵损失就足够了,因为在通用FSOD设置下,完整注释可用。
在Γbs中被视为一个增强的背景类。建议的干扰物利用率损失Ldul为潜在的相应新类别分配令人鼓舞的梯度,以提高面对干扰物时的少样本性能。同时,不管是否有干扰因素,背景类的原始梯度也会保持不变。请注意,分散剂利用率损失仅适用于从Dbs取样的提案,因为对于Dnv,标准交叉熵损失就足够了,因为在通用FSOD设置下,完整注释可用。
However, only a small portion of backgrounds sampled from base set are to be truly unlabeled objects of novel classes, while the major portion are just hard negatives of base classes. In practice, when applying the above Ldul loss, if the merging strategy is applied to all backgrounds sampled from base set, each will contribute an encouraging gradient to novel class, and the accumulated gradient is too strong and lead to a biased prediction towards novel classes. To avoid this, we propose an unlabelled object mining (UOM) strategy to automatically select the high-possibility unlabelled objects. Without considering the object occlusion, for a background proposal to be considered as unlabeled objects, it should at least intersect not too much with any known objects. Inspired by this, a spatial metric Msp is developed for performing effective training sample selection, which measures the maximal spatial intersection between the candidate proposal and all known ground-truth objects. Specifically, for a background proposal pb with location lb sampled from a base set image, we calculate the spatial metric Msp as,
然而,从基集中采样的背景中,只有一小部分是新类的真正未标记目标,而大部分只是基类的硬负片。在实际应用中,当应用上述Ldul损失时,如果将合并策略应用于从基集中采样的所有背景,每个背景都会为新类贡献一个令人鼓舞的梯度,并且累积的梯度太强,导致对新类的预测有偏。为了避免这种情况,我们提出了一种未标记目标挖掘(UOM)策略来自动选择高可能性的未标记目标。在不考虑目标遮挡的情况下,对于要被视为未标记目标的背景方案,它至少应该与任何已知目标不太相交。受此启发,我们开发了一种空间度量Msp,用于执行有效的训练样本选择,它测量候选方案和所有已知ground-truth目标之间的最大空间交集。具体来说,对于从基集图像中采样的位置为lb的背景方案pb,我们计算空间度量Msp为,
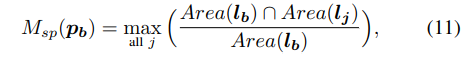
where Area(·) denotes the box area specified by l, and lj is the annotated box location of j-th base object in the urrent image. Different from the conventional IOU metric, the proposed intersection ratio represents a normalized measure that focuses on the area of empty volume contained in each region proposal. Thus, Ldul loss is only applied on those high-possibility background proposals to be novel classes, which exploits the distractor for few-shot classes learning effectively but avoid the unwanted prediction bias.
其中Area(·)表示由l指定的方框区域,lj是当前图像中第j个基本对象的注释方框位置。与传统的IOU度量不同,提议的交叉口比率代表了一种标准化度量,它关注每个区域提议中包含的空置体积面积。因此,Ldul损失仅适用于那些高可能性的背景提议,即新类,这有效地利用了干扰因素进行少样本类学习,但避免了不必要的预测偏差。
3.5. Confidence-Guided Dataset Pruning (CGDP) 置信度指导的数据集修剪
While the effective training of FSCN has been addressed in Section 3.4, we focus on the few-shot adaptation of base detector Fd(·) in this subsection. The motivation for CGDP is to form a small clean subset with less distractors from Dbs to facilitate the base detector few-shot adaptation. Our approach is mainly motivated by the recent pool-based active learning technique[1]. However, unlike the traditional active learning that usually focuses on picking out the most informative unlabeled samples for human annotation, we aim at developing an automatic pipeline by taking the advantage of self-supervision to effectively clean the distractor samples. Basically, our proposed CGDP is a two-stage process which consists of the indicator learning stage and the dataset pruning stage. Here, the indicator is to indicate the possibility to have distractors for a image from Dbs.
虽然FSCN的有效训练已在第3.4节中讨论过,但我们在本小节中重点介绍了基本探测器Fd(·)的少样本自适应。CGDP的动机是形成一个小而干净的子集,减少来自Dbs的干扰,以促进基本检测器的少样本。适应。我们的方法主要受最近基于池的主动学习技术[1]的推动。然而,与传统的主动学习不同,主动学习通常侧重于挑选信息量最大的未标记样本进行人工标注,我们的目标是通过利用自我监督来开发一个自动管道,以有效地清除干扰样本。基本上,我们提出的CGDP是一个两阶段的过程,包括指标学习阶段和数据集修剪阶段。在这里,该指示器用于指示Dbs图像可能存在干扰物。
For the first stage, we look for a simple yet effective way to develop an efficient query function. Specifically, given a base detector Fb(·) that is pre-trained from Dbs, an indicator ![]() is the classification branch obtained by fine-tuning Fb(·) on Dind using normal cosine-similarity classification loss without considering the issues of distractors. Here, Dind is a balanced training set made of the whole Dnv and a small portion of Dbs, and only the remaining portion of Dbs will be used for dataset pruning in next stage, denoted as Dpru, i.e., Dind ∪ Dpru = Dbs ∪ Dnv. Given an input image Ibs, the classification confidences of all region proposals are predicted by
is the classification branch obtained by fine-tuning Fb(·) on Dind using normal cosine-similarity classification loss without considering the issues of distractors. Here, Dind is a balanced training set made of the whole Dnv and a small portion of Dbs, and only the remaining portion of Dbs will be used for dataset pruning in next stage, denoted as Dpru, i.e., Dind ∪ Dpru = Dbs ∪ Dnv. Given an input image Ibs, the classification confidences of all region proposals are predicted by ![]() as,
as,
在第一阶段,我们寻找一种简单而有效的方法来开发高效的查询函数。具体来说,给定从Dbs预先训练的基本检测器Fb(·),指示器![]() 是通过使用正余弦相似性分类损失在Dind上微调Fb(·)而获得的分类分支,而不考虑干扰因素的问题。在这里,Dind是一个由整个Dnv和一小部分Dbs组成的平衡训练集,在下一阶段,只有Dbs的剩余部分将用于数据集修剪,表示为Dpru,即Dind∪ Dpru=Dbs∪ Dnv。给定一幅输入图像Ibs,所有区域方案的分类可信度由
是通过使用正余弦相似性分类损失在Dind上微调Fb(·)而获得的分类分支,而不考虑干扰因素的问题。在这里,Dind是一个由整个Dnv和一小部分Dbs组成的平衡训练集,在下一阶段,只有Dbs的剩余部分将用于数据集修剪,表示为Dpru,即Dind∪ Dpru=Dbs∪ Dnv。给定一幅输入图像Ibs,所有区域方案的分类可信度由![]() 预测为:
预测为:![]()
where ![]() is the confidence score of j-th novel class for i-th proposal, and Np is total number of proposals. The proposed query function Q(·) that estimates the likelihood of an image to have distractors is defined as,
is the confidence score of j-th novel class for i-th proposal, and Np is total number of proposals. The proposed query function Q(·) that estimates the likelihood of an image to have distractors is defined as,
其中![]() 是第i个提案的第j个新类别的置信度得分,Np是建议框总数。建议的查询函数Q(·)用于估计图像中存在干扰物的可能性,其定义如下:
是第i个提案的第j个新类别的置信度得分,Np是建议框总数。建议的查询函数Q(·)用于估计图像中存在干扰物的可能性,其定义如下:
![]()
In the second pruning stage, Q(·) is used to select the samples from Dpru in order to form a clean subset Dcln. Specially, we construct a class-specific data pool for each category in Cbs by sampling images from Dpru. Suppose there are total Nci images in Dpru that contains the objects of class ci ∈ Cbs, the data pool for class ci is constructed as
在第二个修剪阶段,使用Q(·)从Dpru中选择样本,以形成一个干净的Dcln子集。特别是,我们通过从Dpru采集图像,为Cbs中的每个类别构建了一个特定于类的数据池。假设Dpru中包含ci∈ Cbs类目标的Nci图像总数,类ci的数据池构造为
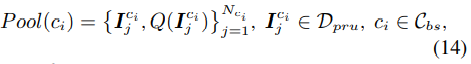
where ![]() is the j-th image that contains object from class ci and
is the j-th image that contains object from class ci and![]() is its corresponding likelihood of being with distractors. From each data pool, we select its top m samples which have the lowest likelihood in order to form the clean balanced training set Dcln. It is also noted that Dcln follows the original distributions of base classes in Dpru as well as Dbs. Overall, the proposed CGDP pipeline can be formulated as、
is its corresponding likelihood of being with distractors. From each data pool, we select its top m samples which have the lowest likelihood in order to form the clean balanced training set Dcln. It is also noted that Dcln follows the original distributions of base classes in Dpru as well as Dbs. Overall, the proposed CGDP pipeline can be formulated as、
其中,![]() 是第j张图像,其中包含来自类别ci的目标,
是第j张图像,其中包含来自类别ci的目标,![]() 是其与干扰物对应的可能性。从每个数据池中,我们选择其最大的m个样本,这些样本具有最低的可能性,以形成干净平衡的训练集Dcln。还需要注意的是,Dcln遵循Dpru和Dbs中基类的原始分布。总的来说,拟建CGDP管道的公式如下:
是其与干扰物对应的可能性。从每个数据池中,我们选择其最大的m个样本,这些样本具有最低的可能性,以形成干净平衡的训练集Dcln。还需要注意的是,Dcln遵循Dpru和Dbs中基类的原始分布。总的来说,拟建CGDP管道的公式如下:
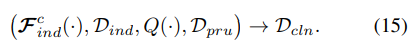
4 实验
4.1. Implementation Details
We implement the proposed FSCN by using an ImageNet pre-trained ResNet50-CGNL model [21]. Given a mini-batch which contains nbs base-set images and nnv novel-set images, for each image feed into![]() , we only reserve its top 300 candidate boxes and divide them into three groups which are the foreground, false positives. Given the classification confidence of a region proposal, if the network’s response to one of its negative class is larger than a pre-defined threshold 0.1, we consider this region proposal as a false positive detection. We then sample a total number of m boxes from these three groups uniformly [4]. In our experiments, we set nbs = 6, nnv = 2 and m = 32. Finally, a ROI-Align layer is used to crop the selected boxes from the original image and reshape them into the size of 224 × 244. The threshold for unlabelled object mining(UOM) is set to be 0.2. Due to space limitation, more training details are included in appendix.
, we only reserve its top 300 candidate boxes and divide them into three groups which are the foreground, false positives. Given the classification confidence of a region proposal, if the network’s response to one of its negative class is larger than a pre-defined threshold 0.1, we consider this region proposal as a false positive detection. We then sample a total number of m boxes from these three groups uniformly [4]. In our experiments, we set nbs = 6, nnv = 2 and m = 32. Finally, a ROI-Align layer is used to crop the selected boxes from the original image and reshape them into the size of 224 × 244. The threshold for unlabelled object mining(UOM) is set to be 0.2. Due to space limitation, more training details are included in appendix.
我们通过使用ImageNet预先训练的ResNet50 CGNL模型来实现拟议的FSCN[21]。给定一个小批量,其中包含nbs基本集图像和nnv新集图像,对于每个图像馈送到![]() ,我们只保留前300个候选框,并将它们分为三组,即前景、假阳性。考虑到区域建议的分类置信度,如果网络对其中一个阴性类别的响应大于预定义的阈值0.1,我们将该区域建议视为假阳性检测。然后,我们从这三个组中均匀地抽取m个边界框[4]。在我们的实验中,我们设定了nbs=6、nnv=2和m=32。最后,使用ROI对齐层从原始图像中裁剪选定的框,并将其重塑为224×244的大小。未标记目标挖掘(UOM)的阈值设置为0.2。由于篇幅限制,更多训练细节见附录。
,我们只保留前300个候选框,并将它们分为三组,即前景、假阳性。考虑到区域建议的分类置信度,如果网络对其中一个阴性类别的响应大于预定义的阈值0.1,我们将该区域建议视为假阳性检测。然后,我们从这三个组中均匀地抽取m个边界框[4]。在我们的实验中,我们设定了nbs=6、nnv=2和m=32。最后,使用ROI对齐层从原始图像中裁剪选定的框,并将其重塑为224×244的大小。未标记目标挖掘(UOM)的阈值设置为0.2。由于篇幅限制,更多训练细节见附录。
4.1.1 Results on MS-COCO
We provide the mAP performance of the novel classes on MS-COCO [10] in Table 1, and compare our approach with the other six baselines, which are YOLO low-shot [7], Meta-RCNN [19] , ONCE no-incremental [11], TFA [17], MPSR [18], and context transformer [20]. Our approach uses ResNet50 [6] as the backbone for the base detector, which is similar to Meta-RCNN. However, we notice that a stronger backbone FPN [9] is employed by TFA. For a fair comparison, we re-implement its proposed cosine similarity classification and balanced fine-tuning strategy with our backbone (ResNet50), which roughly matches the original results in TFA. Here, we denote this re-implemented baseline as “cos-FRCN”.
我们在表1中提供了MS-COCO[10]上新类的映射性能,并将我们的方法与其他六个基线进行了比较,它们是YOLO low shot[7]、Meta RCNN[19]、ONCE no incremental[11]、TFA[17]、MPSR[18]和context transformer[20]。我们的方法使用ResNet50[6]作为基本检测器的主干,这与Meta-RCNN类似。然而,我们注意到TFA采用了更强的主干FPN[9]。为了进行公平比较,我们用主干网(ResNet50)重新实现了其提出的余弦相似性分类和平衡微调策略,这与TFA中的原始结果大致匹配。在这里,我们将这条重新实现的基线表示为“cos FRCN”。
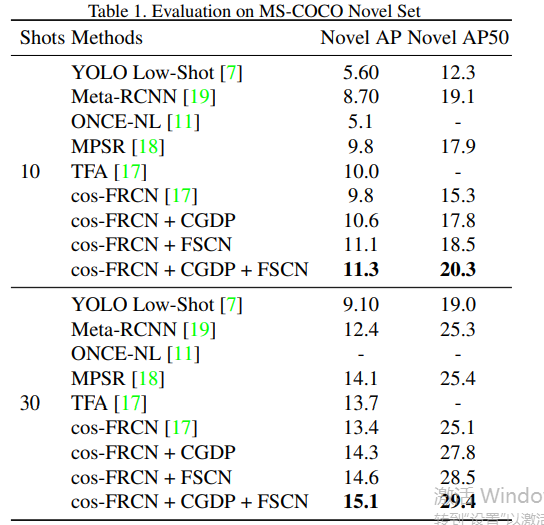
Regarding the results, we have several observations. 1),In all different numbers of training shots, our approach is able to outperform the previous methods by large margins, which achieve the state-of-the-art results. As we can see,it almost doubles the performance of the previous meta-learning approaches (YOLO low-shot) under the 10-shot case, which validates the effectiveness of our approach. 2), As the distractor is a unique and extremely-challenging problem for FSOD, the proposed CGDP can be seen as a simple yet effective solution which brings significant improvement of early 1 point on novel classes. 3), The absolute performance gain of FSCN is even larger than CGDP,which indicates that the intrinsic architecture limitations of Faster-RCNN is severer than the issue of distractors.
关于结果,我们有几个观察结果。1) ,在所有不同数量的训练样本中,我们的方法都能大大优于之前的方法,从而达到最先进的效果。正如我们所见,在10-shots的情况下,它的性能几乎是之前元学习方法(YOLO low shot)的两倍,这验证了我们方法的有效性。2) 对于FSOD来说,干扰因素是一个独特且极具挑战性的问题,因此,建议的CGDP可以被视为一个简单而有效的解决方案,可以显著提高新类别的早期1个点。3) ,FSCN的绝对性能增益甚至比CGDP更大,这表明Faster-RCNN的固有架构局限性比干扰物问题更严重。
4.1.2 Results on Pascal VOC
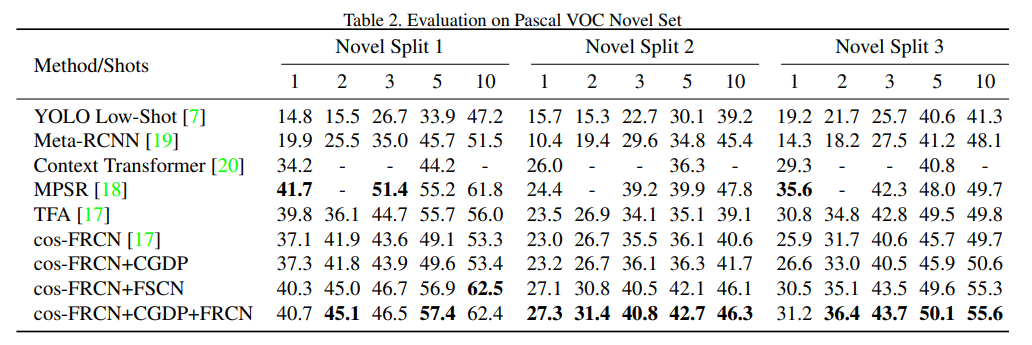
We further present the evaluation results on Pascal VOC as shown in Table. 2. Experiments are conducted under the k-shot setting with three different dataset splits, where k = 1, 2, 3, 5, 10. Our approach consistently outperform the existing approaches with significant margin in nearly all different splits/shots, which demonstrates that the effectiveness of the proposed few-shot classification refinement mechanism. It also worth to note that there is no significant performance gain when introducing CGDP into the training of cos-FRCN, which is quite different from the results on MS-COCO. We conjecture this is because Pascal VOC contains much less unlabeled objects than MS-COCO, which makes the problem of distractors less obvious.
我们进一步给出了Pascal VOC的评估结果,如表2所示。实验在k-shot设置下进行,使用三种不同的数据集分割,其中k=1、2、3、5、10。我们的方法在几乎所有不同的分割/样本中都始终优于现有方法,具有显著的优势,这表明所提出的少镜头分类细化机制的有效性。还值得注意的是,将CGDP引入cos FRCN的训练时,没有显著的绩效提升,这与MS-COCO的结果大不相同。我们推测这是因为Pascal VOC比MS-COCO含有更少的未标记物体,这使得干扰物的问题不那么明显。
5 结论
This paper casts a new viewpoint to address the challenging FSOD problem from both the architecture limitation and destructive distractor phenomenon, where a two-level learning approach is proposed to jointly address the above issues in a unified manner. First, we propose a architecture-level enhancement, where a novel few-shot correction network is introduced to alleviate the burden of category confusion. Second, instead of blindly treating distractor samples, the data-level learning strategies are proposed to separatelyaddress the few-shot adaption for both the base detector and FSCN. CGDP effectively excludes the distractors for the base detector adaptation by a confidence-guided filtering strategy, while the semi-supervised distractor utilization loss make use the distractors for boosting the data-scarce classes in FSCN. Remarkably, through fusing the proposed CGDP with the FSCN, we are the first to propose an integrated FSOD framework with excellent few-shot performance and incredible knowledge retention ability
本文从体系结构局限性和破坏性干扰现象两个方面提出了解决具有挑战性的FSOD问题的新观点,提出了一种两级学习方法,以统一的方式共同解决上述问题。首先,我们提出了一种架构级的增强,其中引入了一种新的少样本校正网络,以减轻类别混淆的负担。其次,提出了数据级学习策略来分别解决基本检测器和FSCN的少样本自适应问题,而不是盲目地处理干扰样本。CGDP通过置信度引导的滤波策略有效地排除了基本检测器自适应的干扰因素,而半监督干扰因素利用率损失则利用这些干扰因素来提高FSCN中的数据稀缺类。值得注意的是,通过将提出的CGDP与FSCN融合,我们首次提出了一个集成的FSOD框架,该框架具有出色的少样本性能和难以置信的知识保留能力

