
- 1心率血氧传感器方案
- 2Android科大讯飞TTS语音合成实例详细步骤_科大讯飞tts引擎调语速
- 3pytorch详细安装+cuda环境配置_pytorch cuda
- 4Python开发区块链之03如何生成bitcoin address
- 5git远程分支强制覆盖本地分支_git强制远程覆盖本地
- 6Simple Baselines for Image Restoration
- 7史上最详细的Python安装教程,小白建议收藏!
- 8【艾琪出品】-【大数据导论】测试题系列一_概念描述的主要方法是对目标数据进行概述性的总结
- 9CSS的继承性和选择器优先级_css 父元素设置样式所以子元素生效
- 10AIGC大时代背景,20美金都付了,一文看看GPT4对Apollo的认知和想法_红外热成像 百度apollo
TransGAN:使用Transformer替换卷积也可以构建一个强力的GAN_gan transformer
赞
踩
生成对抗网络(GANs)已经在包括图像合成、图像翻译和图像编辑在内的许多任务中取得了相当大的成功。但是因为生成对抗网络训练不稳定,为了稳定GAN训练付出很多人付出了许多努力例如引入了各种正则化方法,使用更好的损失函数和优化训练方法等。
几乎每个成功的GAN都依赖于基于CNN的生成器和鉴别器。卷积具有对自然图像处理的优势,对现代GAN具有吸引力的视觉效果和丰富的多样性做出了至关重要的贡献,但除优化困难外,这还可能导致特征分辨率和精细细节的损失(例如图像模糊)。
本次介绍的论文研究构建一个完全没有卷积的GAN,只使用纯基于transformer的架构。它们首先通过逐步增加特征图的分辨率,同时减小每个阶段的嵌入维数,从基于transformer的生成器开始。鉴别器(也是基于transformer的)将图像块而不是像素标记为输入,并在真实图像和生成图像之间进行分类,他们使用具有自我监督辅助损失的多任务协同训练策略以及本地初始化的自注意力机制用来强调自然图像的邻域平滑度(提高图像平滑,减少模糊)。

论文提出了一种基于内存友好的基于transformer的阶段的生成器(CIFAR-10的默认值为3)。 每个阶段堆叠几个编码器块(默认情况下为5、2和2)。 他们逐步地增加了特征图的分辨率,直到达到目标分辨率HT×WT为止。 具体来说,生成器将随机噪声作为输入,并将其通过多层感知机(MLP)传递到长度为H×W×C的向量。该向量将重塑为H×W分辨率特征图(默认为H = W = 8),每个点都是C维的特征嵌入。 接下来,将此特征图视为长度为64的C维令牌的序列,并结合可学习的位置编码。
transformer 的编码器将嵌入令牌作为输入并递归计算每个令牌之间的对应关系。
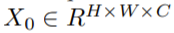
然后采用pixelshuffle对其分辨率进行上采样,对嵌入维数进行下采样,得到输出
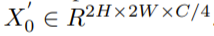
在此之后,二维特征映射X '_0再次被重塑为嵌入令牌的1D序列,令牌编号为4HW,嵌入维数为C/4。
所以在每个阶段分辨率(H,W)都会增大2倍,而嵌入特征尺寸C会减小到输入的四分之一,它们会重复多个阶段直到分辨率达到(H_T,W_T),然后投影嵌入 缩放到3并获得RGB图像Y。
鉴别器将图像的小块作为输入,他们将输入图像Y分成8×8个小块,其中每个小块可被视为“单词”。 然后将8×8补丁通过flatten层转换为一维令牌嵌入序列,令牌编号N = 8×8 = 64,嵌入特征维数等于C。之后,添加可学习的位置编码,并添加[ cls]令牌附加在1D序列的开头。 通过transformer编码器后,分类头仅获取[cls]令牌,以输出实/假预测。

TransGAN在STL-10上将最新的IS评分提高到了10.10,FID评分为25.32。 CIFAR10的IS评分为8.63分,FID评分为11.89分,CelebA 64 × 64的FID评分为12.23分。
最后论文地址:
1.Yifan Jiang, Shiyu Chang, Zhangyang Wang.TransGAN: Two Transformers Can Make One Strong GAN,arXiv:2102.07074

