
热门标签
热门文章
- 1浅议Flink中算子间的八种数据传输策略_flink 算子数据怎么传输
- 2深入了解Qt 控件:Display Widgets部件(1) 以及 QT自定义控件(电池)
- 3python flink kafka_开发者干货 | 当Flink遇到Kafka - FlinkKafkaConsumer使用详解
- 4推荐丨解决网站被浏览器提示不安全的方案_网页左上角不安全
- 5Python爬虫实战:1000图库大全,新手也能实操_python网络爬虫实战1000数据
- 6VUE使用v-html解析失败和解决方案_v-html不生效
- 7Pycharm的安装以及如何跳过试用设置永久使用?(Windows专业版2023-2024)_pycharm专业版无限试用
- 8【FPGA Verilog开发实战指南】初识Verilog HDL-基础语法_fpga开发实战指南
- 9【论文解析】基于Anchor-free的一阶段经典目标检测算法FCOS_anchor free发展
- 10python socket模块 TCP协议 两个py文件的通讯02_python tcp 通信双方
当前位置: article > 正文
sft的时代过去了?融合监督微调和偏好对齐的新算法orpo来了_orpo微调
作者:人工智能uu | 2024-07-02 16:44:22
赞
踩
orpo微调
sft的时代过去了?融合监督微调和偏好对齐的新算法orpo来了
原创 nipi NLP前沿 2024-04-20 20:09 湖北

NLP前沿
日更,近3天较实用的论文速读,这里的选文真的很干很前沿!!!
254篇原创内容
公众号
- https://huggingface.co/blog/mlabonne/orpo-llama-3
- https://arxiv.org/html/2403.07691v2
- https://colab.research.google.com/drive/1eHNWg9gnaXErdAa8_mcvjMupbSS6rDvi?usp=sharing
ORPO是一种的新的微调技术,将传统的监督微调和偏好对齐阶段结合到一个过程中。这减少了训练所需的计算资源和时间。此外,结果表明,ORPO在各种模型大小和基准上都优于其他对齐方法。常用的trl、llama-factory等已经支持了该算法。在上面链接中有个colab实现了使用orpo微调llama3-8b。
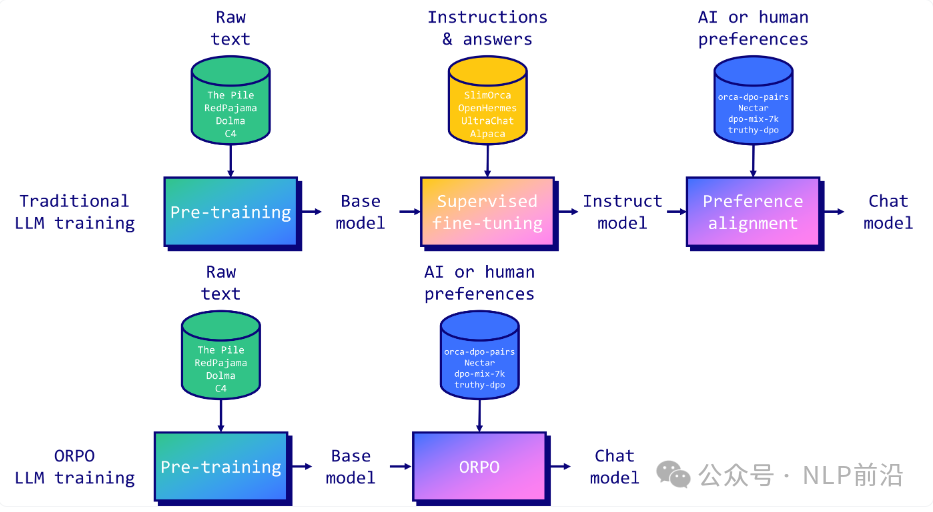
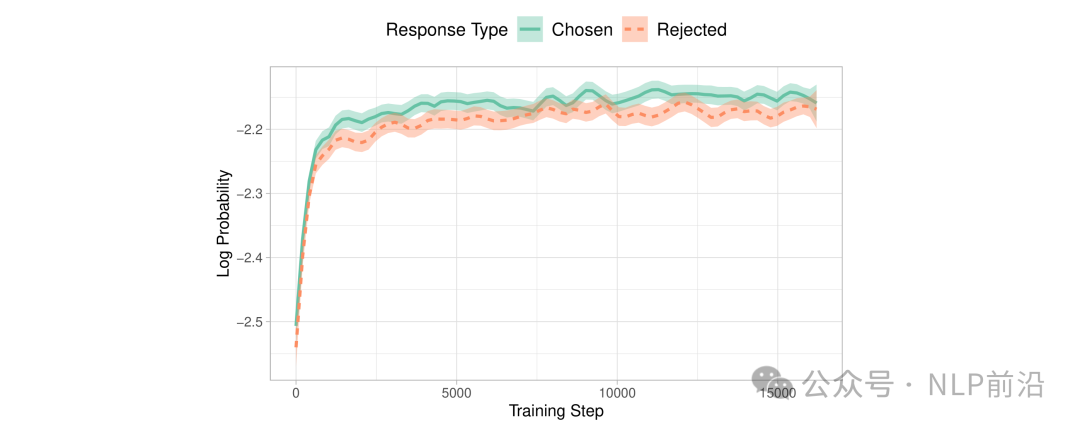
虽然 SFT 有效地使模型适应所需的领域,但它无意中增加了与最有答案一起生成不良答案的可能性。这就是为什么需要偏好对齐阶段来扩大首选输出和拒绝输出的可能性之间的差距。如下图HH-RLHF数据集上OPT-350M模型中选择和拒绝答案的对数概率
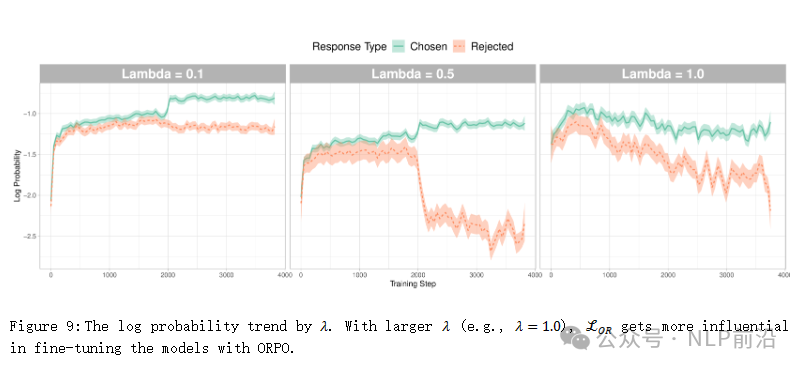
实现原理非常简单,如下图,在正常的sft损失基础上,约束y_w的概率要远大于y_l

对比最上面一张图训练过程中y_w和y_l的gap出现了
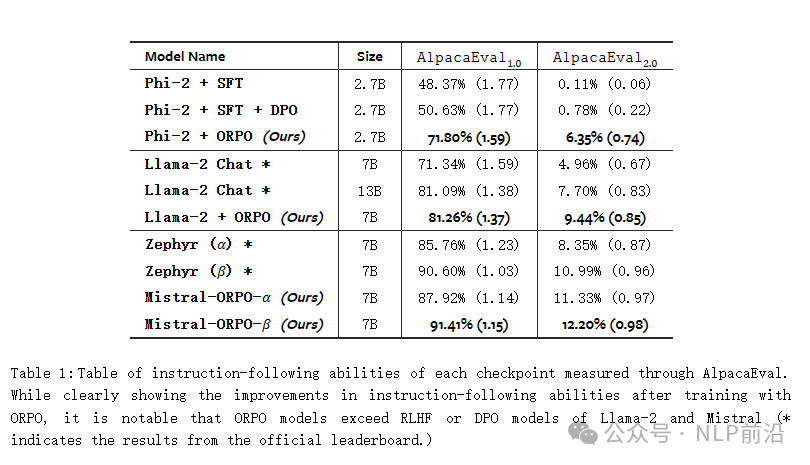
看一张效果图:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/人工智能uu/article/detail/780255
推荐阅读

相关标签

