
- 1clion下批量删除断点
- 2Gradle入门_graddle allprojects mavenlocal mavencentral
- 3【计算机网络】HTTP(下)
- 4BFS算法 蓝桥杯长草问题
- 5虚幻材质编辑器基础——如何连接一个最基本的材质_node texturesampleparameter2d
- 6linux redhalt7 重装驱动实录,复习linux系统的命令行知识_linux7重新安装显卡驱动程序
- 7Lilliefors正态性检验_lilliefors检验
- 8解决Pycharm打印结果折叠问题_pandas head print不折叠
- 9MatLab Kmeans聚类_matlab kmeans++
- 10远程桌面无法连接上(管理员已结束了会话)的解决方法
b+树时间复杂度_数据结构与算法——最小生成树
赞
踩

1 引言
在之前的文章中已经详细介绍了图的一些基础操作。而在实际生活中的许多问题都是通过转化为图的这类数据结构来求解的,这就涉及到了许多图的算法研究。
例如:在 n 个城市之间铺设光缆,以保证这 n 个城市中的任意两个城市之间都可以通信。由于铺设光缆的价格很高,且各个城市之间的距离不同,这就使得在各个城市之间铺设光缆的价格不同。那么如何选择铺设线路的方案,才能使费用最低呢?
这就涉及到我们今天要研究的图的最小生成树问题。
2 重要概念
在学习最小生成树之前需要先明确几个重要概念。连通图:在无向图中,若任意两个顶点与都有路径相通,则称该无向图为连通图。强连通图:在有向图中,若任意两个顶点与都有路径相通,则称该有向图为强连通图。连通网:在连通图中,若图的边具有一定的意义,每一条边都对应着一个数,称为权;权代表着连接连个顶点的代价,称这种连通图叫做连通网。生成树:一个连通图的生成树是指一个连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边。一颗有n个顶点的生成树有且仅有n-1条边,如果生成树中再添加一条边,则必定成环。最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。
3 普里姆算法—Prim算法
普里姆算法(Prim算法)是加权连通图里生成最小生成树的一种算法。该算法于1930年由捷克数学家沃伊捷赫·亚尔尼克发现;并在1957年由美国计算机科学家罗伯特·普里姆独立发现;1959年,艾兹格·迪科斯彻再次发现了该算法。因此,在某些场合,普里姆算法又被称为DJP算法、亚尔尼克算法或普里姆-亚尔尼克算法。
3.1 算法流程
(1)对于一个加权连通图,其顶点集合为V,边集合为E。从集合V中任选一个顶点作为初始顶点,将该顶点标为已处理;
(2)已处理的所有顶点可以看成是一个集合U,计算所有与集合U中相邻接的顶点的距离,选择距离最短的顶点,将其标记为已处理,并记录最短距离的边;
(3)不断计算已处理的顶点集合U和未处理的顶点的距离,每次选出距离最短的顶点标为已处理,同时记录最短距离的边,直至所有顶点都处理完。
(4)最终,所有记录的最短距离的边构成的树,即是最小生成树。
3.2 算法图解
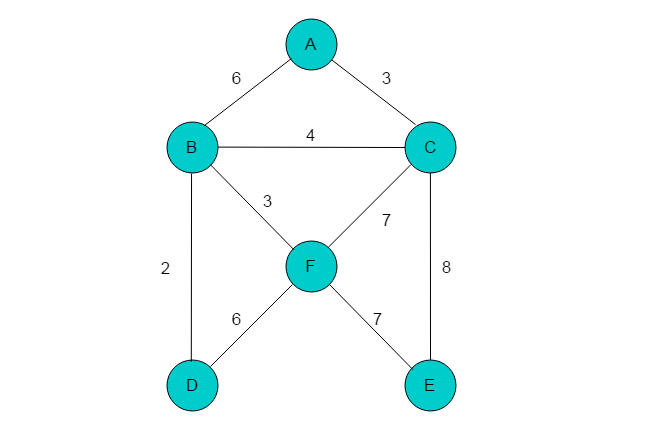
例如:图3.2.1所示的带权无向图,采用Prim算法构建最小生成树过程如下。
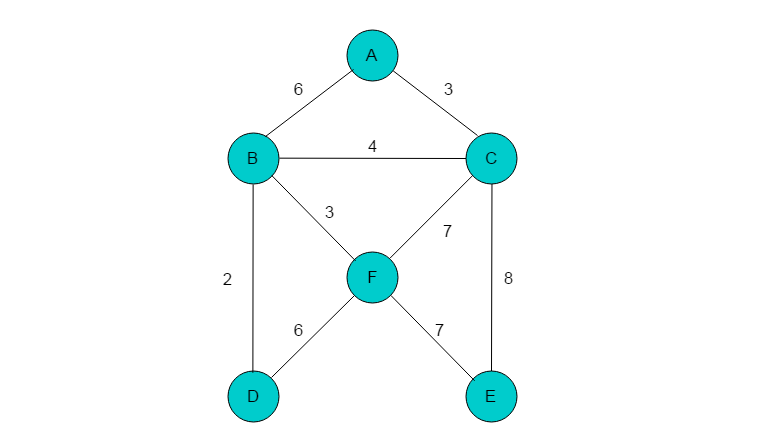
(1)首先,选取顶点A作为起始点,标记A,并将顶点A添加至集合U中。
(2)集合U中只有一个顶点A,与A邻接的顶点有B和C,B、C距A的距离分别为6、3。选择距离最短的边(A,C),将C标记,并将C添加至集合U中。
(3)集合U中顶点为A和C。与顶点A邻接的有B、C,对应距离为6、3。与C邻接的顶点有B、F、E,对应的距离为4、7、8。由于顶点A、C均被标记,故不能选择距离为3的路径。此时应选择距离最短边(C,B)。标记B、并将B添加至集合U中。
(4)集合U新加入顶点B。与顶点B邻接顶点有A、C、D、F。A、C已经在集合内,不能再被选取。顶点B到顶点D、F的距离分别为2、3。顶点C到顶点E、F距离分别为7、8。因此选择距离最短边(B,D),将D标记,并将D添加至集合U中。
(5)集合U中顶点有A、B、C、D。顶点A无可选顶点。顶点B可选顶点有F,距离为3。顶点C可选顶点有E、F,对应距离分别为8、7。顶点D可选顶点为F,对应距离为6。因此选取距离最短的边(B,F),标记F,并将F添加至集合U中。
(6)集合U中顶点有A、B、C、D、F。顶点A、B、D均无可选顶点。顶点C可选顶点为E,对应距离为8。顶点F可选顶点为E,对应距离为7。选取距离最短的边(F,E),标记E,将E添加至集合U中。
(7)集合U中顶点有A、B、C、D、E、F,但是均没有可选顶点,树的生成过程结束。
3.3 性能分析
Prim算法使用邻接矩阵来保存图的话,时间复杂度是O(N2),使用二叉堆优化Prim算法的时间复杂度为O((V + E) log(V)) = O(E log(V))。
4 克鲁斯卡算法——Kruskal算法
4.1 算法流程
(1)把图中的所有边按代价从小到大排序。
(2)把图中的n个顶点看成独立的n棵树组成的森林。
(3)按权值从小到大选择边,所选的边连接的两个顶点ui,vi。ui,vi应属于两颗不同的树,则成为最小生成树的一条边,并将这两颗树合并作为一颗树。
(4)重复步骤(3),直到所有顶点都在一颗树内或者有n-1条边为止。
4.2 算法图解
例如:图4.2所示的无向图,采用Kruskal算法构建最小生成树过程如下。
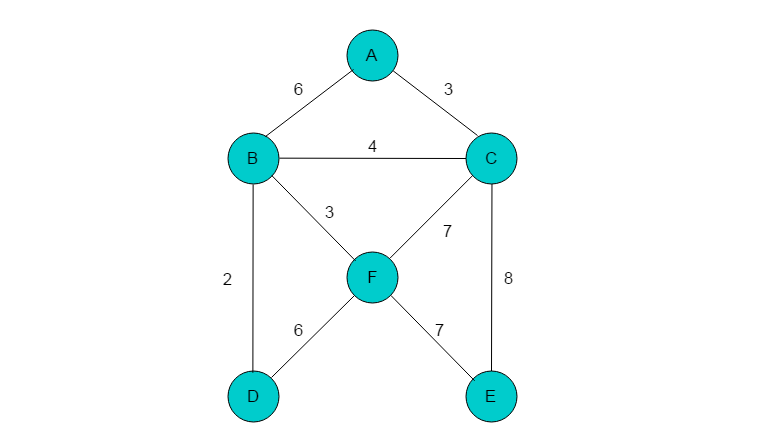
(1)首先将所有的边按照代价大小进行排序,排序结果为(B,D),(B,F)(A,C),(B,C),(A,B),(D,F),(E,F),(C,E)。
(2)代价最小边为(B,D),顶点B、D不在同一棵树上,将顶点B、D合并到一棵子树。
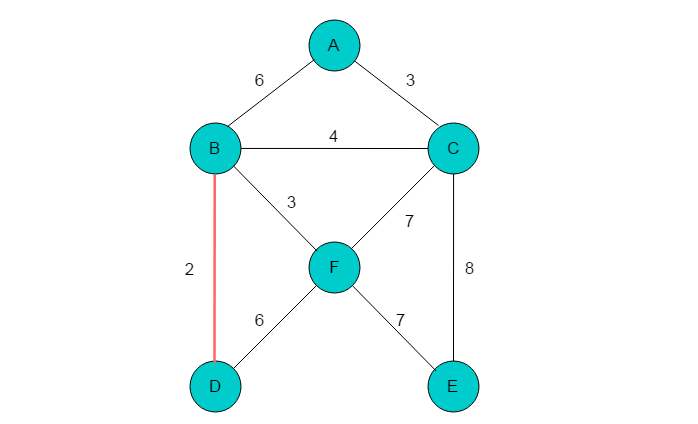
(3)代价最小边为(B,F),顶点B、F不在同一棵树上,将顶点B、F合并到一棵子树。
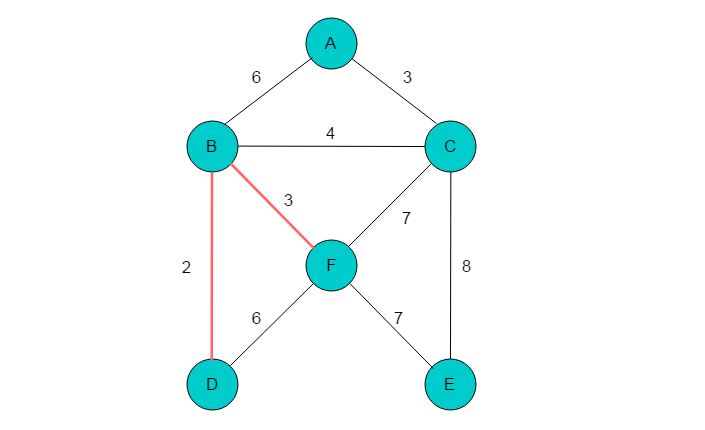
(4)代价最小边为(A、C),顶点A、C不在同一棵树上,将顶点A、C合并到一棵子树。
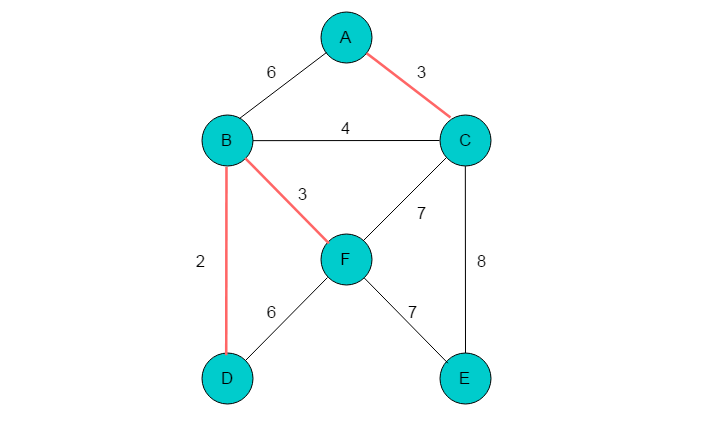
(5)代价最小边为(B,C),顶点B、C不在同一棵树上,将顶点B、C合并到一棵子树。
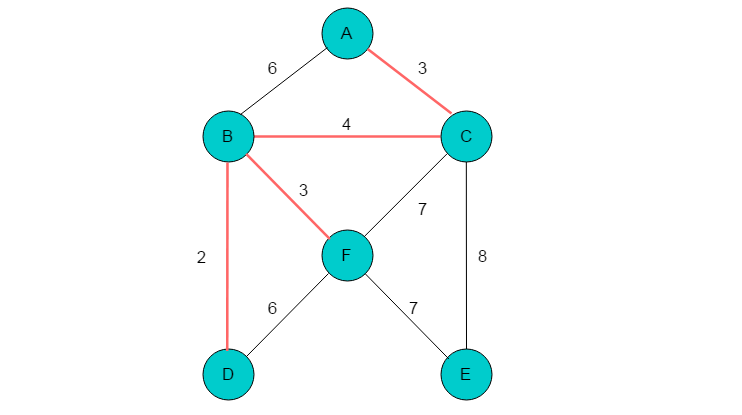
(6)代价最小边为(A,B),顶点A、B在同一棵树上,因此不能选择此边。
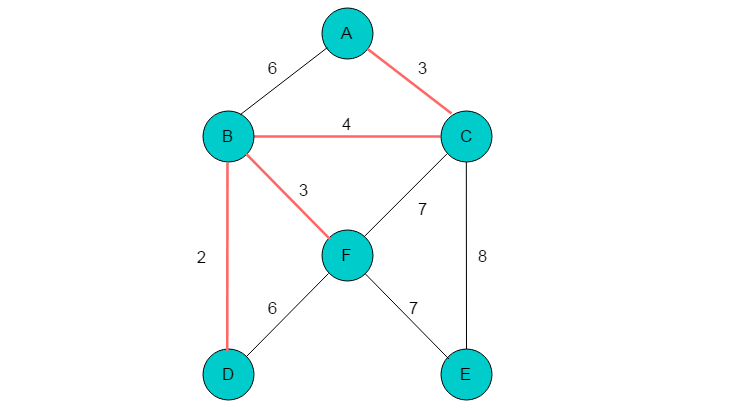
(7)代价最小边为(D,F),顶点D、F在同一棵树上,因此不能选择此边。
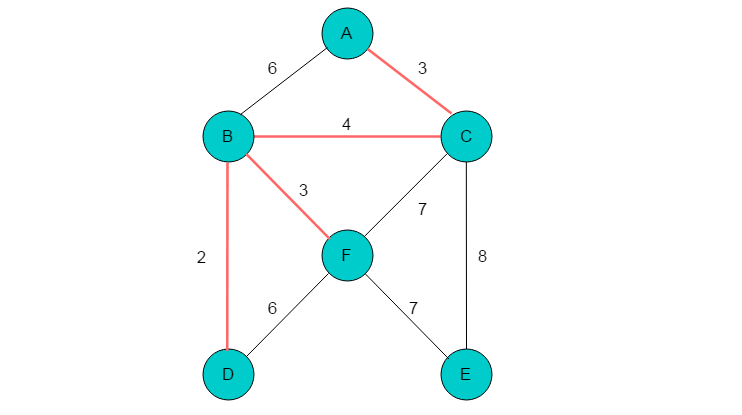
(8)代价最小边为(E,F),顶点E、F不在同一棵树上,将顶点E、F合并到一棵子树。
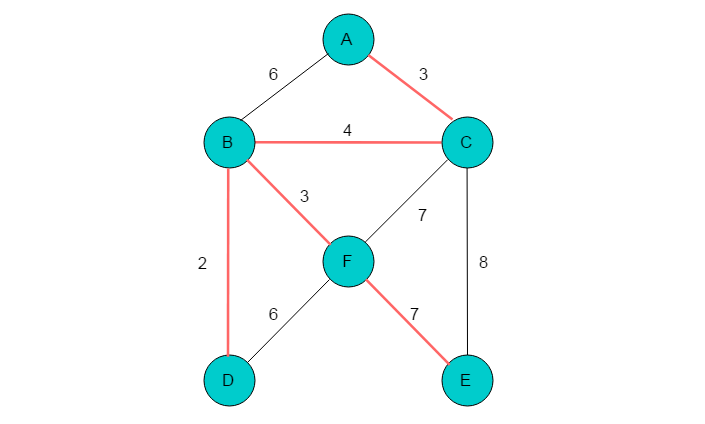
(9)代价最小边为(C,E),顶点C、E在同一棵树上,因此不能选择此边。
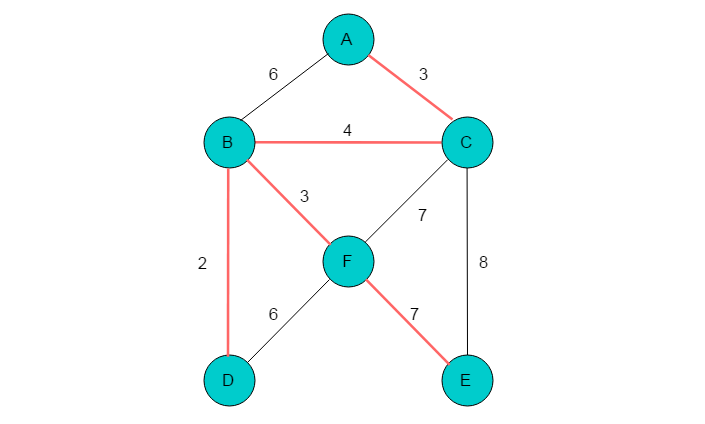
(10)所有顶点均在同一棵树内,生成过程完毕。最小生成树为:
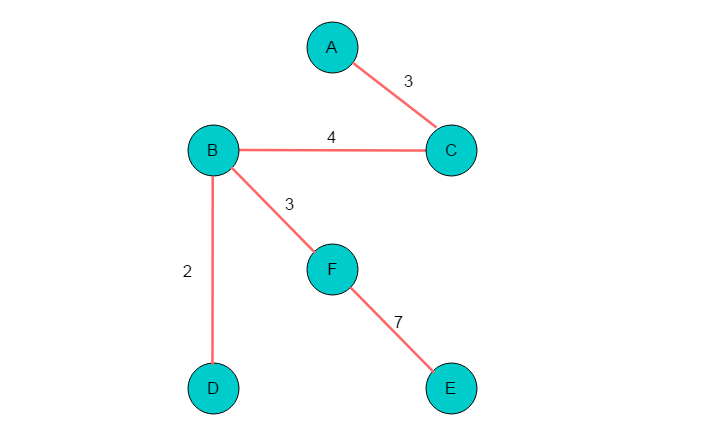
4.3 性能分析
Kruskal算法为了提高每次贪心选择时查找最短边的效率,可以先将图G中的边按代价从小到达排序,则这个操作的时间复杂度为O(elge),其中e为无向连通网中边的个数。对于两个顶点是否属于同一个连通分量,可以用并查集的操作将其时间性能提高到O(n),所以Kruskal算法的时间性能是O(elge)。
5 Boruvka算法
Boruvka算法是最小生成树算法中最为古老的算法。类似于Kruskal算法,Bruvka算法也是逐步添加子树的方式构建。但是Bruvka算法是分步完成,每一步都增加多条边。在每一步中,会连接每一棵子树与另一棵子树的最短边,再将所有这样的边都增加到最小生成树中。
5.1 算法流程
(1)用定点数组记录每个子树(一开始是单个定点)的最近邻接顶点。
(2)对于每一条边进行处理(类似Kruskal算法)。如果这条边连成的两个顶点同属于一个集合,则不处理,否则检测这条边连接的两个子树,如果是连接这两个子树的最小边则合并。
5.2 算法图解
例如:图5.2所示的无向图,使用Boruvka算法构建最小生成树过程如下。
(1)找到各个顶点的最近邻接点。A最近为C,B最近为D,C最近为A,D最近为B,E最近为B,F最近为E,标记各个最近邻接顶点之间的边,得到2个子树。因此还需要一条边将两个子树连接起来。
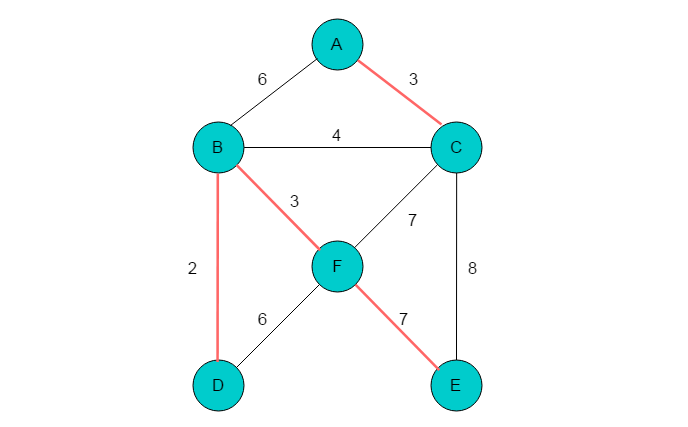
(2)对每一条边进行处理。(A,C)、(B,D)、(B,F)、(D,F)、(E,F)边分别属于同一子树,因此不处理。在剩余的边(A,B)、(B,C)、(C,F)、(C,E)中选取一条边来连接子树。选取权值最小的边(B,C)进行子树合并。
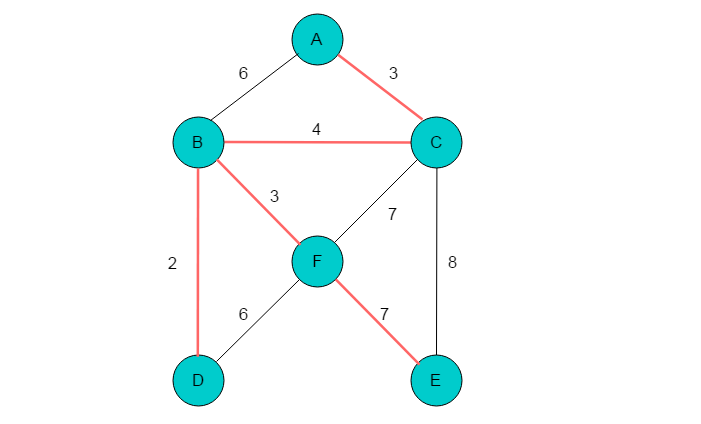
(3)得到最终的最小生成树如下:
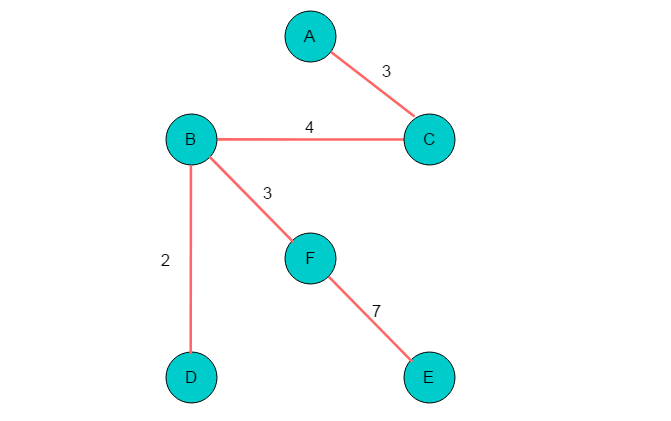
5.4 性能分析
每次循环迭代时,每棵树都会合并成一棵较大的子树,因此每次循环迭代都会使子树的数量至少减少一半.所以,循环迭代的总次数为O(logn)。每次循环迭代所需要的计算时间:每次检查所有边的时间复杂度为O(m)。所以总的复杂度为O(e*logv)。
6 基于权矩阵的最小生成树算法
徐建军、沙力妮等发表了一篇一种新的最小生成树算法文章。此算法是从最小生成树的性质出发,通过构造权矩阵的方式来得到图的最小生成树。
设图G1是图G的最小生成树,则G1具有如下性质:
(1)G1中的各条边权值之和最小。
(2)G1中有n个顶点n-1条边。
(3)G1必须是连通的且无回路。
6.1 算法流程
(1)根据图的顶点数n以及各边对应的权值建立权矩阵A。矩阵A的主对角线上元素A[i][i]为0。若顶点i与顶点j不直接相连,A[i][j]=0 。
(2)在权矩阵A中,按行搜索非零最小元。若某行中有几个非零最小元,则任取其一。记录各行的非零最小元及其脚标,并将权矩阵中对应的该元素赋值为0,其关于对角线对称的元素也应为0,得到新的权矩阵B(这样后面寻找行的次非零最小元就转换成寻找该行的非零最小元了)。比较找到的所有非零最小元,如果同时存在 A[i][j]、 A[j][i],则去掉其中一个。统计此时非零最小元的个数k。
(3)比较k与n-1的大小。若k=n-1则由这k个元素对应的k条边构成的图即为所求最小生成树,生成过程结束。若k﹤n-1,说明这k条边构成的图没有连通,转步骤(4)。
(4)在剩下的边中寻找权值最小的(n-1-k)条边使k个非零最小元对应的k条边构成的图连通。
6.2 实例说明
例如:图6.2.1所示的带权无向图,使用权矩阵方法建立最小生成树过程。
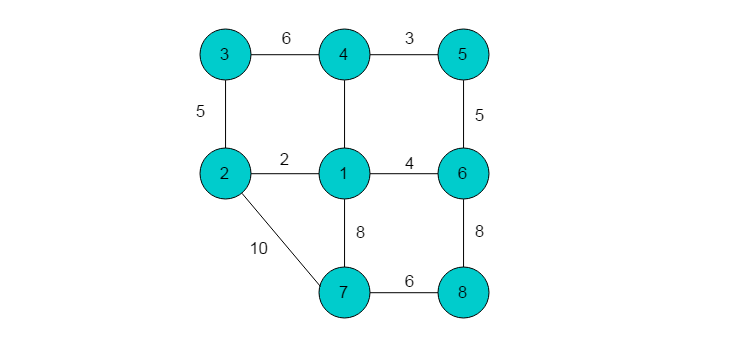
(1)根据图中的顶点、边以及权值建立权矩阵A。
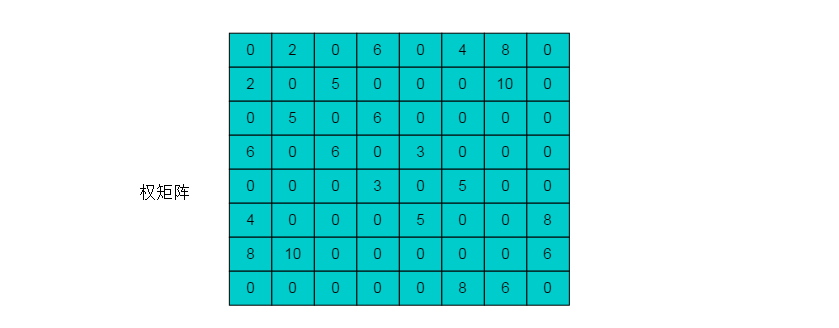
(2)在权矩阵A中,按行搜索最小非零元。记录各行的最小非零元及其脚标。按行找到的非零最小元依次是: A[1][2], A[2][1], A[3][2], A[4][5], A[5][4], A[6][1], A[7][8],A[8][7]。将 A中这些元素所对应的值全部变为0。在找出的所有非零最小元中同时出现了A[1][2]和A[2][1];A[7][8]和A[8][7]; A[4][5]和A[5][4],故可去掉A[2][1],A[5][4]和A[8][7]。剩下的最小非零元为 A[1][2],A[3][2],A[4][5],A[6][1],A[7][8]。统计非零最小元素个数k=5。
(3)比较k与n-1的大小,k=5,n-1=7,k (4)寻找权值最小的(n-1-k)条边使k个最小非零元对应的边构成的图连通。n-1-k=8-1-5=2,说明还需要两条边才能使已有边构成的图连通。第一个最小非零元A[1][2]的脚标12分别与A[3][2],A[6][1]的脚标32、61有交集,说明这三个元素对应的边是连通的。将脚标12,32,61 取并集,再判断此并集与剩余元素A[4][5]、 A[7][8]的脚标是否有交集。很明显,并集(1236)与45、78 都没有交集,且45与78之间也没有交集。 因此我们知道A[4][5]与A[7][8]所对应的边互不相连,并且和其他三条边也没有连通。
在步骤(2)中已经将A[4][5]和A[5][4]的值变为0了,所以只需在现有权矩阵A的第4行和第5行中分别找出一个非零最小元,二者取较小值,从而得到A[5][6]。在现有权矩阵A的第7行和第8行中分别找出一个非零最小元,二者取较小值。第7行和第8行的非零最小元 A[7][1]= A[8][6],可任取其一。这里取A[8][6]。A[5][6]和A[8][6]分别对应的边就是我们要寻找的两条边。这样,由A[1][2],A[3][2],A[4][5],A[5][6],A[6][1],A[7][8],A[8][6]分别对应的边构成的图即为所求的最小生成树。最终结果如图6.2.2所示。
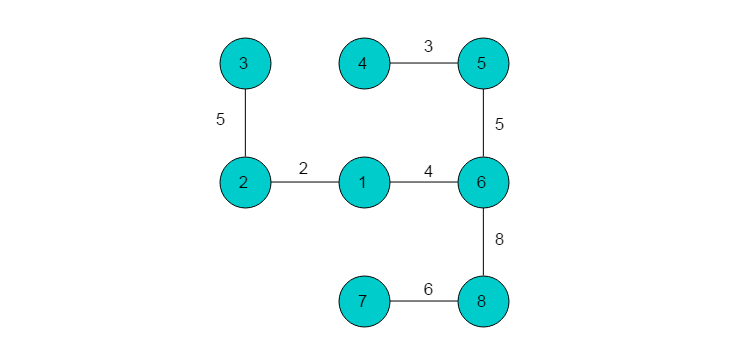
7 结语
图的最小生成树算法种类有很多,但是以 Prim 算法和 Kruskal 算法最为经典。希望读者在读完本篇文章后,不仅能理解最小生成树的构造过程,同时也能理解各类算法的解题思想。
推荐阅读
拜托,面试官别问我「布隆」了
数据结构与算法: 三十张图弄懂「图的两种遍历方式」
昨天,终于拿到了腾讯 offer
几道和「二叉树」有关的算法面试题
几道和散列(哈希)表有关的面试题
一道看完答案你会觉得很沙雕的「动态规划算法题」
几道和「堆栈、队列」有关的面试算法题
链表算法面试问题?看我就够了!

欢迎关注


