
- 1MacOS下修改hosts文件的两种方法_macos hosts 只读
- 2Unity3D内嵌html网页+通信
- 3RHEL 6.4(i386)安装基于fcitx的搜狗拼音输入法_sogoui386
- 4修改之前的多条commit提交记录_提交多次commit gerrit changeid
- 5PyCharm下载、安装及相关配置(Windows 11)详细教程
- 6初识EMC元器件(九)——气体放电管的参数解读及选型应用_气体放电管选型
- 7linux命令看cpu使用率,怎么使用Linux命令查看CPU使用率
- 8【嵌入式】STM32的3种Boot与实例验证_嵌入式boot启动模式
- 9Executable path is not absolute, ignoring: xxx
- 10基于模板匹配的运动目标跟踪_bmp 基于模板匹配的运动目标跟踪
【机器学习300问】22、什么是超参数优化?常见超参数优化方法有哪些?
赞
踩
在之前的文章中,我主要介绍了学习率 η和正则化强度 λ 这两个超参数。这篇文章中我就主要拿这两个超参数来进行举例说明。如果想在开始阅读本文之前了解这两个超参数的有关内容可以参考我之前的文章,文章链接为你放在了这里:
【机器学习300问】10、学习率设置过大或过小对训练有何影响?![]() http://t.csdnimg.cn/ZvFiw【机器学习300问】18、正则化是如何解决过拟合问题的?
http://t.csdnimg.cn/ZvFiw【机器学习300问】18、正则化是如何解决过拟合问题的?![]() http://t.csdnimg.cn/Pmn6E
http://t.csdnimg.cn/Pmn6E
一、什么是机器学习中的参数和超参数
机器学习中的参数与超参数在训练模型时扮演着不同的角色,一句话说明两者的关系:“参数是机器学习算法自己学习到的,超参数是人工设定的。”
(1)参数(parameters)的定义和作用
参数是模型在训练过程中学习到的变量,通常代表模型对输入数据的内在表示或模型的内在结构特征,他是模型的一部分;在神经网络中,每个神经元的权重和偏置都是参数。
(2)超参数(hyperparameters)的定义和作用
超参数是在开始训练模型之前由人设置的变量,它们不是通过训练数据学习得到的,而是指导模型训练过程和结构的关键设定。
二、什么是超参数优化?
(1)看个例子
设想一个回归任务,如下图所示,用不同次数的多项式(多项式的次数就是这个回归任务的超参数)进行拟合,可以得到不同的模型。正确的设置模型多项式的次数,就可以让模型的拟合效果最佳且泛化能力最好。
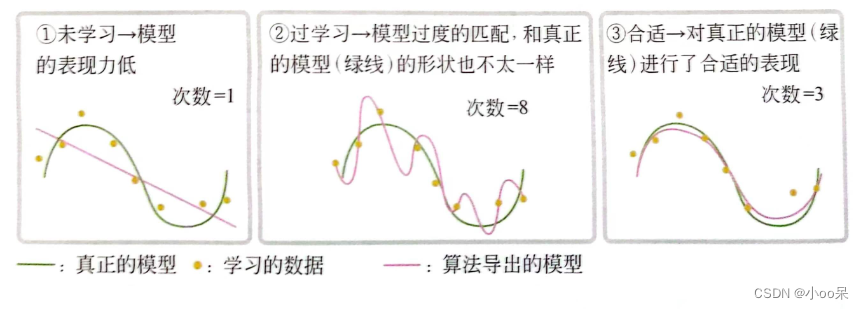
但绝大多数情况下无法想这个图中显示的直观感受出超参数该怎么设置。
(2)超参数优化的定义
超参数优化是指在训练机器学习模型时,通过自动调整模型中的超参数来寻求最优模型性能的过程。
(3)为什么要进行超参数优化
- 最优超参数组合可能并不直观,不同数据集、模型结构可能需要不同的超参数设置。手动设置超参数可能无法挖掘出模型的最佳性能。
- 手动尝试不同的超参数组合需要花费大量时间和计算资源,尤其是对于大型模型和复杂任务,可能需要尝试几十甚至上百种不同的超参数组合。
(4)超参数优化的目的是什么?
超参数优化的目的是在多维空间(每个维度就是某一个超参数的可能取值)中找到使模型性能(如在验证集上的精度或AUC等指标)达到最优的超参数组合。
(5)为什么是对超参数组合作为整体进行优化而不是先优化其中一个再优化另一个?
① 超参数组合是什么
超参数组合,拿学习率、正则化强度举例,是指特定的某个学习率和正则化强度比如(0.01, 0.1)这意味着学习率被设置为0.01,而正则化强度被设置为0.01。
② 超参数之间相互影响
在机器学习和深度学习中,超参数之间的关系往往是相互耦合和相互影响的。例如,学习率和正则化强度共同决定了模型的训练过程和最终的泛化性能。它们之间并非独立作用,而是彼此交织影响模型的表现。
三、常见的超参数优化方法有哪些?
(1)网格搜索(Grid Search)
网格搜索是一种系统性的超参数搜索方法,它通过在预先定义好的超参数网格上遍历所有可能的超参数组合,并在验证集上评估每个组合下的模型性能。最后,选择验证性能最佳的超参数组合。虽然网格搜索方法简单易行,但它在超参数空间很大的情况下会变得非常耗时和资源密集。
(2)随机搜索(Random Search)
随机搜索同样在预定义的超参数空间里进行搜索,但它不像网格搜索那样穷举所有组合,而是随机抽样一些超参数组合进行评估。这种方法相对于网格搜索更高效,尤其在高维超参数空间时,随机搜索可能更快地找到较好的超参数设置。但由于其随机性,有可能会错过最优参数。
(3)贝叶斯优化(Bayesian Optimization)
贝叶斯优化是一种基于概率的优化方法,利用概率模型(如高斯过程)通过观测之前的超参数设置及其对应的验证性能,不断更新概率模型,来预测下一个最有希望的超参数组合。相较于网格搜索和随机搜索,贝叶斯优化通过构建概率模型来预测哪些参数可能会得到更好的结果,因此要比前面两种方法更高效。

