
- 1基于微信小程序的考勤打卡系统_微信小程序打卡
- 2如何利用开源工具搭建AI大模型底座_ai模型搭建
- 3〔010〕Stable Diffusion 之 VAE 篇_stable diffusion vae是什么
- 4Sora文生视频模型深度剖析:全网独家指南,洞悉98%关键信息,纯干货
- 5Kafka Rebanlace次数过高问题_kafka消费者过多 启动异常
- 6python librosa显示音乐频谱_librosa 频谱
- 7Unity插件Obi.Rope详解_obi rope
- 8【k8s部署 】k8s构建Flannel网络插件失败The connection to the server raw.githubusercontent.com was refused问题解决_k8s安装网络插件显示链接拒绝
- 934. 在排序数组中查找元素的第一个和最后一个位置
- 102021-07-17bert选修补充_神经网络加adaptor
python 自动化数据提取之正则表达式_python正则表达式提取
赞
踩
前 言
我们在做接口自动化的时候,处理接口依赖的相关数据时,通常会使用正则表达式来进行提取相关的数据,今天在这边和大家聊聊如何在python中使用正则表达式。
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),是计算机科学的一个概念。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。按某种规则匹配的表达式被称之为正则表达式,在python使用正则表达式,可以使用官方库re来实现,学习re模块之前,我们先来了解一下正则表达式的基本语法。
正 则 表 达 式 语 法
NO.1表示单字符
单字符:即表示一个单独的字符,比如匹配数字用\d ,匹配非数字使用\D,具体规则如下:

NO…2表示数量
如果要匹配某个字符多次,就可以在字符后面加上数量进行表示,具体规则如下:
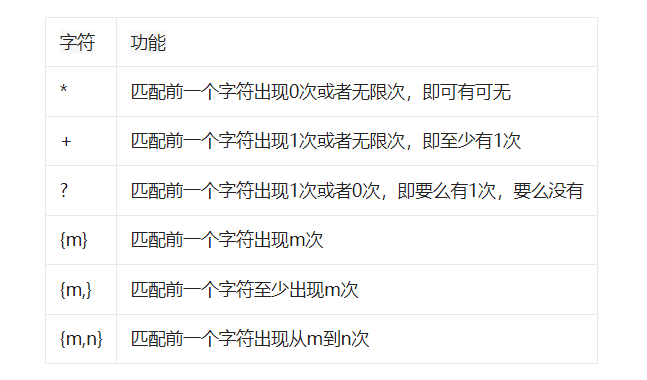
NO.3表示边界
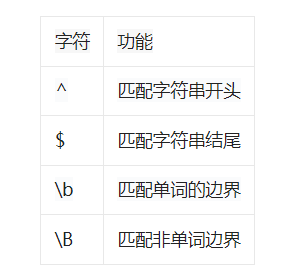
NO.4匹配分组

NO.5 贪婪模式
贪婪模式:Python里数量词默认是贪婪的,总是尝试匹配尽可能多的字符;
如下案例:有一个字符串s,我们需要在字符串中匹配3个以上的数字,字符串中数字有8个,贪婪模式会尽可能匹配更多字符,3个以上,8个也是3个以上,那么这里匹配的结果就是8个数字。
非贪婪模式:总是尝试匹配尽可能少的字符,在"*“,”?“,”+“,”",后面加上?,可以关闭贪婪模式
关闭贪婪模式之后,尽可能获取更少的,如下,只获取到最前面的3个数值(至少3个,非贪婪就是最前面的3个)
r e 模 块 的 使 用
在python中使用正则表达式,需要用到re模块来进行操作,这边给大家介绍几个re模块中常用的方法。
No.1 re.match函数
参数说明:接收两个参数,
第一个是匹配的规则,
第二个是匹配的目标字符串,
re.match尝试从字符串的起始位置匹配一个模式,匹配成功 返回的是一个匹配对象(这个对象包含了我们匹配的信息),如果不是起始位置匹配成功的话,match()返回的就是空。
No.2 re.search 方法
参数说明:接收两个参数,
第一个是匹配的规则,
第二个是匹配的目标字符串,
re.search 扫描整个字符串并返回第一个成功的匹配。
re.match与re.search的区别
re.match从字符串的开始位置进行匹配,如果字符串开始不符合正则表达式,则匹配失败,函数返回空;
而re.search匹配整个字符串,直到找到一个匹配成功的则进行返回,如果整个字符串中都没有找到匹配成功的,则返回空。
No.3 findall 方法
参数说明:接收两个参数,
第一个是匹配的规则,
第二个是匹配的目标字符串,
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意:match 和 search 是匹配一个结果, findall 匹配处所有符合规则的结果。
No.4 sub 方法
替换字符串中的某些字符,可以用正则表达式来匹配被选子串。
re.sub(pattern, repl, string, count=0 )
- 1
参数:
pattern:匹配的规则;
repl:匹配之后替换的新内容;
string:需要按规则替换的字符串;
count:替换的次数,可以不传参,默认替换所有符合规则的。
案 例 演 示
需求:整个正则表达式提取如下接口登录之后返回的token值。
接口地址:
http://47.112.233.130/users/login/请求参数:返回结果:
{'refresh': 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ0b2tlbl90eXBlIjoicmVmcmVzaCIsImV4cCI6MTY1Mzk4MzMyNSwiaWF0IjoxNjUzODk2OTI1LCJqdGkiOiI2NTE2MTE0OGFhMDY0NWNjYWY2ZWE4YmYzYzY1YjE1ZSIsInVzZXJfaWQiOjJ9.fMkJfOdhczbr1MqvYE5b0qYlC5GewBlFZbrteMOLUv0', 'token': 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ0b2tlbl90eXBlIjoiYWNjZXNzIiwiZXhwIjoxNjUzOTgzMzI1LCJpYXQiOjE2NTM4OTY5MjUsImp0aSI6ImQ3Nzg1ZjY0YTk2YzQwYzliZDcwMmUxMDgzNjVkNWU5IiwidXNlcl9pZCI6Mn0.UNmLRQsXnZBltgL7QQVuBON2UEBQav87NSGy5Iqbnws'}
- 1
实现代码
import requests import re # 登录接口 login_url = 'http://47.112.233.130:8888/users/login/' # 请求登录接口,进行登录 params = { "username": "test", "password": "123456" } response = requests.post(url=login_url, json=params) #使用正则表达式提取token result = re.search(r'token":"(.+?)"',response.text) token = result.group(1)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
上述案例中关于token的提取我们使用的是正则表达式,除了正则之外,进行数据提取还有很多方式可以实现,比如jsonpath,xpath等等。jsonpath只能在接口返回的是json格式数据的情况下使用,xpath适用于接口返回的是XML或者HTML时使用。
最后: 可以在公众号:伤心的辣条 ! 自行领取一份216页软件测试工程师面试宝典文档资料【免费的】。以及相对应的视频学习教程免费分享!,其中包括了有基础知识、Linux必备、Shell、互联网程序原理、Mysql数据库、抓包工具专题、接口测试工具、测试进阶-Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架、性能测试、安全测试等。
学习不要孤军奋战,最好是能抱团取暖,相互成就一起成长,群众效应的效果是非常强大的,大家一起学习,一起打卡,会更有学习动力,也更能坚持下去。你可以加入我们的测试技术交流扣扣群:914172719(里面有各种软件测试资源和技术讨论)
喜欢软件测试的小伙伴们,如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一键三连哦!

