
- 1yolov8 瑞芯微 RKNN 的 C++部署,部署工程难度小、模型推理速度快_yolo8 c++ 推理 瑞芯微
- 2DWS(GaussDB) 通信原理&问题排查笔记_为什么gaussdb不限制连接数
- 3Gradle+IDEA使用说明
- 4android studio 启动手机报错time out 解决方案_android studio一直卡在launch app time out
- 5昆仑万维2022年净利润11.5亿元,自研天工大模型4月17日启动邀测_昆仑万维天工大模型
- 6swolle-4.4入门到精通介绍安装/多进程多线程/workerman对比(一)_swoole4
- 7Vue3组件之间通信方式
- 8【Docker】docker安装nginx及端口映射相关配置_docker nginx目录映射
- 9Ubuntu中 pytorch,tensorflow,opencv等第三方库的安装_unknown distribution
- 102024-03-21 AIGC-FastGPT-本地知识库问答系统
电商评价分析:NLP信息抽取技术在用户评论中的应用与挖掘_事件抽取,从评论内容中抽取影响用户情感的关键事件或因素
赞
踩
一、引言
在2019年,电子商务的蓬勃发展不仅推动了消费市场的增长,也带来了海量的用户评价数据。这些数据,作为消费者对商品和服务直接反馈的载体,蕴含着巨大的价值。然而,由于其非结构化的特性,这些文本信息的分析和利用成为了一个挑战。在这样一个背景下,我参与了一个旨在通过信息抽取技术来优化电商评价系统的项目。这个系统的目标是将这些散乱的用户评论转化为有价值的洞察,帮助商家更好地理解客户需求,优化产品和服务,以及制定更有效的营销策略。通过文本分析,我们能够从这些数据中提取关键词、识别评论焦点、分析情感倾向、抽取用户观点,并最终通过可视化工具将这些信息呈现出来,为决策提供支持。
二、用户案例
在我负责的这个电商项目中,我们遇到了一个特别棘手的问题。用户的评价数据量巨大,而且每条评论都是自由格式的文本,这使得从中提取有用信息变得非常困难。比如,一位用户可能会说:“这款手机的电池续航能力真的很棒,我可以用一整天。”这句话中包含了对手机电池性能的正面评价,但我们需要从这样的非结构化文本中准确地抽取出“电池续航能力”和“一整天”这样的参数和属性。

为了解决这个问题,我们采用了信息抽取技术。首先,我们使用参数与属性抽取功能来识别和提取文本中的具体数值信息和描述性特征。在这个例子中,我们能够自动地识别出“一整天”这个时间参数,并将其与“电池续航能力”这个属性关联起来。这样,我们就能在数据库中为这款手机的电池性能创建一个详细的记录,包括用户的实际使用体验。
我们利用实体抽取技术来识别评论中提到的具体对象。在上述评论中,“手机”和“电池”都是我们需要识别的实体。通过命名实体识别(NER)技术,我们能够准确地从文本中提取这些实体,并理解它们在评论中的作用。
为了进一步理解用户的观点,我们还应用了关系抽取技术。这使我们能够识别出用户评价中的因果关系,比如“因为电池续航能力强,所以用户满意”。这种关系抽取帮助我们理解用户满意度背后的具体原因,这对于产品改进和营销策略的制定至关重要。
最后,事件抽取技术让我们能够从评论中识别出具体的事件和相关要素。例如,用户可能会提到“在一次长途旅行中,手机的导航功能非常准确”。通过事件抽取,我们可以提取出“长途旅行”这个事件,以及与之相关的“手机导航功能”和“准确”这个评价。
三、技术原理
在电商行业,评价系统是连接消费者和商家的重要桥梁。随着在线购物的普及,用户评价数据的规模和复杂性不断增长,如何有效地从这些非结构化文本中提取有价值的信息,成为了提升用户体验和商家服务质量的关键。为此,我们采用了深度学习技术,特别是自然语言处理(NLP)中的序列标注和序列到序列(Seq2Seq)模型,来构建一个高效、准确的信息抽取系统。

在项目实施过程中,我们首先利用预训练的语言模型,如BERT或GPT,来理解文本的深层语义。这些模型在大规模文本数据上进行预训练,能够捕捉语言的复杂结构,为信息抽取提供坚实的基础。随后,我们针对电商评价的特定场景,对模型进行微调,使其能够识别和理解评价文本中的关键实体,如商品名称、品牌、用户感受等。
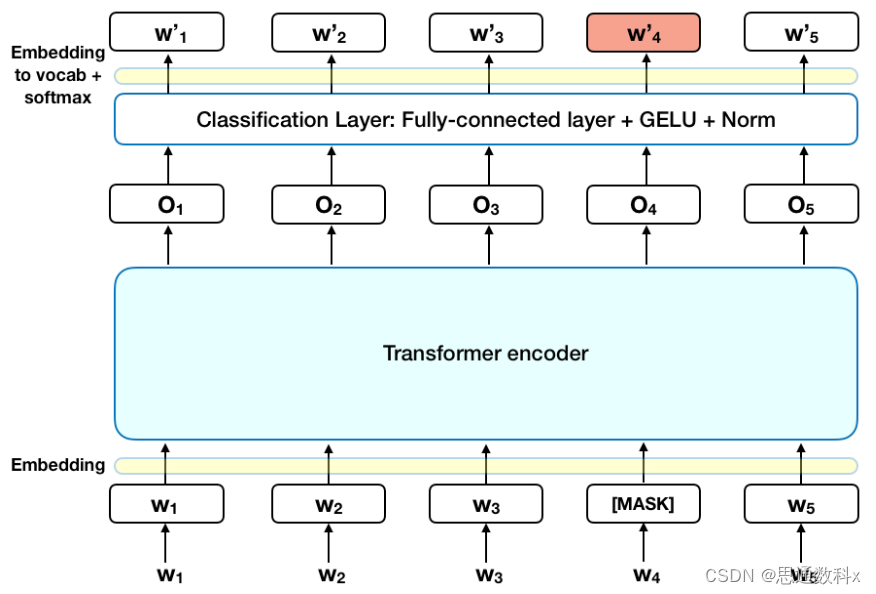
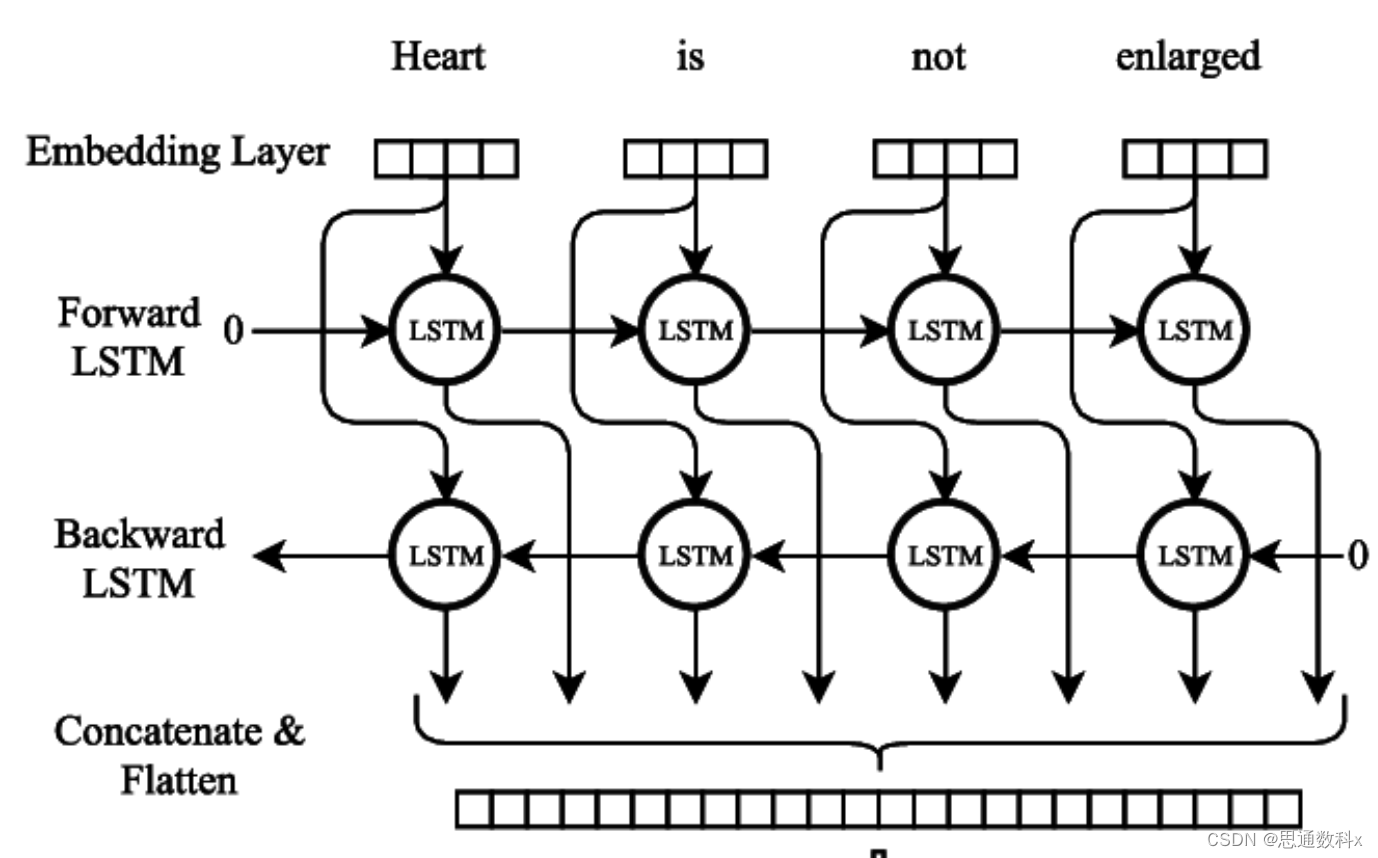
序列标注技术在我们的系统中扮演了核心角色。通过条件随机场(CRF)或双向长短时记忆网络(BiLSTM),模型能够识别文本中的命名实体,如用户提到的产品特性、服务体验等,并为它们打上相应的标签。这使得我们能够从用户评价中提取出具体的参数和属性,例如“电池续航能力”和“一整天”。
此外,Seq2Seq模型的应用使我们能够处理更复杂的信息抽取任务。例如,在用户评价中,我们不仅需要识别出实体和属性,还需要理解用户的观点和情感倾向。通过Seq2Seq模型,我们可以将用户的原始评价转换为结构化的数据,如“用户对手机电池续航能力感到满意”。
在整个过程中,我们采用了端到端的训练方法,确保模型从输入到输出的整个过程都在一个统一的框架下进行优化。这不仅提高了模型的性能,也简化了模型的部署和维护。在模型训练过程中,我们通过准确率、召回率、F1分数等指标对模型进行评估,并根据评估结果进行调整,以确保信息抽取的准确性和可靠性。
通过这些技术的应用,电商评价系统能够自动地从用户评价中提取出丰富的信息,为商家提供了宝贵的市场洞察。这不仅提高了商家对用户反馈的响应速度,也帮助他们更好地理解市场需求,从而在激烈的市场竞争中保持领先地位。
四、技术实现
在撰写文章的过程中,我意识到技术原理部分对于非专业读者来说可能较为复杂。为了确保文章的可读性和专业性,我决定利用一个现成的自然语言处理(NLP)平台来辅助我的研究和分析。这个平台名为“语音视频&文本图片多模态AI能力引擎平台”,可以通过以下链接访问:语音视频&文本图片多模态AI能力引擎平台![]() https://nlp.stonedt.com/
https://nlp.stonedt.com/

我使用这个平台的方式如下:
1. 数据收集:我首先收集了与项目相关的50-200条数据样本,这些样本全面覆盖了项目所需的各种情况。这些数据包括了用户的评价文本,它们将作为信息抽取的基础。
2. 数据清洗:在收集到数据后,我进行了数据预处理,包括去除无关信息、纠正拼写错误、标准化术语等,以确保数据质量。
3. 样本标注:利用平台的在线标注工具,我对数据进行了标注。这个工具帮助我快速准确地标记文本中的实体、关系等。我确保所有标注者遵循相同的标准,以保证标注的一致性。标注完成后,为了确保标注质量,我进行了多轮标注和校对。
4. 样本训练:根据标注的数据,我提取了文本特征,如词性标注、命名实体识别(NER)、依存句法分析等。然后,我使用这些标注好的数据样本来训练模型,通过调整模型参数来优化性能。
5. 模型评估:我选择了适当的评估指标,如精确度、召回率、F1分数等,来衡量模型的性能。我使用交叉验证等方法来确保模型的泛化能力,避免过拟合。根据评估结果,我调整了模型参数,进行了多次迭代,以达到最佳性能。
6. 结果预测:训练好的模型被部署到生产环境中,以便对新的文本数据进行信息抽取。模型接收新的文本输入,自动执行信息抽取任务,输出结构化的结果。
整个过程中,我通过平台的web界面进行了数据标注、训练、评估预测,以及模型发布和预测,无需编写任何代码。这极大地提高了我的工作效率,并且使得整个信息抽取过程更加直观和易于管理。通过这个平台,我能够将复杂的技术原理转化为实际的应用,从而在文章中为读者提供一个清晰、实用的技术实现案例。
在上述技术实现的基础上,我进一步利用了“语音视频&文本图片多模态AI能力引擎平台”的观点抽取功能,以更深入地分析用户评价。以下是我使用该平台进行观点抽取的代码示例,以及相应的输出示例注释:
- # 码示例:使用平台的观点抽取功能
-
- import requests
-
-
- # 初始化请求参数
-
- url = "https://nlp.stonedt.com/api/extractAppraise"
-
- headers = {
-
- "secret-id": "你的secret-id",
-
- "secret-key": "你的secret-key"
-
- }
-
- data = {
-
- "text": "荣威Ei5 2021款 500 倾城版,我对这车最满意的就是这辆车的操控和空间了..."
-
- }
-
-
- # 发送POST请求
-
- response = requests.post(url, json=data, headers=headers)
-
-
- # 解析返回的数据
-
- extracted_appraisals = response.json()
-
-
- # 输出示例
-
- for appraisal in extracted_appraisals[0]['评价维度']:
-
- print(f"评价维度: {appraisal['text']}")
-
- print(f"起始位置: {appraisal['start']} - 结束位置: {appraisal['end']}")
-
- print(f"准确率: {appraisal['probability']:.2f}")
-
- print("情感倾向:", end=' ')
-
- for sentiment in appraisal['relations']['情感倾向[正向,负向]']:
-
- print(f" {sentiment['text']} - 概率: {sentiment['probability']:.2f}")
-
- print("观点词:", end=' ')
-
- for opinion in appraisal['relations']['观点词']:
-
- print(f" {opinion['text']} - 概率: {opinion['probability']:.2f}")
-
- print() # 打印空行以分隔不同的评价维度

- 评价维度: 方向盘
-
- 起始位置: 76 - 结束位置: 79
-
- 准确率: 0.46
-
- 情感倾向: 正向 - 概率: 0.99
-
- 观点词: 适中 - 概率: 0.46
-
-
- 评价维度: 空间
-
- 起始位置: 37 - 结束位置: 39
-
- 准确率: 0.59
-
- 情感倾向: 正向 - 概率: 0.99
-
-
- 评价维度: 隔音性
-
- 起始位置: 149 - 结束位置: 152
-
- 准确率: 0.39
-
- 情感倾向: 负向 - 概率: 0.65
-
- 观点词: 不是很强 - 概率: 0.27
-
-
- 评价维度: 车身
-
- 起始位置: 60 - 结束位置: 62
-
- 准确率: 0.60
-
- 情感倾向: 正向 - 概率: 0.99
-
- 观点词: 平稳 - 概率: 0.99
-
-
- 评价维度: 设计
-
- 起始位置: 115 - 结束位置: 117
-
- 准确率: 0.64
-
- 情感倾向: 正向 - 概率: 0.99
-
- 观点词: 合理 - 概率: 0.96
通过上述伪代码和输出示例,我们可以看到,平台能够准确地从用户评价中抽取出关键的评价维度,并给出相应的情感倾向和观点词,以及它们在文本中的位置和准确率。这些信息对于理解用户的真实感受和偏好至关重要,可以帮助商家针对性地改进产品和服务。
五、项目总结
本项目通过实施先进的信息抽取技术,显著提升了电商评价系统的效能。我们成功地将海量的用户评价数据转化为结构化的洞察,极大地提高了数据分析的效率和准确性。商家现在能够快速识别产品特性与用户满意度之间的关联,如电池续航能力与用户满意度的正向关系。这种转变不仅优化了产品开发流程,还为营销策略提供了数据支持,使得商家能够更精准地满足市场需求,增强了市场竞争力。此外,通过自动化的信息抽取过程,我们减少了人工成本,提高了处理速度,使得商家能够实时响应市场变化,保持领先地位。
六、开源项目(本地部署,永久免费)
思通数科的多模态AI能力引擎平台是一个企业级解决方案,它结合了自然语言处理、图像识别和语音识别技术,帮助客户自动化处理和分析文本、音视频和图像数据。该平台支持本地化部署,提供自动结构化数据、文档比对、内容审核等功能,旨在提高效率、降低成本,并支持企业构建详细的内容画像。用户可以通过在线接口体验产品,或通过提供的教程视频和文档进行本地部署。

