
AI大模型ChatGPT原理_chat gpt ai大模型
赞
踩
简介
openai 的 GPT 大模型的发展历程。
Bert
2018年,自然语言处理 NLP 领域也步入了 LLM 时代,谷歌出品的 Bert 模型横空出世,碾压了以往的所有模型,直接在各种NLP的建模任务中取得了最佳的成绩。
Bert 所作的事就是从大规模的上亿的文本预料中,随机地扣掉一部分字,形成完形填空题型,不断地学习空格处到底该填写什么。所谓语言模型,就是从大量的数据中学习复杂的上下文联系。
GPT 初代
与此同时,openai 早于 Bert 出品了一个初代 GPT 模型。
他们大致思想是一样的。都基于 Transformer 这种编码器,获取了文本内部的相互联系。
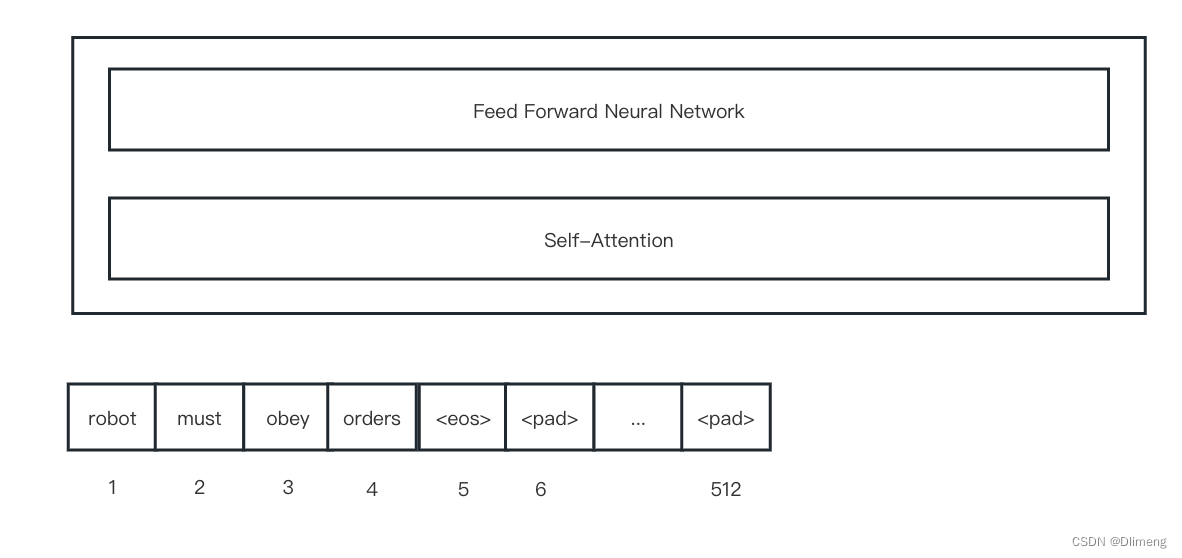
编解码的概念广泛应用于各个领域,在 NLP 领域,人们使用语言一般包括三个步骤:
接受听到或读到的语言 -> 大脑理解 -> 输出要说的语言。
语言是一个显式存在的东西,但大脑是如何将语言进行理解、转化和存储的,则是一个目前仍未探明的东西。因此,大脑理解语言这个过程,就是大脑将语言编码成一种可理解、可存储形式的过程,这个过程就叫做语言的编码。
相应的,把大脑中想要表达的内容,使用语言表达出来,就叫做语言的解码。
在语言模型中,编码器和解码器都是由一个个的 Transformer 组件拼接在一起形成的。
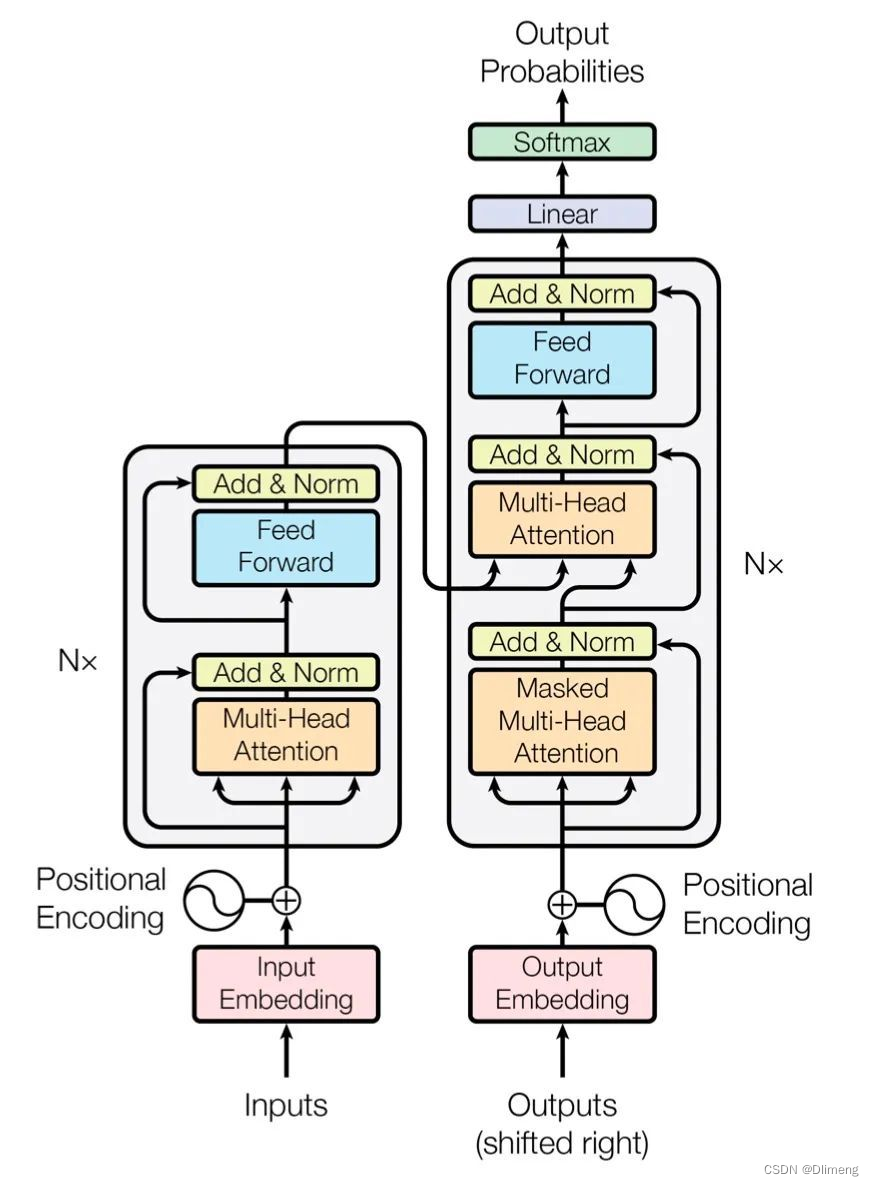
两者最主要的区别在于,Bert 仅仅使用了 encoder 也就是编码器部分进行模型训练,GPT 仅仅使用了 decoder 部分。两者各自走上了各自的道路,根据我粗浅的理解,GPT 的decoder 模型更加适应于文本生成领域。
我相信很多的 NLP 从业者对 LLM 的理解也大都停留在此。即,本质上讲,LLM 是一个非常复杂的编码器,将文本表示成一个向量表示,这个向量表示有助于解决 NLP 的任务。
GPT-2
我们一般的 NLP 任务,文本分类模型就只能分类,分词模型就只能分词,机器翻译也就只能完成翻译这一件事,非常不灵活。
GPT-2 主要就是在 GPT 的基础上,又添加了多个任务,扩增了数据集和模型参数,又训练了一番。
既然多个任务都在同一个模型上进行学习,还存在一个问题,这一个模型能承载的并不仅仅是任务本身,“汪小菲的妈是张兰”,这条文字包含的信息量是通用的,它既可以用于翻译,也可以用于分类,判断错误等等。也就是说,信息是脱离具体 NLP 任务存在的,举一反三,能够利用这条信息,在每一个 NLP 任务上都表现好,这个是 元学习(meta-learning),实际上就是语言模型的一脑多用。
GPT-3
大模型中的大模型
首先, GPT-3 的模型所采用的数据量之大,高达上万亿,模型参数量也十分巨大,学习之复杂,计算之繁复不说了。
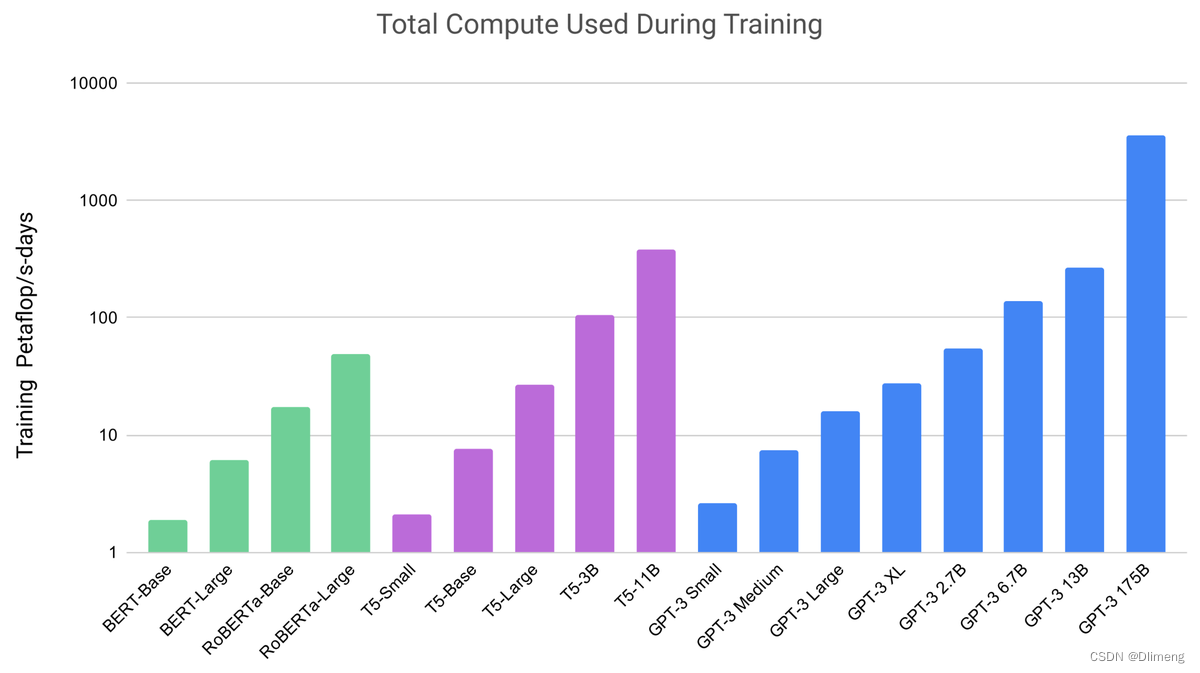
GPT-3 里的大模型计算量是 Bert-base 的上千倍。统统这些都是在燃烧的金钱,真就是 all you need is money。如此巨大的模型造就了 GPT-3 在许多十分困难的 NLP 任务,诸如撰写人类难以判别的文章,甚至编写SQL查询语句,React或者JavaScript代码上优异的表现。
首先 GPT-n 系列模型都是采用 decoder 进行训练的,也就是更加适合文本生成的形式。也就是,输入一句话,输出也是一句话。也就是对话模式。
对话
对话是涵盖一切NLP 任务的终极任务。从此 NLP不再需要模型建模这个过程。比如,传统 NLP 里还有序列标注这个任务,需要用到 CRF 这种解码过程。在对话的世界里,这些统统都是冗余的。
in-context learning
以往的预训练都是两段式的,即,首先用大规模的数据集对模型进行预训练,然后再利用下游任务的标注数据集进行 finetune,时至今日这也是绝大多数 NLP 模型任务的基本工作流程。
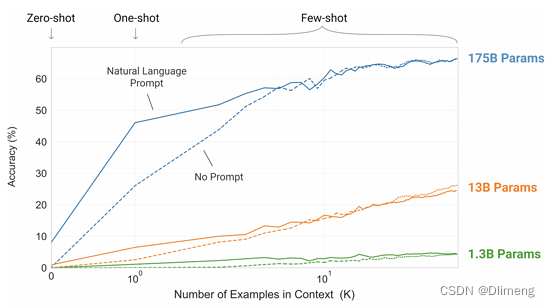
在 GPT-3 的预训练阶段,也是按照这样多个任务同时学习的。比如“做数学加法,改错,翻译”同时进行。这其实就类似前段时间比较火的 prompt。
这种引导学习的方式,在超大模型上展示了惊人的效果:只需要给出一个或者几个示范样例,模型就能照猫画虎地给出正确答案。注意啊,是超大模型才可以,一般几亿参数的大模型是不行的。(我们这里没有小模型,只有大模型、超大模型、巨大模型)
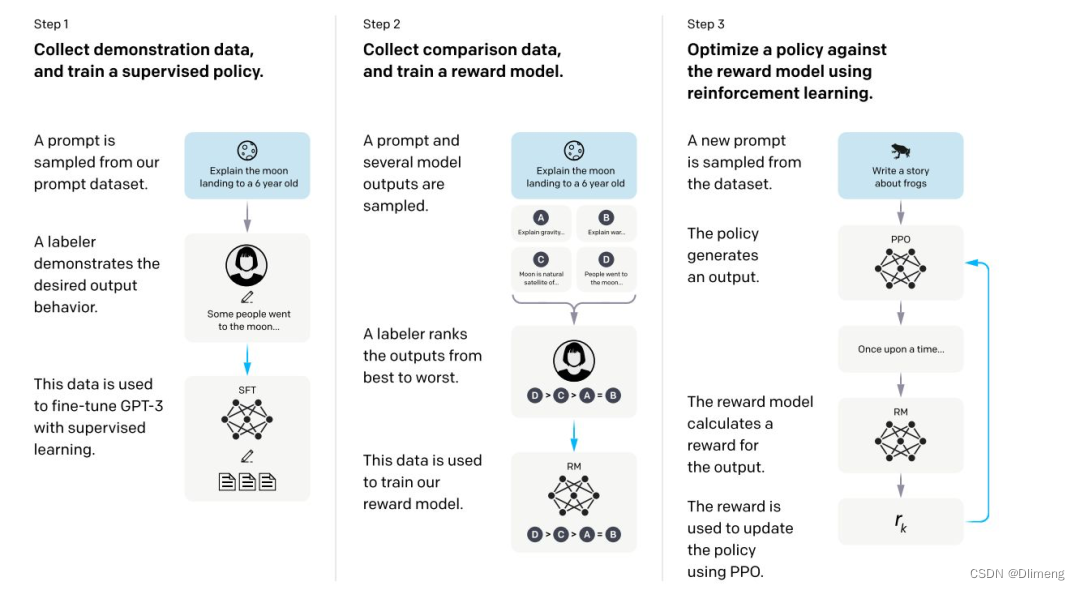
chatGPT
chatGPT 模型上基本上和之前都没有太大变化,主要变化的是训练策略变了。
强化学习
强化学习非常像生物进化,模型在给定的环境中,不断地根据环境的惩罚和奖励(reward),拟合到一个最适应环境的状态。
开源ChatGPT
https://github.com/hpcaitech/ColossalAI
https://github.com/lucidrains/PaLM-rlhf-pytorch

