
- 1Canvas画图-一个比想象中更骚气的圆(渐变圆环)
- 2Eclipse 使用git 教程_eclipse用git上传代码时关闭遍历文件的过程
- 3如何使用Android Studio开发Gradle插件_android studio gradle plugin pom
- 4巧用可变参数宏、编译器内置宏和printf输出调试信息_vba宏 输出调试信息
- 5ChatGPT发布一周年,我再也离不开它了!!还有人不会用??你都在什么时候用到ChatGPT_clue-s,plus,flus模型有什么区别
- 6k8s kubernetes | kubectl kubeadm 命令行补齐 及 登录凭证 其他账户k8s权限_kube连接凭证怎么配置
- 7GPU 图像并行处理
- 8循环结构—while与for语句_编写一个能输出不包括自身的 n 的所有因子的小程序。
- 9xcode国际化工具genstrings体验总结
- 10java基础学习 day25(二维数组)_java二维数组应用场景
Hugging face预训练模型下载和使用_vocab.json 哪里下载
赞
踩
Huggingface
Huggingface是一家公司,在Google发布BERT模型不久之后,这家公司推出了BERT的pytorch实现,形成一个开源库pytorch-pretrained-bert。后来这家公司又实现了其他的预训练模型,如GPT、GPT2、ToBERTa、T5等。此时,开源库的名字还叫pytorch-pretrained-bert就不太合适了,于是他们就将开源库的名字改成transformers,transformers包括各种模型的实现。
简而言之:Google发布的原始BERT预训练模型(训练好的参数)是基于Tensorflow的,Huggingface是基于pytorch的。
预训练模型下载
huggingface官网的这个链接:https://huggingface.co/models可以搜索到当前支持的模型,常用的预训练模型有以下几种:
BERT-Large, Uncased (Whole Word Masking)
语言种类:英文
网络结构:24-layer, 1024-hidden, 16-heads
参数规模:340M
BERT-Large, Cased (Whole Word Masking)
语言种类:英文
网络结构:24-layer, 1024-hidden, 16-heads
参数规模:340M
BERT-Base, Uncased
语言种类:英文
网络结构:12-layer, 768-hidden, 12-heads
参数规模:110M
BERT-Base, Cased
语言种类:英文
网络结构:12-layer, 768-hidden, 12-heads
参数规模:110M
-
Uncased和Cased:Uncased模型在WordPiece tokenization之前会转换成小写,如John Smith变为john smith. Uncased模型还会去除发音标记(accent markers).
-
Cased模型保留了大小写和发音标记。一般来说Uncased模型更好。但是在case信息也有作用的场景下,就应该使用cased模型
(e.g., Named Entity Recognition or Part-of-Speech tagging)。 -
Multilingual表示预训练时使用多种语言的语料,Chinese表示预训练时使用中文,没有额外标注的则表示用英文语料训练。
-
ext差别是增加了训练数据集同时也增加了训练步数。
总之,不管预训练模型的种类如何的多,他们都是基于BERT的魔改模型,只不过是层数不同或者使用的训练语料不同,训练轮次不同等。做中文相关任务先考虑chinese-roberta-wwm-ext、ERNIE预训练模型吧。
下载
使用预训练模型需要下载模型的文件,最关键的是三个文件:
第一个是配置文件,config.json
第二个是词典文件,vocab.json或vocab.txt
第三个是预训练模型文件,pytorch_model.bin或tf_model.h5。 根据你使用的框架选择
下面具体看看下载方式:
首先,打开预训练模型所在网址,比如ERNIE是:https://huggingface.co/nghuyong/ernie-1.0
其次,点击Files and versions选项卡,就可以找到需要下载的文件:config.json、pytorch_model.bin、vocab.txt
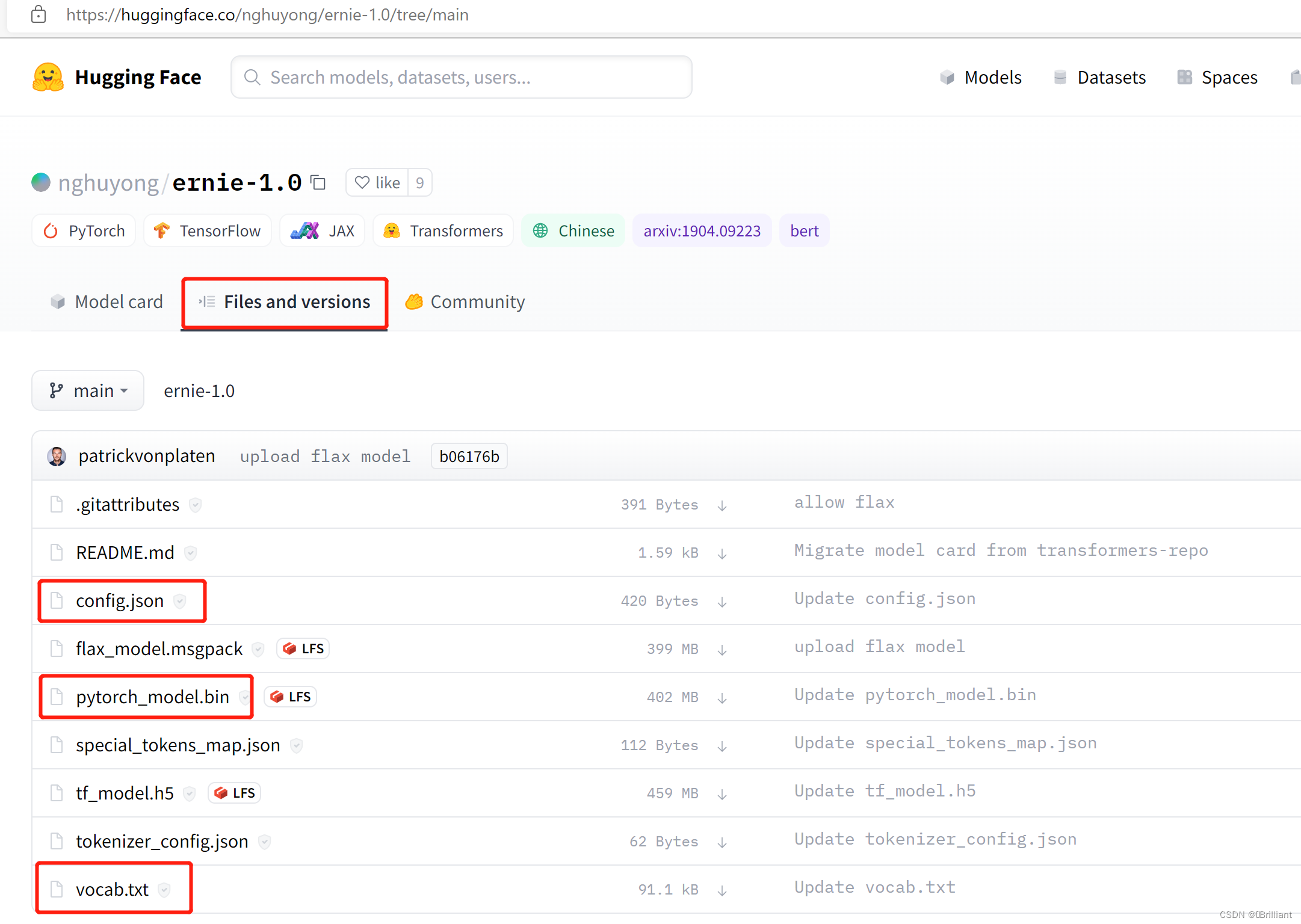 ERNIE预训练模型包含的文件当然,你也可以把上面的所有文件都下载下来,这样肯定不会出错。
ERNIE预训练模型包含的文件当然,你也可以把上面的所有文件都下载下来,这样肯定不会出错。
预训练模型的使用(API)
transformers库最关键的三个类
- model
- tokenizer
- configuration
其他类如GPT2LMHeadModel都是对应类的子类而已,根据模型的特点进行改进。
- 使用方式一:指定模型名字
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained(“nghuyong/ernie-1.0”)
model = AutoModel.from_pretrained(“nghuyong/ernie-1.0”)
这种方式不需要下载预训练模型,函数调用过程中如果发现没有这个模型就会自动下载
- 使用方式二:指定路径
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained(“/home/models/huggingface/gpt2”)
model = AutoModel.from_pretrained(“/home/models/huggingface/gpt2”)
这种方式需要先下载好预训练模型的文件

