
热门标签
热门文章
- 1中国政府针对财务体系赋能企业科技创新颁布了哪些政策
- 2【计算机领域 ei会议 |SPIE稳定出版检索-确定ISSN、ISBN号 | 往届均已见刊并完成EI、Scopus检索,会议历史良好!】第三届算法、微芯片与网络应用国际会议(AMNA 2024)_spie issn
- 3C++连接MySQL数据库_c++ mysql
- 4NLP基本业务范围_nlp业务
- 5Java实现KMP算法_kmp java算法
- 694页论文综述卷积神经网络:从基础技术到研究前景
- 7DOMAIN-A W ARE NEURAL LANGUAGE MODELS FOR SPEECH RECOGNITION_second-pass rescoring
- 8基于PHP后台微信理发店预约小程序系统设计与实现
- 9Flink集群部署_flink1.12集群搭建
- 10去中心化AI资源平台 AI Infinet - 速览
当前位置: article > 正文
python 主语_python从零开始构建知识图谱
作者:不正经 | 2024-06-09 13:02:41
赞
踩
使用python代码实现从语句提取知识图谱的数据

概览
- 知识图谱是数据科学中最迷人的概念之一
- 学习如何构建知识图谱来从维基百科页面挖掘信息
- 您将在Python中动手使用流行的spaCy库构建知识图谱
一、知识图谱
1、什么是知识图谱
We can define a graph as a set of nodes and edges.
知识图谱就是一组节点和边构成的三元组。
这里的节点A和节点B是两个不同的实体。这些节点由代表两个节点之间关系的边连接,也被称为一个三元组。
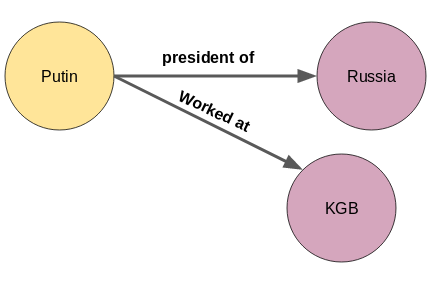
例如头实体“普京”和尾实体“俄罗斯”的关系是“是总统”:

还可以增加“普京在克格勃工作过”的三元组:
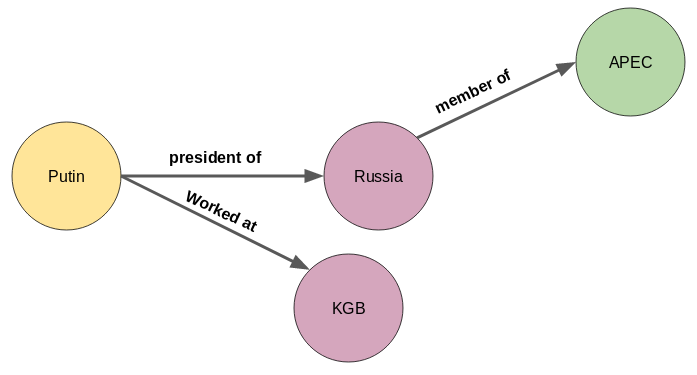
还可以增加“俄罗斯是APEC组织成员”的三元组:
识别实体和它们之间的关系对我们来说不是一项困难的任务,有监督的命名实体识别(NER)和关系抽取都有比较成熟的模型。但是标注一个大规模的实体和关系的数据集是需要巨大投入的。
因此作为初学者,我们使用句子分割、依赖解析、词性标注和实体识别等NLP技术来实现实体识别、关系抽取、知识图谱构建。
2、句子分割Sentence Segmentation
构建知识图的第一步是将文本文档或文章分解成句子。然后,我们将选出只有一个主语和一个宾语的句子。让我们看看下面的示例文本:
“Indian tennis player Sumit Nagal moved up six places from 135 to a career-best 129 in the latest men’s singles ranking. The 22-year-old recently won the ATP Challenger tournament. He made his Grand Slam debut against Federer in the 2019 US Open. Nagal won the first set.”
在最新的男子单打排名中,印度网球选手纳加尔(Sumit Nagal)上升了6位,从135名上升到职业生涯最好的129名。这位22岁的选手最近赢得了ATP挑战赛的冠军。在2019年的美国网球公开赛上,他迎来了自己的大满贯处子秀,对手是费德勒。纳加尔赢了第一盘。
将文本分割成句子:
- Indian tennis player Sumit Nagal moved up six places from 135 to a career-best 129 in the latest men’s singles ranking
- The 22-year-old recently won the ATP Challenger tournament
- He made his Grand Slam debut against Federer in the 2019 US Open
- Nagal won the first set
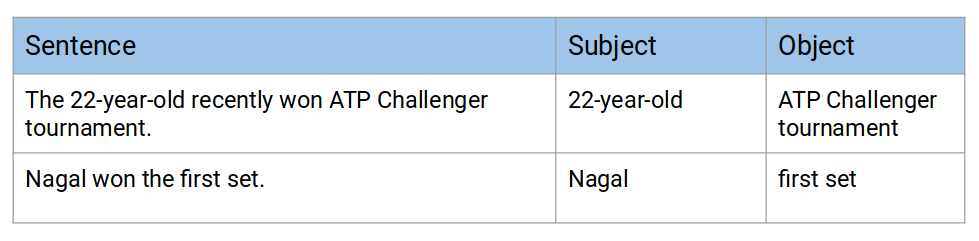
在这四个句子中,我们将选出第二个和第四个句子,因为它们分别包含一个主语和一个宾语。在第二句话中,22-year-old是主语,宾语是ATP挑战者锦标赛。在第四句中,主语是Nagal,first set是宾语:
|
但是我们没办法每个句子都人工抽取,因此需要使用实体识别和关系抽取技术。
3、实体识别Entities Recognition
首先我们需要抽取实体,也就是知识图谱上的“节点”:
从一个句子中提取一个单词并不是一项艰巨的任务。借助词性标签,我们可以很容易地做到这一点。名词和专有名词就是我们的实体。但是,当一个实体跨越多个单词时,仅使用POS标记是不够的。我们需要解析句子的依赖树。在下一篇文章中,您可以阅读更多有关依赖解析dependency
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/694221
推荐阅读
相关标签

