
- 1稳定排序和不稳定排序_稳定排序和不稳定排序的区别
- 2VMware Harbor 使用过程中遇到的问题 1 -- 无法上传docker镜像
- 3Vision Mamba_vision mamba csdn
- 4基于物联网的教室人数检测系统-设计说明书
- 5智能小程序 Ray 开发——表单组件 Button 和 Checkbox 实操讲解
- 6头歌Java语言之数组_头哥java语言之数组小孩分糖答案
- 7ROS2极简总结-坐标变换-TF_ros2 tf 坐标变换
- 8分享在Linux下编译Android源代码并修改调试系统自带应用的方法_android 源码中修改generic.kl
- 9尚硅谷4.0数仓项目整体设计要点记录_尚硅谷数据仓库 表的设计
- 10SpringBoot +Vue3 简单的前后端交互_登录界面前后端交互
强化学习(SAC)_sac方法
赞
踩
SAC—— soft actor-critic
SAC算法是一种现代的深度强化学习算法,它结合了基于策略的和基于价值的方法。SAC的核心思想是最大化期望回报的同时保持策略的随机性,这有助于提高探索环境的效率,并且通常可以赵高更好的策略。
发展史:
TD3算法在DDPG算法的基础上引入了双critic网络和延迟更新,进一步提升了算法的性能;SAC算法在TD3算法的基础上进一步拓展,引入了熵优化和自适应温度参数等技术,以适应更复杂的任务。
SAC算法最早于2018年被提出,该算法结合了actor-critic方法和强化学习中的熵概念。
随机策略&确定性策略
随机策略stochastic policy:在给定状态时,不会总是产生相同的动作,相反它会根据某种概率分布选择动作,这意味着及时智能体处于相同的状态,也可能选择不同的动作。
确定性策略deterministic policy:在给定状态时,总是产生相同的动作,这意味着无论何时智能体处于特定状态,都会选择相同的动作。
基于最大熵的RL算法的优势:
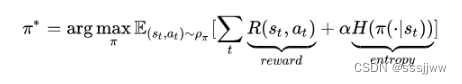
不仅想要长期的回报最大,还想要policy的每一次输出的action的熵最大,这样做是为了让策略随机化,也是在鼓励探索,为具有相似的Q值的动作分配近乎均等的概率,不会给动作范围内任何一个动作分配非常高的概率,避免了反复选择同一个动作而陷入次优。
伪代码:
初始化参数:(软状态值函数中)、
、
(软Q值函数中)、
(策略函数中)
for each iteration do
for each environment step do
end for
for each gradient step do
更新V:
更新软Q:
更新策略:
更新target V:
end for
end for
SAC网络架构
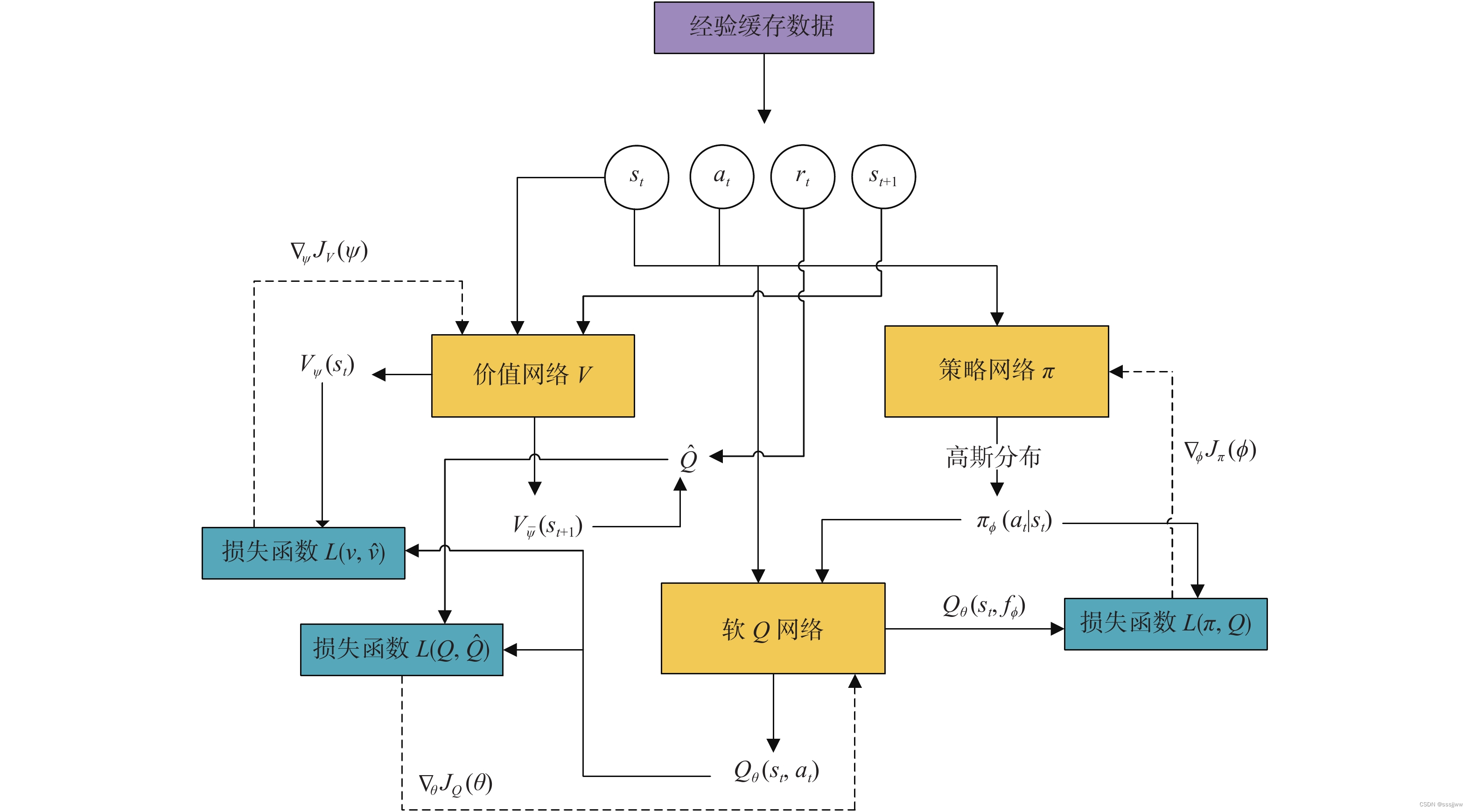
SAC算法中温度参数通常体现在actor网络的输出中,actor网络的输出是带噪声的策略,其中你早生的程度由温度参数控制。


