
- 1使用nat123实现Django微服务器的内网穿透_django实现微服务
- 2如何利用AI学习区块链知识,ChatGPT x Kapa.ai ⇒ 开发者的福音_kapa ai
- 3利用arduino给ESP8266 01S烧录程序----记录_esp8266 01s arduino
- 4SpringBoot集成系列--Kafka_springboot could not be established. broker may no
- 5重置 Mac 上的系统管理控制器 (SMC)_重置 mac 的 smc。
- 6二叉查找树的java代码实现_二叉查找代码java
- 7SSH简介及两种远程登录的方法_ssh登录
- 82023-HCIA-Datacom保姆级学习笔记(十一):ACL原理与配置_在设备上多放一个acl,里面配置是空的,会有问题吗
- 9Ubuntu16解决无法解析域名问题_ubuntu 16更新源更新时无法解析域名
- 10C语言课后作业 20 题+考研上机应用题_c语言应用题
彝文计算机,计算机彝文信息处理主流技术的分析与探讨
赞
踩
摘要:本文以彝文信息处理的特点作为出发点,从N元模型、语音识别和语法分析等方面分析了彝文信息处理的主流技术。
关键词:彝文;信息处理;N元模型;语音识别;语法分析
一、引言
当今世界已经进入信息网络时代,全信息化是社会发展和科技进步的主流。语言文字信息处理是专业范围应用最广泛、用户人群最众多、数据量最大的一个领域,计算机在多民族国家的应用,都面临扩充当地民族语言文字信息处理能力的强烈要求。众所周知,全人类用于交流信息、传播知识、发展文化的各种自然语言,虽然在表现形式上不同,但在语义有着深层次的相似性,因此计算机彝文信息处理同其他文字的信息处理有更多的共性,当然计算机彝文信息处理也有自己的特性与主流信息处理技术。
二、计算机彝文信息处理的特点
计算机彝文信息处理是指用计算机对彝文的音、形、义等信息进行处理,即对字、词、句、篇章的输入、输出、识别、分析、理解、生成等的操作与加工,研究如何运用计算机和计算机技术研究彝语言、处理彝语言知识的学问,它是一个涉及到计算机科学、语言学、文字学、数学、逻辑、认知科学等多个学科的交叉研究领域。
1、彝文字的特殊性
众所周知,英文、法文等西方文字属于拉丁文字,由于构成的字母数量有限、字形简单,可以很容易在计算机上实现文字的输入、输出以及信息的加工和处理,因此在计算机语言信息处理方面具有明显的优势。彝文跟汉文一样属于表意文字,而且彝文分为六大方言区,由于内部差异较大,使彝文在读音、写法、表义上产生了分歧,同样一个字形,不同的地方有不同的音、不同的写法及不同的意义。仅2010年11月全国彝语术语标准化工作委员会提出的全国通用彝文方案就有5598个彝文字,属于大字符集,这就给彝字的编码带来了很多困难。因此我们借鉴西文信息处理和汉字信息处理的开发经验,结合彝文的特点,在计算机彝文信息处理过程中的根据不同要求对彝文字进行了不同形式的编码,如:彝文标准编码(国内、国际)、输入编码(全拼、简拼、笔画),以及彝文内码等不同方案。
2、书面彝文的特殊性
彝文的另一个特征是在书面表达中,词语和记号之间没有明显的分隔标记,这就使自动分词在书面彝文分析中成立一个难题。分词需要将连续的字按照一定的规范进行有序的组合,例如英文单词之间都是用空格来做分隔符,而彝文则是习惯通过字、整句以及段落进行简单的划分,而这其中的一个难点就是对词语的划分,虽然英语中也有短语划分的问题,但是由于彝文文的词语远比英语的数量和范围要庞大,因而处理起来更为困难。计算机彝文信息处理应用系统只要涉及检索、机器翻译、文摘、校对等,就需要以词为基本单位。随着对语言文字信息处理研究工作的不断深入,彝文信息处理技术也从字信息处理逐步转向语言信息处理,彝文自动分词是计算机彝文信息处理中一项不可缺少的基础性工作
3、彝语语音的特殊性
在语音方面,有塞音、塞擦音、擦音都分清浊两类。多数方言的元音全部或大部分松紧对立。多数方言的韵母由单元音构成,没有塞音韵尾。少数方言有复元音和带鼻音韵尾(或带半鼻音)的元音,大都出现频率小,或只用于拼写汉语新借词。各方言元音音位的对立关系,各具特色。一般有3~4个声调,调型简单,多为平调和降调,没有曲折调。音节结构的主要形式是:辅音+元音+声调,元音+声调,音节结构相对简单,音节划分界限比较清晰,但是声调和变调是彝语的一个显著区别,因而在语音识别和语音合成方面来讲这是一个难点,但由于彝文的字符相对来说少一些,因此是总体上来说彝语语音的处理比之其他方面来说还是相对容易的。
4、彝语语法的特殊性
在语法方面,以虚词和词序为主要语法手段。语序是:主语—宾语—谓语。名词和一部分代词作定语时,在中心词前。数量词和形容词作定语时,在中心词后。多数方言的否定词作状语修饰动词、形容词时,在单音的中心词前、 双音的中心词之间,还使用某些屈折变化作为表示语法意义的辅助手段,因此如果不能很好的掌握句法,就特别容易产生歧义,因此彝语语句自动分析这一重要技术是一项急需的技术。
三、计算机彝文信息处理的若干技术分析
1、N元模型
设wi是文本中的任意一个词,如果已知它在该文本中的前两个词 wi-2w-1,便可以用条件概率P(wi|wi-2w-1)来预测wi出现的概率。这就是统计语言模型的概念。一般来说,如果用变量W代表文本中一个任意的词序列,它由顺序排列的n个词组成,即W=w1w2...wn,则统计语言模型就是该词序列W在文本中出现的概率P(W)。利用概率的乘积公式,P(W)可展开为:P(W) = P(w1)P(w2|w1)P(w3| w1 w2)...P(wn|w1 w2...wn-1),不难看出,为了预测词wn的出现概率,必须知道它前面所有词的出现概率。从计算上来看,这种方法太复杂了。如果任意一个词wi的出现概率只同它前面的两个词有关,问题就可以得到极大的简化。 这时的语言模型叫做三元模型 (tri-gram):P(W)≈P(w1)P(w2|w1)∏i(i=3,...,nP(wi|wi-2w-1),符号∏i i=3,...,n P(...) 表示概率的连乘。一般来说,N元模型就是假设当前词的出现概率只同它前面的N-1个词有关。重要的是这些概率参数都是可以通过大规模语料库来计算的。比如三元概率有P(wi|wi-2wi-1) ≈ count(wi-2wi-1wi) /count(wi-2wi-1)式中count(...) 表示一个特定词序列在整个语料库中出现的累计次数。这为彝语语料库的建设、智能检索、机器翻译等方面提供了计算语言模式,例如,西南西南民族大学民族语言文字信息处理研发中心完成的彝语语料库、彝文自动分词与标注系统等都运用了此计算模式来开展的。
2、语音识别
语音识别的最终目标是使人类与计算机之间实现真正意义上的自由交流,使机器听懂人类的语言,并及时的做出准确的反馈。语音识别是一门交叉学科,语音识别技术包括了信号处理、模式识别、概率论和信息论、发声机原理和听觉原理、人工智能等主要内容。彝语语音识别技术主要包括特征提取技术、模式匹配准则和模型训练技术三个方面,另外还涉及到语音识别单元的选取,在这个问题上我们通常采用的是以彝语音节为识别单元。另外,在特征参数的提取技术方面,由于语音符号中含有大量的信息,它们通常被称为声学特征。声学特征参数是决定语音识别质量的关键技术,因此我们应该极可能的采集所要传播语言的语义信息,剔除掉说话人的个人信息干扰,这样才能保证特征参数的有效性和准确性,例如,西南民族大学民族语言文字信息处理研发中心2019年就完成了规范彝语声学参数库的研究与建设,为深入开展彝语语音识别技术工作研究奠定了一个坚实的基础。
3、句法分析
句法分析就是指对句子中的词语语法功能进行分析,比如彝语“
 (我去北京”,这里“
(我去北京”,这里“
 (我)”是主语,“
(我)”是主语,“
 (去)”是谓语,“
(去)”是谓语,“
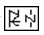 (北京)”是宾语。
(北京)”是宾语。
句法分析现在主要的应用在于计算机彝文信息处理中,如机器翻译等,是语块分析思想的一个直接实现,语块分析通过识别出高层次的结构单元来简化句子的描述。就是以彝语的语法特征为分析方法,对句子、段落中的短语结构树进行各个句子成分关系的分析,分析的主要内容包括:句子中所有的单句,每个单句在句法中的作用是什么,在单句以上更大的语法结构是什么,句子中的短语或词组类型是什么,在句子中起了什么作用,最后,所有这些成分是如何有机组合或附着在整个句子中的,这些就是句法结构分析的主要内容,西南民族大学在2011年开发的彝、汉、英平行语料库就开始了彝语句法分析的探索。需要说明是,汉语、英语语言结构中宾语必须置于谓语之前,而彝语的语序则是:主语—宾语—谓语,宾语前置,这一点是与汉语、英语等语言有着显著的区别的。
四、结语
开展计算机彝文信息处理技术研究有着重要的意义,它是彝语语言学与计算机信息技术的有机融合,是将彝语言的各个部分,包括词语、句子、段落以至篇章文本、声音和图像各种方式的信息化加工,然后对这些信息进行输入输出、压缩、存储以及检索等等各项处理。彝语言文字是彝文信息和知识的载体,彝语言文字的信息化或者说彝语言文字信息处理技术的发展水平是关乎彝族地区现代化、社会信息化的大事。计算机彝文信息处理技术开发与运用不仅标志着彝语文的社会功能在这一领域的不断扩展,而且为彝语言文字的繁荣和发展,对于促进彝文的现代化、信息化的建设,宏扬优秀的民族文化等都具有重要的科学意义和社会意义。特别是随着语言信息处理技术的不断发展,以及社会的日益信息化,更需要对彝语言进行深层次分析和挖掘,实现彝语言文字信息处理真正面向对象服务的目标。可以预见,在信息化、网络化的未来,只有不断扩展彝文信息处理研究领域与研究方向,才能不断满足彝语文现代化发展的需求,也才会更好地促进彝文信息处理技术的可持续性发展。
本文以计算机彝文信息处理的特点作为出发点,通过对计算机彝文信息处理主流技术的分析与探讨,希望能够对彝语文现代化和计算机彝语言文字信息处理这个交叉领域的初步探索能起到抛砖引玉的作用,一起来共同发展和完善这项技术。
参考文献:
[1] 沙马拉毅.计算机彝文信息处理[M].四川民族出版社,2000.
[2]冯志伟.汉字和汉语的计算机处理[J].当代语言学,2001,(1).
[3]陈小荷.中文信息处理概述[J].南京师范大学文学院学报,2002,(1).
[4]俞士汶. 语料库与综合型语言知识库的建设, 中文信息处理若干重要问题[M].科学出版社,2003.
[5]冯志伟.计算语言学基础[M].商务印务馆.
[6]王成平.彝语言信息处理的现况分析与发展前景探讨[J],《西南民族大学学报》(人文社科版),2011,(2).
----------
[1] 作者简介:王成平(1979.3-),男,彝族,博士,副教授,西南民族大学民族语言文字信息处理研发中心,本文是国家社科基金项目(06XYY021)、国家社科基金项目(07BYY060)、西南民族大学中央高校基本科研业务费专项资金项目(09SZYZJ04)的研究成果之一。

