
- 1如何学习FPGA——FPGA的学习规划_3个月fpga学习计划
- 2L1-8 估值一亿的AI核心代码 (20分)_本题要求你实现一个稍微更值钱一点的 ai 英文问答程序,规则是: 无论用户说什么,首
- 3git stash 用法总结_git stashes
- 4Todesk远程控制用于渗透初研究_todesk 渗透
- 5Homestead切换PHP版本_php 无法将“update-alternatives”项识
- 6nginx-http-flv配置
- 7Python量化金融都需要用到哪些库?最全汇总_python 库 金融
- 8项目7-音乐播放器4+喜欢/收藏音乐
- 9华为OD机试 -解数独(java& c++& python & javascript & golang & c# & c)_华为面试编程题 数独 python
- 10NOI金牌冲刺day1_cf1418g哈希
数字人解决方案——ER-NeRF实时对话数字人模型推理部署带UI交互界面
赞
踩
简介
这个是一个使用ER-NeRF来实现实时对话数字人、口播数字人的整体架构,其中包括了大语言回答模型、语音合成、成生视频流、背景替换等功能,项目对显存的要求很高,想要达到实时推理的效果,建议显存在24G以上。
实时对话数字人
讨论群企鹅:787501969
一、环境安装
#下载源码
git clone https://github.com/Fictionarry/ER-NeRF.git
cd ER-NeRF
#创建虚拟环境
conda create --name vrh python=3.10
activate vrh
#pytorch 要单独对应cuda进行安装,要不然训练时使用不了GPU
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
conda install -c fvcore -c iopath -c conda-forge fvcore iopath
#安装所需要的依赖
pip install -r requirements.txt
#处理音频时用的
pip install tensorflow
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
下载pytorch3d源码,如果下载不了,按上面的百度网盘下载:链接:https://pan.baidu.com/s/1xPFo-MQPWzkDMpLHhaloCQ
提取码:1422
git clone https://github.com/facebookresearch/pytorch3d.git
cd pytorch3d
python setup.py install
- 1
- 2
- 3
二、对话模型ChatGLM3
1. ChatGLM3简介
ChatGLM3作为一个支持中英双语的开源对话语言模型,由智谱 AI 和清华大学 KEG 实验室合作发布,基于 General Language Model (GLM) 架构,拥有 62 亿参数。ChatGLM3-6B 在保留了前两代模型对话流畅、部署门槛低等优点的基础上,还增加了更多特性。虽然目前ChatGLM 比 GPT 稍有逊色,但ChatGLM 在部署后可以完全本地运行,用户可以完全掌控模型的使用。这为用户提供了更多的灵活性和自主权。
ChatGLM3-6B 是一个更强大的基础模型,它的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。ChatGLM3-6B 还有更完整的功能支持。它采用了全新设计的 Prompt 格式,不仅支持正常的多轮对话,还原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。除了对话模型 ChatGLM3-6B,还有基础模型 ChatGLM3-6B-Base 和长文本对话模型 ChatGLM3-6B-32K 开源。所有这些权重都对学术研究完全开放,在填写问卷进行登记后也允许免费商业使用。
在这里插入代码片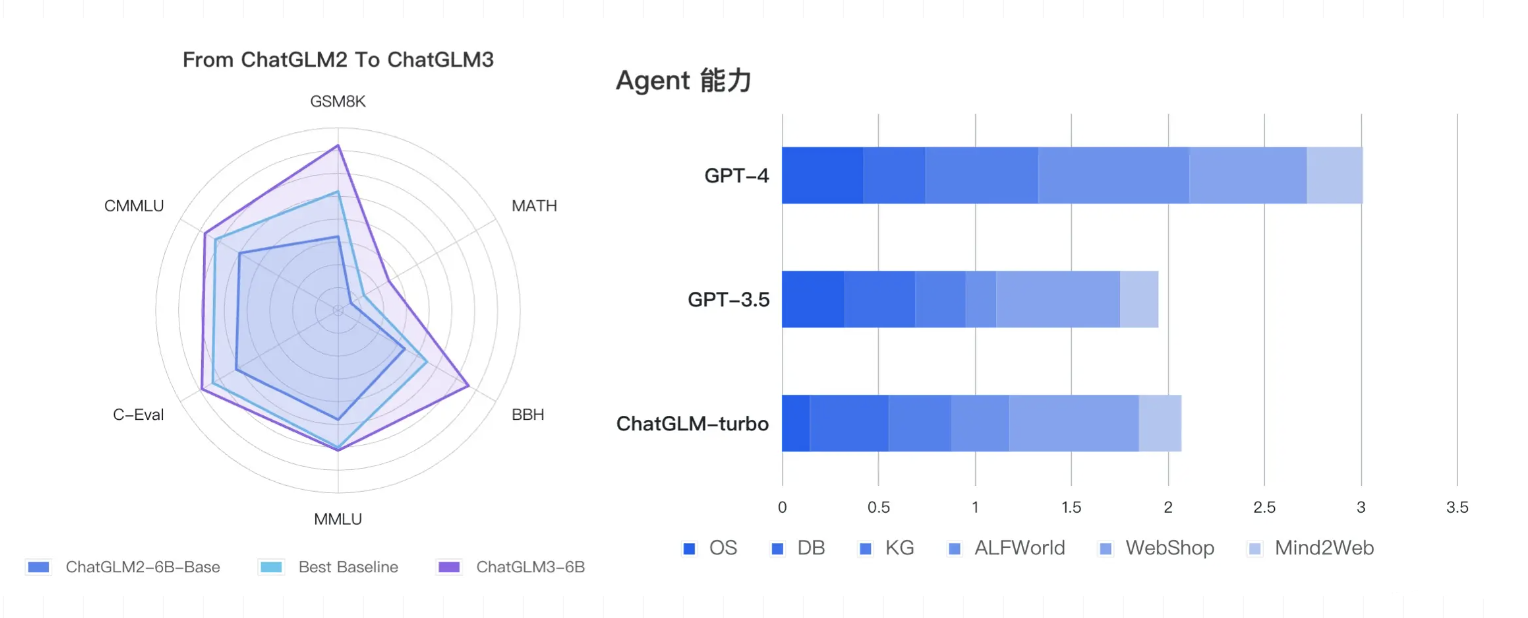
2.模型与下载
ChatGLM3-6B 开源ChatGLM3-6B、ChatGLM3-6B-Base、ChatGLM3-6B-32K三种模型:
| Model | Seq Length | Download |
|---|---|---|
| ChatGLM3-6B | 8k | HuggingFace — ModelScope |
| ChatGLM3-6B-Base | 8k | HuggingFace — ModelScope |
| ChatGLM3-6B-32K | 32k | HuggingFace — ModelScope |
| 量化等级 | 生成 8k 长度的最小显存 |
|---|---|
| FP16 | 15.9 GB |
| INT8 | 11.1 GB |
| INT4 | 8.5 GB |
3.项目部署
- 本项目需要 Python 3.10 或更高版本:
conda create -n ChatGLM3 python=3.10
conda activate ChatGLM3
- 1
- 2
- 下载源码与模型
git clone https://github.com/THUDM/ChatGLM3.git
git lfs clone https://huggingface.co/THUDM/chatglm3-6b
- 1
- 2
- 安装依赖:
cd ChatGLM3
pip install -r requirements.txt
- 1
- 2
- 多显卡需要安装accelerate
pip install accelerate
- 1
4.测试项目
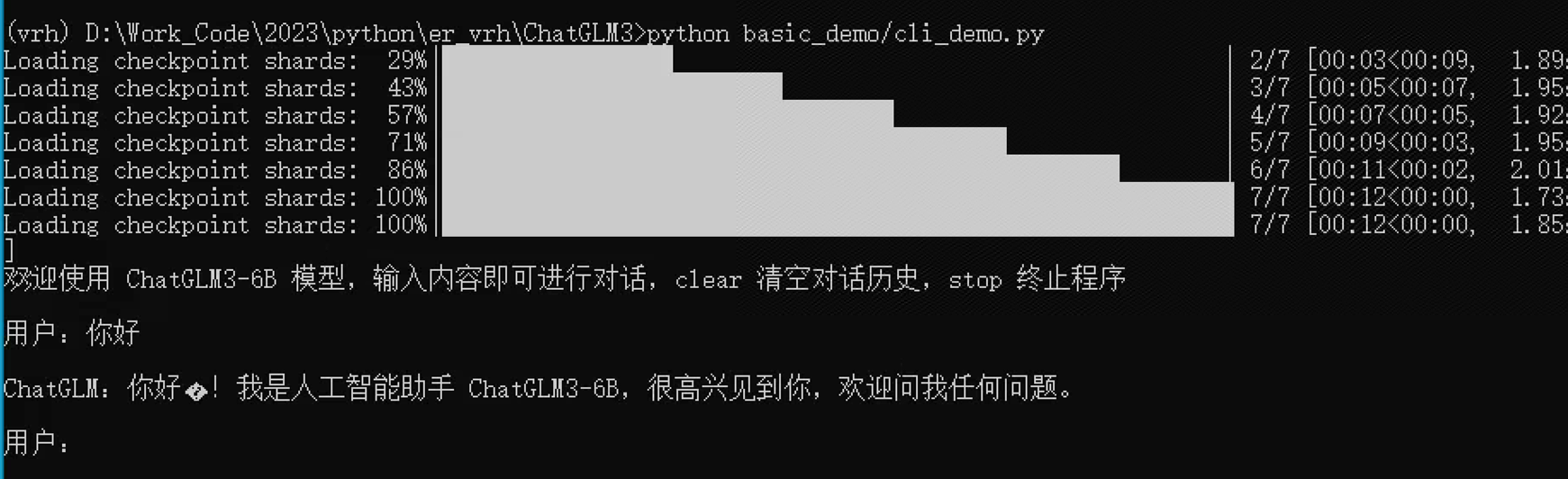
打开basic_demo/cli_demo.py,把模型路径更改成刚刚下载的模型路径,要不然在运行的过程中,代码会自动去下载模型,有可能会下载失败:
MODEL_PATH = os.environ.get('MODEL_PATH', './chatglm3-6b')
- 1
三、语音合成Edge-tts
1.edge-tts安装
Edge-TTS 是一个使用微软的 Azure Cognitive Services 实现文本到语音转换(TTS)的 Python 库。它提供了一个简单的 API,允许将文本转换为语音,并支持多种语言和声音。
要使用 Edge-TTS 库,可以通过以下步骤进行安装:
pip install edge-tts
- 1
安装完成后,可以在 Python 中使用这个库,调用相应的 API 来进行文本到语音的转换。这通常包括向 Azure Cognitive Services 发送请求,并处理返回的语音数据。
2.edge-tts测试
async def main(voicename: str, text: str, OUTPUT_FILE):
communicate = edge_tts.Communicate(text, voicename)
with open(OUTPUT_FILE, "wb") as file:
async for chunk in communicate.stream():
if chunk["type"] == "audio":
file.write(chunk["data"])
elif chunk["type"] == "WordBoundary":
pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
四、语音特征提取DeepSpeech
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。这里使用DeepSpeech来对生成的语音进行特征提取,提取出来的语音特征保存为npy文件用于合成视频:
def main():
"""
Main body of script.
"""
args = parse_args()
in_audio = os.path.expanduser(args.input)
if not os.path.exists(in_audio):
raise Exception("Input file/directory doesn't exist: {}".format(in_audio))
deepspeech_pb_path = args.deepspeech
#add
deepspeech_pb_path = True
args.deepspeech = '~/.tensorflow/models/deepspeech-0_1_0-b90017e8.pb'
#deepspeech_pb_path="/disk4/keyu/DeepSpeech/deepspeech-0.9.2-models.pbmm"
if deepspeech_pb_path is None:
deepspeech_pb_path = ""
if deepspeech_pb_path:
deepspeech_pb_path = os.path.expanduser(args.deepspeech)
if not os.path.exists(deepspeech_pb_path):
deepspeech_pb_path = get_deepspeech_model_file()
if os.path.isfile(in_audio):
extract_features(
in_audios=[in_audio],
out_files=[args.output],
deepspeech_pb_path=deepspeech_pb_path,
metainfo_file_path=args.metainfo)
else:
audio_file_paths = []
for file_name in os.listdir(in_audio):
if not os.path.isfile(os.path.join(in_audio, file_name)):
continue
_, file_ext = os.path.splitext(file_name)
if file_ext.lower() == ".wav":
audio_file_path = os.path.join(in_audio, file_name)
audio_file_paths.append(audio_file_path)
audio_file_paths = sorted(audio_file_paths)
out_file_paths = [""] * len(audio_file_paths)
extract_features(
in_audios=audio_file_paths,
out_files=out_file_paths,
deepspeech_pb_path=deepspeech_pb_path,
metainfo_file_path=args.metainfo)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
五、视频合成ER-NeRF
1.语言模型
- 简单回答
为了测试方便,这里写了个简单的回复函数,如果机器没有大显存的话,可以使用这个函数来测试数字人是否能运行起来。
def test_answer(message):
message = message.lower()
if message == "你好":
response = "你好,有什么可以帮到你吗?"
elif message == "你是谁":
response = f"我是虚拟数字人静静,这是我的一个测试版本。"
elif message == "你能做什么":
response = "我可以陪你聊天,回答你的问题,我还可以做很多很多事情!"
else:
response = "你的这个问题超出了我的理解范围,等我学习后再来回答你。或者你可以问我其他问题,能回答的我尽量回答你!"
return response
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- GLM回答
使用GLM语言模型来回答,可以直接把代码整合在一个推理代码里面,这样很吃GPU,如果没有12G以上的显存,建议把GLM做成服务器形势进行访问:
tokenizer = AutoTokenizer.from_pretrained("ChatGLM3/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("ChatGLM3/chatglm3-6b", trust_remote_code=True, device='cuda')
video_pre_process()
def glm_answer(query):
global model
model = model.eval()
query = query +"(请在20个字内回答)"
response, history = model.chat(tokenizer, query, history=[])
return response
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.语音合成与语音特征提取
选择生成语音发声人:
audio_eo_path,audio_path_wav = text_to_audio(response,dir,voicename)
output_video_path = compound_video(audio_path_wav, audio_eo_path, cv_bg, dir, 0)
return history, history, output_video_path
def text_to_audio(text,save_path,voicename):
global voices_list;
asyncio.set_event_loop(asyncio.new_event_loop())
name = ''
if voicename == "晓晓":
name = 'zh-CN-XiaoxiaoNeural'
if voicename == "晓依":
name = 'zh-CN-XiaoyiNeural'
if voicename == "云霞":
name = 'zh-CN-YunxiaNeural'
if voicename == "东北":
name = 'zh-CN-liaoning-XiaobeiNeural'
if voicename == "陕西":
name = 'zh-CN-shaanxi-XiaoniNeural'
if voicename == "云剑":
name = 'zh-CN-YunjianNeural'
if voicename == "云溪":
name = 'zh-CN-YunxiNeural'
if voicename == "云阳":
name = 'zh-CN-YunyangNeural'
timestamp = int(time.time())
audio_path_mp3 = os.path.join(save_path, str(timestamp) + ".mp3")
audio_path_wav = os.path.join(save_path, str(timestamp) + ".wav")
asyncio.get_event_loop().run_until_complete(main(name, text,audio_path_mp3))
command = ['ffmpeg', '-i', audio_path_mp3, audio_path_wav]
subprocess.run(command, capture_output=True, text=True)
cmd = f'python data_utils/deepspeech_features/extract_ds_features.py --input {audio_path_wav}'
os.system(cmd)
audio_eo_path = os.path.join(save_path, str(timestamp) + ".npy")
return audio_eo_path,audio_path_wav
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
3.合成视频
合成的视频可以选择使用的背景,还有人像所在的位置,分三个位置,左,中,右,也可以在执行中动态更改位置。
def answer(message, history,voicename,llm_name):
global dir
global cv_bg
history = history or []
response = ''
if llm_name =="测试":
response = test_answer(message)
elif llm_name =="ChatGLM3":
response = glm_answer(message)
history.append((message, response))
audio_eo_path,audio_path_wav = text_to_audio(response,dir,voicename)
output_video_path = compound_video(audio_path_wav, audio_eo_path, cv_bg, dir, 0)
return history, history, output_video_path
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.webui代码整合
这里使用gradio来做交互的UI。
import gradio as gr
import time
import cv2
import os
from tools import video_pre_process, compound_video
from transformers import AutoTokenizer, AutoModel
import asyncio
import edge_tts
import subprocess
dir = "workspace"
cv_bg = cv2.imread('bg_1.jpg')
tokenizer = AutoTokenizer.from_pretrained("ChatGLM3/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("ChatGLM3/chatglm3-6b", trust_remote_code=True, device='cuda')
video_pre_process()
def glm_answer(query):
global model
model = model.eval()
query = query +"(在20个字内回答)"
response, history = model.chat(tokenizer, query, history=[])
return response
async def main(voicename: str, text: str, OUTPUT_FILE):
communicate = edge_tts.Communicate(text, voicename)
with open(OUTPUT_FILE, "wb") as file:
async for chunk in communicate.stream():
if chunk["type"] == "audio":
file.write(chunk["data"])
elif chunk["type"] == "WordBoundary":
pass
def test_answer(message):
message = message.lower()
if message == "你好":
response = "你好,有什么可以帮到你吗?"
elif message == "你是谁":
response = f"我是虚拟数字人静静,这是我的一个测试版本。"
elif message == "你能做什么":
response = "我可以陪你聊天,回答你的问题,我还可以做很多很多事情!"
else:
response = "你的这个问题超出了我的理解范围,等我学习后再来回答你。或者你可以问我其他问题,能回答的我尽量回答你!"
return response
def answer(message, history,voicename,llm_name):
global dir
global cv_bg
history = history or []
response = ''
if llm_name =="测试":
response = test_answer(message)
elif llm_name =="ChatGLM3":
response = glm_answer(message)
history.append((message, response))
audio_eo_path,audio_path_wav = text_to_audio(response,dir,voicename)
output_video_path = compound_video(audio_path_wav, audio_eo_path, cv_bg, dir, 0)
return history, history, output_video_path
def text_to_audio(text,save_path,voicename):
global voices_list;
asyncio.set_event_loop(asyncio.new_event_loop())
name = ''
if voicename == "晓晓":
name = 'zh-CN-XiaoxiaoNeural'
if voicename == "晓依":
name = 'zh-CN-XiaoyiNeural'
if voicename == "云霞":
name = 'zh-CN-YunxiaNeural'
if voicename == "东北":
name = 'zh-CN-liaoning-XiaobeiNeural'
if voicename == "陕西":
name = 'zh-CN-shaanxi-XiaoniNeural'
if voicename == "云剑":
name = 'zh-CN-YunjianNeural'
if voicename == "云溪":
name = 'zh-CN-YunxiNeural'
if voicename == "云阳":
name = 'zh-CN-YunyangNeural'
timestamp = int(time.time())
audio_path_mp3 = os.path.join(save_path, str(timestamp) + ".mp3")
audio_path_wav = os.path.join(save_path, str(timestamp) + ".wav")
asyncio.get_event_loop().run_until_complete(main(name, text,audio_path_mp3))
command = ['ffmpeg', '-i', audio_path_mp3, audio_path_wav]
subprocess.run(command, capture_output=True, text=True)
cmd = f'python data_utils/deepspeech_features/extract_ds_features.py --input {audio_path_wav}'
os.system(cmd)
audio_eo_path = os.path.join(save_path, str(timestamp) + ".npy")
return audio_eo_path,audio_path_wav
with gr.Blocks(css="#chatbot{height:300px} .overflow-y-auto{height:500px}") as rxbot:
tts_checkbox = gr.Dropdown(["晓晓", "晓依", "云霞", "东北", "陕西", "云剑", "云溪", "云阳"],
label="语音选择", info="晓晓:女, 晓依:女, 云霞:女, 东北:女, 陕西:女, 云剑:男, 云溪:男,云阳:男")
answer_checkbox = gr.Dropdown(["测试","ChatGLM3", "ChatGPT", "LLaMA"],
label="大语言模型",
info="测试:只有固定的几个问题, ChatGLM3:GPU在12G以上可以选择这个模型, ChatGPT:暂时没有接入, LLaMA:暂时没有接入")
with gr.Row():
video_src = gr.Video(label="数字人", autoplay=True)
with gr.Column():
state = gr.State([])
chatbot = gr.Chatbot(label="消息记录").style(color_map=("green", "pink"))
txt = gr.Textbox(show_label=False, placeholder="请输入你的问题").style(container=False)
txt.submit(fn=answer, inputs=[txt, state,tts_checkbox,answer_checkbox], outputs=[chatbot, state, video_src])
# rxbot.launch()
if __name__ == "__main__":
# response = glm_answer('你好')
# print(response)
rxbot.launch()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134

