
热门标签
热门文章
- 1第一 二章 小车硬件介绍-(全网最详细)基于STM32智能小车-蓝牙遥控、避障、循迹、跟随、PID速度控制、视觉循迹、openmv与STM32通信、openmv图像处理、smt32f103c8t6_基于stm32 openmv硬件选择
- 2视频AI方案:数据+算力+算法,人工智能的三大基石_视频ai处理方案
- 3吴恩达课程笔记 第三课 无监督学习,推荐系统,强化学习_吴恩达强化学习
- 4【编程题目 |100分】音乐小说内容重复识别【华为OD机试 2024 Q2考试题 C卷】
- 5浅谈功能测试和性能测试的区别_功能检测和电性能检测区别
- 6LeetCode-894-所有可能的满二叉树-C语言_code8094
- 7vue页面跳转之后滚动条消失的解决方法_vue 滚动条消失
- 8MongoDB之客户端工具与核心概念及基本类型篇_mongodb客户端
- 9UE4 学习资料_ue4培训资料包
- 10人工智能工程师要具备的5项基本技能_2020年2月 “ 填空 1 ”正式成为新职业隶属于软件和信息技术服务人员小类
当前位置: article > 正文
基于python的大数据分析与应用环境的搭建
作者:不正经 | 2024-06-16 23:02:06
赞
踩
基于python的大数据分析与应用环境的搭建
一、主要目的:
初步熟悉Python数据分析工具,通过查阅相关说明文档掌握Numpy、Scipy和Pandas包的基本使用方法。对于不同形式的源数据文件,能够基于python开发环境正确的完成数据导入。
二、主要内容:
1、Python开发环境安装以及数据分析包的加载
(1)Anaconda安装过程
(2)相关第三方库的加载 如 爬虫scrapy包。
提示:
① Anaconda下载地址:
② Anaconda安装参考:
https://blog.csdn.net/weixin_37766087/article/details/100742198
2、通过简要的实例代码熟悉开发环境以及数据分析包的基本功能
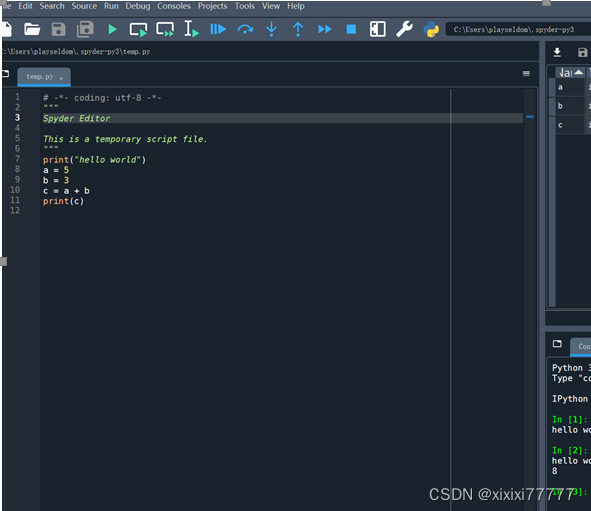
(1)代码实例展示Spyder的基本功能
例如:代码提示、变量浏览、图形查看
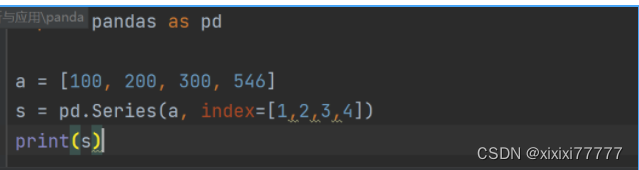
- 代码实例展示Pandas 中的数据结构
① Series:一维数组系列,也称序列
② DataFrame:二维表格型数据结构。可以将DataFrame理解为Series的容器。
- 数据的导入与导出
- 导入不同形式的文件,例如.txt/.csv/.excel
- 导出到csv/excel
- 导入导出MySql库[附选]
三、实验过程:
1.Anaconda安装过程
已安装


2.Spyder
① Series:一维数组系列,也称序列

② DataFrame:二维表格型数据结构。

导入不同形式的文件,例如.txt/.csv/.excel
导入excle
- df = pd.read_excel(io='自己的文件路径',index_col='序号')
- print(df)
导出到csv/excel
Excel:
- writer = pd.ExcelWriter('age-name.xlsx')
- df.to_excel(writer)
- writer.save()
CSV:
- csv_data = df.to_csv("自己的文件路径",sep='|')
导入导出MySql库[附选]
- 从mysql中导出dataframe对象
- conn = pymysql.connect(host="localhost",port=3306,user="root",
- password="密码已经被和谐",database="school",charset="utf8")
- sql = "select * from student;"
- df = pd.read_sql(sql,conn)
- print(df)
- 导入dataframe数据到mysql
- from sqlalchemy import create_engine
- engine = create_engine("mysql+pymysql://root:密码已被和谐@localhost:3306/school?charset=utf8")
- data = [['小明',14],['东东',18],['奥图码',53]]
- df = pd.DataFrame(data,columns=['姓名','年龄'])
- df.to_sql("try", engine, schema="try")
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/728654
推荐阅读
相关标签

