
- 1改进神经网络
- 2linux shell 脚本 入门到实战详解[⭐建议收藏!!⭐]
- 3基于 ANN 进行非线性系统识别附matlab代码_matlab神经网络ann 验证测试是什么
- 4基于matlab程序实现人脸识别
- 5应用容器引擎之 docker 学习(一)docker的定义+架构以及三要素+与传统虚拟机的对比_游戏引擎 docker 序列化
- 6*++p、++*p、(*p)++、*(p++)、*p++的区别
- 7云计算职业技能大赛组件介绍(二)_openstack私有云平台,修改普通用户权限,使普通用户不能对镜像进行创建和删除操作
- 8校园安全防控管理系统(源码+开题报告)
- 9nodejs+vue旅游网站设计express+vscode_vscode的旅游网站用户个人信息管理网站
- 10手把手教你写HT1621显示驱动,简单明了,内含原码,方便移植,_tm1621d驱动问题
Vision Transformer(VIT)
赞
踩
VIT代表着transformer向cv领域的正式进军,nlp在transformer中将字符转为token,如要将cv中每个像素点作为token,224*224=50176>>512,参数量巨大。VIT提供了一个成功的思路将图像转为一定长度的token又能保留二维空间信息。
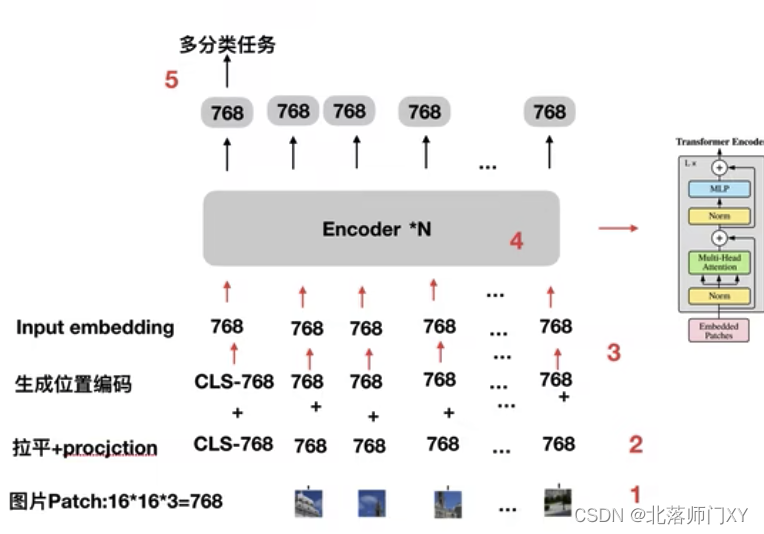
VIT步骤为:
1、将图像切分为patch,如将224*224的图片切成16*16的patch,每个patch的大小为16*16*3
2、将patch信息拉平,线性层映射为指定位数如768或1024(embedding size),这一步也可以不使用线性层而用16x16尺度,步长为16,通道数为768的卷积实现
3、采用torch.rand随机初始化的方式分别生成cls符号的token embedding、所有序列的位置编码,位置编码与token embedding相加。VIT采用了自动学习的位置编码方式
4、多个Transforer编码器组成的模型主体
5、取出cls信息作loss计算
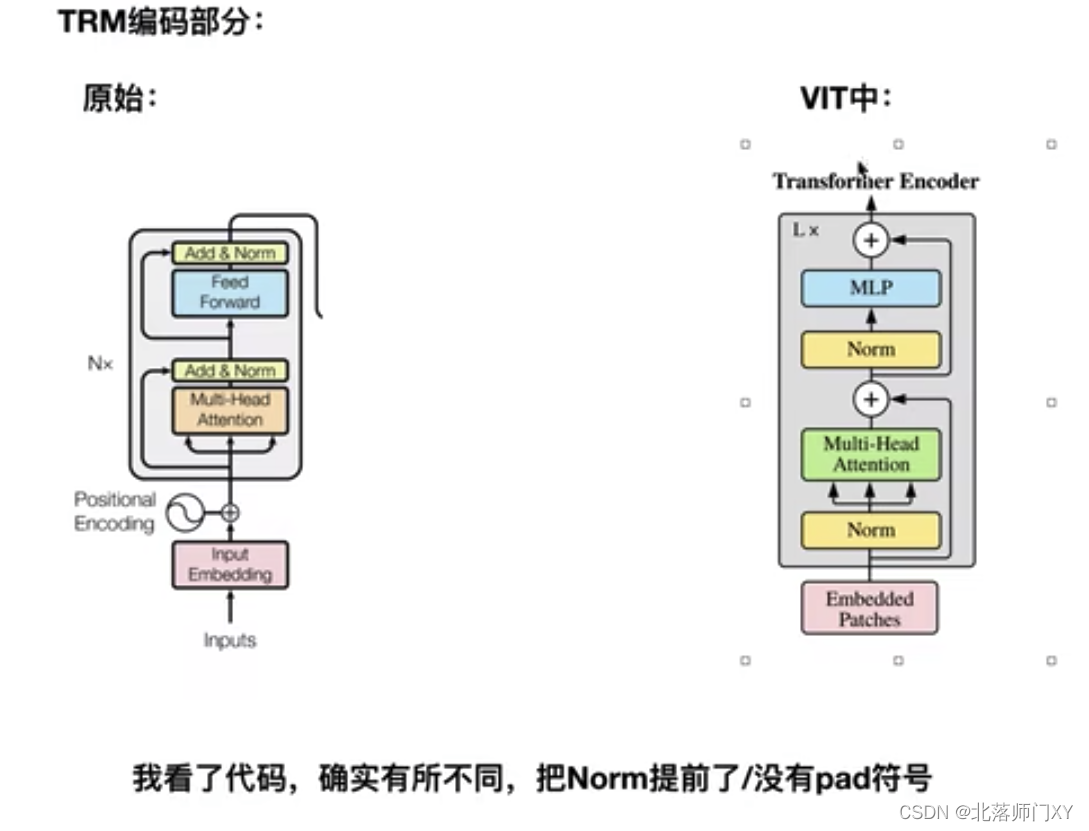
vit采用了transformer的编码部分,区别在于
1)Norm前置
2)输入大小是固定的,无需进行pad
FAQ:
Q:位置编码目的
A: rnn的输入有时序关系,但transformer的patch是一起输入的,需增加前后关系
Q:位置编码为什么是相加而不是拼接
A:拼接维度变大,未见到什么特别有说服力的说法
Q:为什么是1维位置编码
A:对比后加一维比不加好,改成2维、相对位置编码区别不大
Q: fast qkv
A: 有些模型只用到了transformer的编码结构,编码结构中qkv可以通过1个线性层统一计算后再chunk切块操作分头成3个q、k、v。解码结构中q来自解码端,k、v来自编码端就不能这么操作。
- # fast qkv 方式
- # 使用torch.chunk函数(torch.cat的逆函数),将qkv拆成3个部分,分别是q、k、v,每一个尺寸均为(n_batch, n_token, hidden_size)
-
- self.qkv_linear = nn.Linear(config.hidden_size, 3 * self.all_head_size, bias=False) # 768->3*768
- qkv = self.qkv_linear(hidden_states)
- q, k, v = torch.chunk(qkv, 3, dim=-1)
-
-
- # 分别计算方式
- self.query = nn.Linear(config.hidden_size, self.all_head_size) # 768->768 self.key = nn.Linear(config.hidden_size, self.all_head_size)
- self.value = nn.Linear(config.hidden_size, self.all_head_size)
- q = self.query(hidden_states)
- k = self.key(hidden_states)
- v = self.value(hidden_states)
缺点:
1)需要大数据集进行预训练,小规模数据集上效果会差一点,收敛速度也比resnet等慢。在中小型数据集上预训练,ViT是不如resent的,只有在大型数据集上预训练,ViT表现要比resent好。后面的Deit、Beit通过修改预训练任务的方式解决这个问题。
2)不适合于高分辨率场景。swinT解决了这个问题。

