- 1C++显示调用析构函数_显式调用析构函数
- 2【自然语言处理】NLP入门(七):1、正则表达式与Python中的实现(7):常用正则表达式、re模块:findall、match、search、split、sub、compile_nlp开发环境和正则表达式的应用
- 3【数据结构篇】线性表1 --- 顺序表、链表 (万字详解!!)_数据结构线性表
- 4【软件工程】建模工具之开发各阶段绘图——UML2.0常用图实践技巧(功能用例图、静态类图、动态序列图&状态图&活动图)_功能模块用uml拿个图
- 5怎么开发一个预约小程序_一键预约新体验
- 6展现AI与自动化测试技术之间的神奇化学反应_ai自动化测试
- 7国内ChatGPT大数据模型_国内chatgpt大模型
- 8串口通信Serial Port类C++实现_串口通讯 c++ serialport
- 9计算机网络 课后题答案解析,计算机网络课后习题和答案解析
- 10Vmware ESXi6.5升级6.7_esxi670-202011001
交叉注意力融合时空特征的TCN-Transformer并行预测模型_tcn 和transformer
赞
踩
独家 | 高创新预测模型

往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较-CSDN博客
风速预测(二)基于Pytorch的EMD-LSTM模型-CSDN博客
风速预测(三)EMD-LSTM-Attention模型-CSDN博客
风速预测(四)基于Pytorch的EMD-Transformer模型-CSDN博客
风速预测(五)基于Pytorch的EMD-CNN-LSTM模型-CSDN博客
风速预测(六)基于Pytorch的EMD-CNN-GRU并行模型-CSDN博客
风速预测(七)VMD-CNN-BiLSTM预测模型-CSDN博客
CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)-CSDN博客
CEEMDAN +组合预测模型(CNN-LSTM + ARIMA)-CSDN博客
CEEMDAN +组合预测模型(Transformer - BiLSTM+ ARIMA)-CSDN博客
CEEMDAN +组合预测模型(CNN-Transformer + ARIMA)-CSDN博客
多特征变量序列预测(一)——CNN-LSTM风速预测模型-CSDN博客
多特征变量序列预测(二)——CNN-LSTM-Attention风速预测模型-CSDN博客
多特征变量序列预测(三)——CNN-Transformer风速预测模型-CSDN博客
多特征变量序列预测(四)Transformer-BiLSTM风速预测模型-CSDN博客
多特征变量序列预测(五) CEEMDAN+CNN-LSTM风速预测模型-CSDN博客
多特征变量序列预测(六) CEEMDAN+CNN-Transformer风速预测模型-CSDN博客
多特征变量序列预测(七) CEEMDAN+Transformer-BiLSTM预测模型-CSDN博客
基于麻雀优化算法SSA的CEEMDAN-BiLSTM-Attention的预测模型-CSDN博客
基于麻雀优化算法SSA的CEEMDAN-Transformer-BiGRU预测模型-CSDN博客
多特征变量序列预测(八)基于麻雀优化算法的CEEMDAN-SSA-BiLSTM预测模型-CSDN博客
多特征变量序列预测(九)基于麻雀优化算法的CEEMDAN-SSA-BiGRU-Attention预测模型-CSDN博客
多特征变量序列预测(10)基于麻雀优化算法的CEEMDAN-SSA-Transformer-BiLSTM预测模型-CSDN博客
VMD + CEEMDAN 二次分解,BiLSTM-Attention预测模型-CSDN博客
VMD + CEEMDAN 二次分解,CNN-LSTM预测模型-CSDN博客
基于麻雀优化算法SSA的预测模型——代码全家桶-CSDN博客
VMD + CEEMDAN 二次分解,CNN-Transformer预测模型-CSDN博客
Python轴承故障诊断 (17)基于TCN-CNN并行的一维故障信号识别模型-CSDN博客
创新点:
1.利用时空卷积网络(TCN)来提取序列的全局空间特征,同时利用 Transformer 来提取序列中的长期依赖关系的时序特征,采用并行结构,加快模型的训练和推理速度;
2.利用交叉注意力进行并行网络时空特征的融合,这样可以同时考虑时序关系和位置关系,从而更好地捕捉时空序列数据中的特征,
增强特征的表示能力来实现高精度的预测。
注意:此次产品,我们还有配套的模型讲解和参数调节讲解!

前言
本文基于前期介绍的电力变压器(文末附数据集),介绍一种基于交叉注意力融合时空特征的TCN-Transformer并行预测模型,以提高时间序列数据的预测性能。

该模型 多变量特征 | 单变量序列预测都适用!
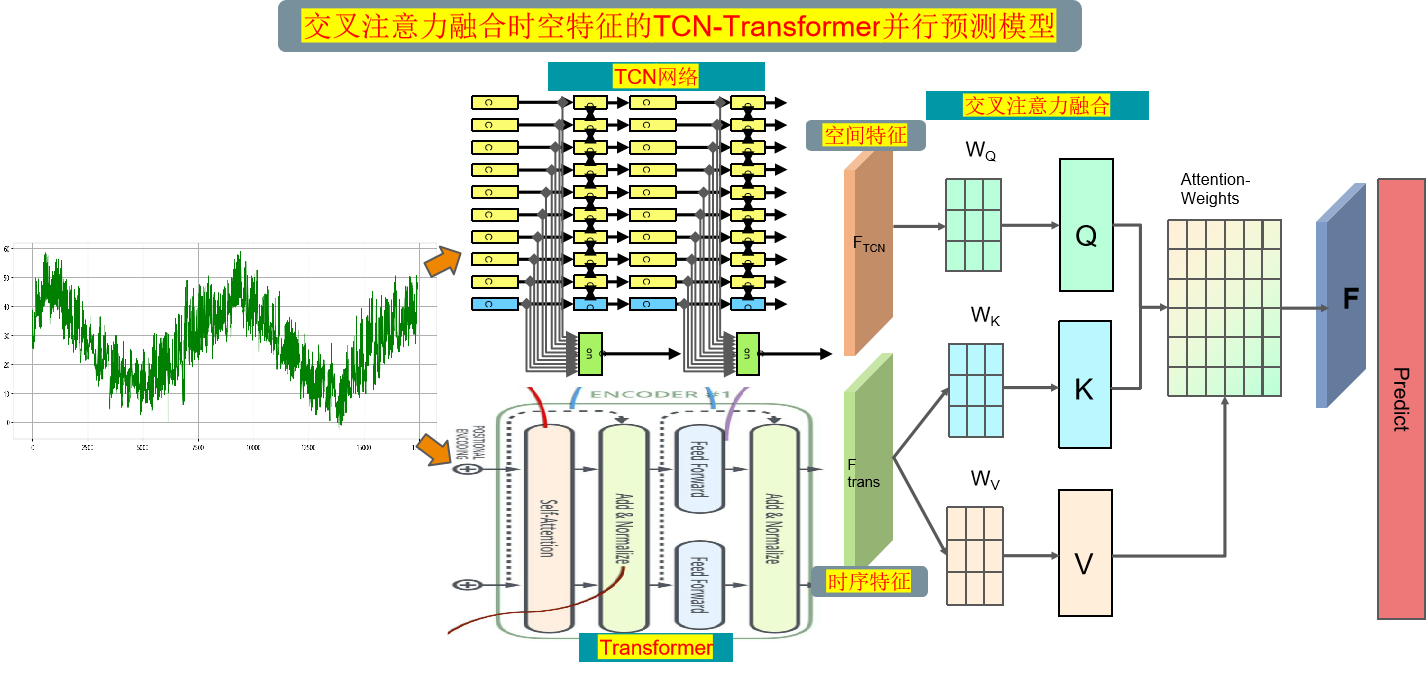
1 模型整体结构
模型整体结构如下所示,多特征变量时间序列数据先经过TCN网络提取全局特征,同时数据通过Transformer编码器层提取时序特征,使用交叉注意力机制融合空间和时序特征,通过计算注意力权重,使得模型更关注重要的特征再进行特征增强融合,最后经过全连接层进行高精度预测。
-
TCN是一种卷积神经网络结构,用于捕捉时序数据中的时序关系。它由一系列的1D卷积层组成,每个卷积层都具有相同的卷积核大小和步长。
-
TCN中的残差连接(Residual Connections)和空洞卷积(Dilated Convolutions)用于增加网络的感受野,以便更好地捕捉时序数据中的长期依赖关系。
-
TCN可以同时处理多个时间步的输入,这使得模型能够在多个时间步上进行并行预测。
-
Transformer是一种基于自注意力机制的序列建模方法,通过注意力机制来建模序列中不同位置之间的依赖关系,能够捕捉序列中的全局上下文信息。
-
自注意力机制通过计算输入序列中不同位置的相关性来分配不同位置的权重。这使得模型能够根据序列中不同位置的重要性来进行建模和预测。
-
TCN-Transformer模型采用并行结构,能够同时预测多个时间步的目标。
-
并行预测可以加快模型的训练和推理速度,并且能够充分利用时序数据中的信息,提高预测性能。
(4) 交叉注意力融合:
使用交叉注意力机制融空间和时序特征,可以通过计算注意力权重,学习时空特征中不同位置之间的相关性,可以更好地捕捉时空序列数据中的特征,提高模型性能和泛化能力。
-
(1) 时空卷积网络(TCN):
-
(2) Transformer模型:
-
(3) 并行预测:
2 多特征变量数据集制作与预处理
2.1 导入数据
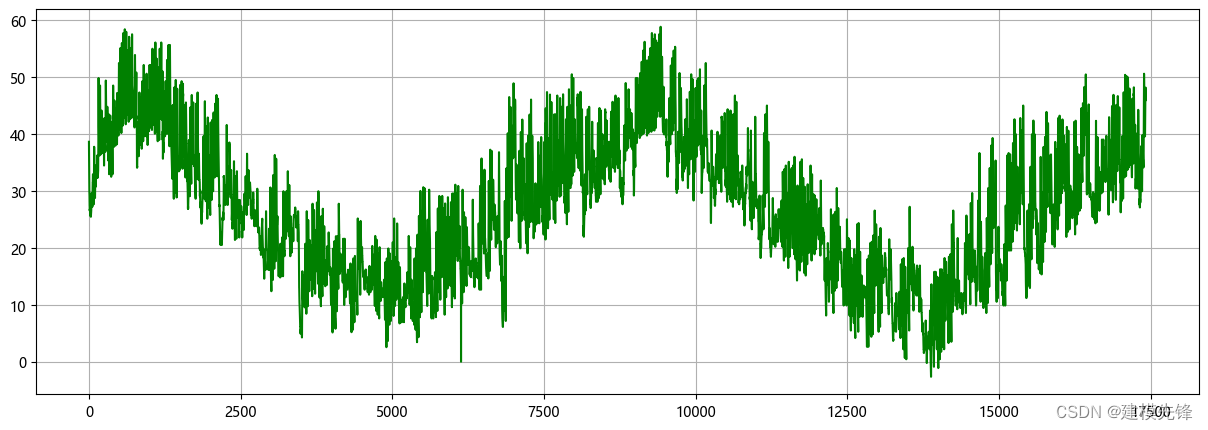
2.2 制作数据集
制作数据集与分类标签

3 交叉注意力机制

3.1 Cross attention概念
-
Transformer架构中混合两种不同嵌入序列的注意机制
-
两个序列必须具有相同的维度
-
两个序列可以是不同的模式形态(如:文本、声音、图像)
-
一个序列作为输入的Q,定义了输出的序列长度,另一个序列提供输入的K&V
3.2 Cross-attention算法
-
拥有两个序列S1、S2
-
计算S1的K、V
-
计算S2的Q
-
根据K和Q计算注意力矩阵
-
将V应用于注意力矩阵
-
输出的序列长度与S2一致
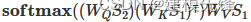
在融合过程中,我们将经过Transformer的时序特征作为查询序列,TCN提取的全局空间特征作为键值对序列。通过计算查询序列与键值对序列之间的注意力权重,我们可以对不同特征之间的关联程度进行建模。
4 基于TCN-Transformer-CrossAttention的高精度预测模型
4.1 定义网络模型
4.2 设置参数,训练模型

50个epoch,训练误差极小,多变量特征TCN-Transformer-CrossAttention融合网络模型预测效果显著,模型能够充分提取时间序列的空间特征和时序特征,收敛速度快,性能优越,预测精度高,交叉注意力机制能够对不同特征之间的关联程度进行建模,从序列时空特征中于提取出对模型预测重要的特征,效果明显!
4.3 模型评估和可视化
预测结果可视化
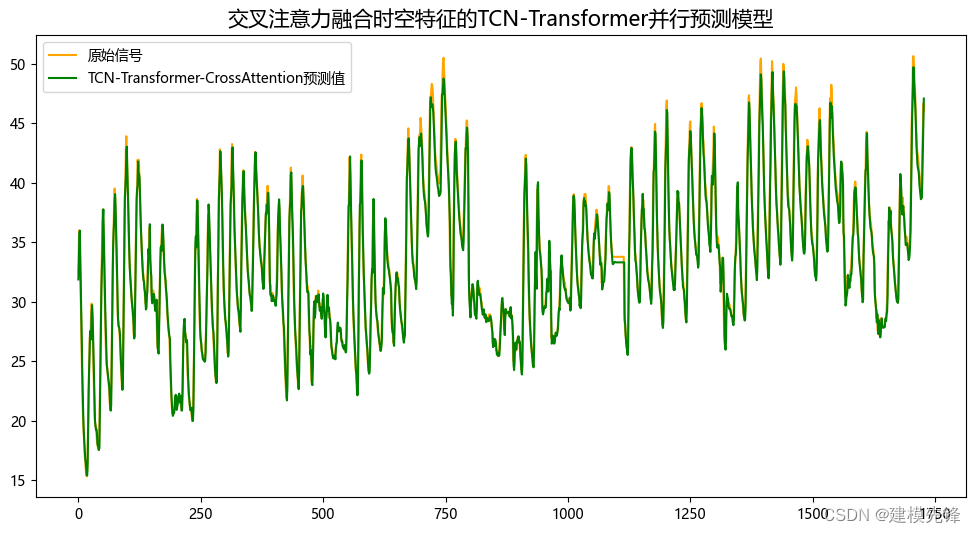
模型评估

代码、数据如下:
对数据集和代码感兴趣的,可以关注最后一行
- # 加载数据
- import torch
- from joblib import dump, load
- import torch.utils.data as Data
- import numpy as np
- import pandas as pd
- import torch
- import torch.nn as nn
- # 参数与配置
- torch.manual_seed(100) # 设置随机种子,以使实验结果具有可重复性
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
- #代码和数据集:https://mbd.pub/o/bread/mbd-ZZyZk5xv