
热门标签
热门文章
- 1Unity_Spine效率优化_unity spine优化
- 2Unreal Engine 4 + miniconda + Python2.7 + Pycharm_python的unreal库
- 3react-antd中modal组件内form数据回收_antd form modal preserve
- 4Doris-0.15 安装_doris windows安装
- 5图像特征提取(VGG和Resnet特征提取卷积过程详解)_resnet vgg
- 6完美解决主机与虚拟机相互通信,相互ping等问题_虚拟机ping自己主机
- 7vue3项目大片报红-首行报红-红色波浪(ts+vue)报红修复_vue3 v-model:visible="visible" 爆红
- 8python中列表的功能_python 中列表的基本操作
- 9自定义icon,在iconfont.css中引入自定义图标_css 可编辑图标
- 10Core Image详解_.net core image类
当前位置: article > 正文
Python多线程并发编程_from threading import condition
作者:从前慢现在也慢 | 2024-03-02 16:00:56
赞
踩
from threading import condition
一、Python中的GIL
介绍:
- GIL的全称global interpreter lock 意为全局解释器锁。
- Python中的一个线程对应与c语言中的一个线程。
- GIL使得同一时刻一个CPU只能有一个线程执行字节码, 无法将多个线程映射到多个CPU上执行。
- GIL会根据执行的字节码行数以及时间释放GIL,GIL在遇到IO的操作时候会主动释放
# GIL会释放,最后的结果不定。释放的位置不定 total = 0 def add(): global total for i in range(1000000): total += 1 def desc(): global total for i in range(1000000): total -= 1 import threading thread1 = threading.Thread(target=add) thread2 = threading.Thread(target=desc) thread1.start() thread2.start() thread1.join() thread2.join() print(total)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
数值不确定
- 1
二、Python多线程编程
2.1、通过threading实现多线程
# 对于io操作,多线程和多进程性能差别不大 import time import threading def get_detail_html(url): print('我获取详情内容了') time.sleep(2) print('我获取内容完了') def get_detail_url(url): print('我获取url了') time.sleep(2) print('我获取url完了') if __name__=='__main__': thread1=threading.Thread(target=get_detail_html,args=('',)) thread2=threading.Thread(target=get_detail_url,args=('',)) start_time=time.time() thread1.start() thread2.start() #时间非常小,是运行代码的时间差,而不是2秒 #这样运行一共有三个线程,主线程和其他两个子线程(thread1,thread2),而且是并行的,子线程启动后,主线程仍然往下运行,因此时间不是2秒 #守护线程(主线程退出,子线程就会kill掉) print('last time:{}'.format(time.time()-start_time))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
我获取详情内容了
我获取url了
last time:0.0009658336639404297
我获取内容完了
我获取url完了
[Finished in 2.1s] # 运行时间,输出内容先后存在不确定性
- 1
- 2
- 3
- 4
- 5
- 6
2.2、守护线程
import time import threading def get_detail_html(url): print('我获取详情内容了') time.sleep(4) print('我获取内容完了') def get_detail_url(url): print('我获取url了') time.sleep(2) print('我获取url完了') if __name__=='__main__': thread1=threading.Thread(target=get_detail_html,args=('',)) thread2=threading.Thread(target=get_detail_url,args=('',)) #将线程1设置成守护线程(主线程退出,该线程就会被kill掉),但会等线程2运行完(非守护线程) thread1.setDaemon(True) start_time=time.time() thread1.start() thread2.start() print('last time:{}'.format(time.time()-start_time))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
我获取详情内容了
我获取url了
last time:0.0009963512420654297
我获取url完了
[Finished in 2.1s]
- 1
- 2
- 3
- 4
- 5
2.3、join
等某个子线程执行完在继续执行主线程代码:
import time import threading def get_detail_html(url): print('我获取详情内容了') time.sleep(4) print('我获取内容完了') def get_detail_url(url): print('我获取url了') time.sleep(2) print('我获取url完了') if __name__=='__main__': thread1=threading.Thread(target=get_detail_html,args=('',)) thread2=threading.Thread(target=get_detail_url,args=('',)) start_time=time.time() thread1.start() thread2.start() #等待两个线程执行完 thread1.join() thread2.join() print('last time:{}'.format(time.time()-start_time))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
我获取详情内容了
我获取url了
我获取url完了
我获取内容完了
last time:4.0015480518341064
- 1
- 2
- 3
- 4
- 5
更多方法:
- start 线程准备就绪,等待CPU调度
- setName 为线程设置名称
- getName 获取线程名称
- setDaemon 设置为后台线程或前台线程(默认)
如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止
如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止 - join 逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
- run 线程被cpu调度后自动执行线程对象的run方法
2.4、继承Thread实现多线程
import time import threading class GetDetailHtml(threading.Thread): def __init__(self, name): super().__init__(name=name) def run(self): print('我获取详情内容了') time.sleep(4) print('我获取内容完了') class GetDetailUrl(threading.Thread): def __init__(self,name): super().__init__(name=name) def run(self): print('我获取url了') time.sleep(2) print('我获取url完了') if __name__=='__main__': thread1=GetDetailHtml('get_detail_html') thread2=GetDetailUrl('get_detail_url') start_time=time.time() thread1.start() thread2.start() #等待两个线程执行完 thread1.join() thread2.join() print('last time:{}'.format(time.time()-start_time))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
我获取详情内容了
我获取url了
我获取url完了
我获取内容完了
last time:4.015072822570801
- 1
- 2
- 3
- 4
- 5
三、线程间通信-Queue
3.1、线程通信方式——共享变量:(全局变量或参数等)
注:共享变量的方式是线程不安全的操作(不推荐)
- 1
import time import threading url_lists = [] def get_detail_html(): #可以单独放在某一个文件管理(注意引入时要引用文件) global url_lists url_lists=url_lists while True: if len(url_lists): url=url_lists.pop() print('我获取详情内容了') time.sleep(4) print('我获取内容完了') def get_detail_url(url_lists): while True: print('我获取url了') time.sleep(2) for i in range(20): url_lists.append('url'+str(i)) print('我获取url完了') if __name__ == '__main__': thread_url=threading.Thread(target=get_detail_url,args=(url_lists,)) thread_url.start() #开启十个线程爬取详情 for i in range(10): thread_html=threading.Thread(target=get_detail_html,) thread_html.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
我获取url了
我获取url完了
我获取详情内容了
我获取详情内容了
我获取详情内容了
我获取url了
我获取url完了
我获取url了
.......
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.2、通过queue的方式进行线程同步
注:是线程安全的(Queue本身就是线程安全的【使用了线程锁的机制】,使用了双端队列,deque)
- 1
Queue中的方法:
- qsize()查看对列大小。
- empty()判断队列是否为空。
- full()判断队列是否满,满了的话put方法就会阻塞,等待有空位加入。
- put()将数据放入队列,默认是阻塞的(block参数,可以设置成非阻塞,还有timeout等待时间)。
- get()从队列取数据
import time import threading from queue import Queue def get_detail_html(queue): while True: url=queue.get() print('我获取详情内容了') time.sleep(4) print('我获取内容完了') def get_detail_url(queue): while True: print('我获取url了') time.sleep(2) for i in range(20): queue.put('url'+str(i)) print('我获取url完了') #执行该方法才能执行退出,和join成对出现 urls_queue.join() urls_queue.task_done() if __name__ == '__main__': #设置队列最大值1000,过大对内存会有很大影响 urls_queue=Queue(maxsize=1000) thread_url=threading.Thread(target=get_detail_url,args=(urls_queue,)) thread_url.start() #开启十个线程爬取详情 for i in range(10): thread_html=threading.Thread(target=get_detail_html,args=(urls_queue,)) thread_html.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
我获取url了
我获取url完了
我获取详情内容了
我获取详情内容了
我获取详情内容了
我获取详情内容了
我获取详情内容了
我获取详情内容了
......
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
四、线程同步
4.1、线程锁机制 Lock
锁住的代码段都只能有一个代码段运行
获取(acquire)和释放(release)锁都需要时间:因此用锁会影响性能;还有可能引起死锁(互相等待,A和B都需要a,b两个资源,A获取了a,B获取了B,A等待b,B等待a或则未释放锁再次获取)
"""
A(a, b)
acquire(a)
acquire(b)
B(a, b)
acquire(b)
acquire(a)
A想运行必须先拿到a在拿到b才能运行。
B想运行必须先拿到b在拿到a。
如果A在拿到a资源的同时B拿到了b的资源那么就形成了死锁。如果B acquire(a) acquire(b) 就不会形成死锁
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
import threading from threading import Lock total=1 lock=Lock() def add(): global total for i in range(1000000): #获取锁 lock.acquire() total+=1 #释放锁,释放后其他才能获取 lock.release() def decs(): global total for i in range(1000000): lock.acquire() total-=1 lock.release() thread1=threading.Thread(target=add) thread2=threading.Thread(target=decs) thread1.start() thread2.start() thread1.join() thread2.join() print(total)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
1
- 1
4.2、RLock-可重入的锁
在一个线程中可以,可以连续多次acquire(获取资源),一定要注意acquire的次数要和release的次数一致
# 获得两次资源
lock.acquire()
lock.acquire()
total += 1
lock.release() # 释放锁
lock.release() # 释放锁
- 1
- 2
- 3
- 4
- 5
- 6
4.3、Condition-条件变量
使用锁进行先后对话:发现先启动的线程把话先说完(第一个线程启动后运行完,第二个线程还没有启动,或者还未切换到另一个线程)
from threading import Condition # 条件变量,用于复杂的线程间同步 import threading class XiaoAi(threading.Thread): def __init__(self, lock): super().__init__(name="小爱") self.lock = lock def run(self): self.lock.acquire() print("{}:在".format(self.name)) self.lock.release() self.lock.acquire() print("{}:好啊".format(self.name)) self.lock.release() class TianMao(threading.Thread): def __init__(self, lock): super(TianMao, self).__init__(name="天猫") self.lock = lock def run(self): self.lock.acquire() print("{}:小爱同学".format(self.name)) self.lock.release() self.lock.acquire() print("{}:我们来对古诗吧".format(self.name)) self.lock.release() # 通过condition完成协同读诗 class XiaoAi1(threading.Thread): def __init__(self, cond): super().__init__(name="小爱") self.cond = cond def run(self): with self.cond: self.cond.wait() print("{}:在".format(self.name)) self.cond.notify() self.cond.wait() print("{}:好啊".format(self.name)) # self.cond.notify() # self.cond.wait() class TianMaoCond(threading.Thread): def __init__(self, cond): super().__init__(name="天猫") self.cond = cond def run(self): with self.cond: # 等价于self.cond.acquire() print("{}:小爱同学".format(self.name)) self.cond.notify() self.cond.wait() print("{}:我们来对古诗吧".format(self.name)) self.cond.notify() # self.cond.wait() # 使用self.cond.acquire 必须调用release方法 if __name__ == '__main__': # Lock方法无法实现 # lock = threading.Lock() # xiao_ai = XiaoAi(lock) # tian_mao = TianMao(lock) # # tian_mao.start() # xiao_ai.start() # 使用Condition实现 # 在调用with cond之后才能调用wait方法或者notify方法 # condition有两层锁,一把底层锁会在线程调用了wait方法的时候释放 # 上面的锁会在每次调用wait的时候分别分配一把并放入到cond的等待队列中。等待notify方法唤醒的时候 condition = threading.Condition() xiao_ai1 = XiaoAi1(condition) tian_mao1 = TianMaoCond(condition) xiao_ai1.start() tian_mao1.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
通过调用with方法(实际是__enter__魔法函数),Condition有两层锁,一把底层锁,会在线程调用了wait()方法时释放,上面的锁会在每次调用wait()时分配一把锁并放入到condition的等待队列中,等待notify()方法的唤醒。
4.4、Semaphores:(有一个参数value可以控制线程(并发数),调用acquire方法value就会减一,如果减少到为0就会阻塞在那儿等待有空位,调用release()value就会加一)
Semaphores内部实质是用Condition完成的,Queue实质也是;
用来控制进入数量的锁(如文件写一般只能一个线程,读可以允许同时多个线程读。
# semaphore 是用于控制进入数量的锁 # 例如: 文件读写。 写一般只用于一个线程写。 读可以允许多个线程 import threading import time class HtmlSpider(threading.Thread): def __init__(self, sem): super(HtmlSpider, self).__init__() self.sem = sem def run(self): time.sleep(2) print("success") self.sem.release() # 可用线程加一 class UrlProducer(threading.Thread): def __init__(self, sem): super().__init__() self.sem = sem def run(self): for i in range(20): self.sem.acquire() # 可用线程减一 html = HtmlSpider(self.sem) html.start() # 不能在这里释放线程。 if __name__ == '__main__': sem = threading.Semaphore(3) # 控制线程数 url_producer = UrlProducer(sem) url_producer.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
五、线程池和进程池
5.1、线程池简介
与semaphore比较: 比semaphore更加容易实现线程数量的控制
import time # as_completed其实是一个生成器 from concurrent.futures import ThreadPoolExecutor, as_completed, wait # 主线程中可以获取某一个线程的状态或者某一个任务的状态。以及返回值 # 当一个线程完成的时候主线程能立即知道 # futures可以让多线程和多进程编码接口一致 def get_html(times): time.sleep(times) print("html success-{}s".format(times)) return times executor = ThreadPoolExecutor(max_workers=2) # 通过submit函数提交执行的函数到线程池中 submit立即返回 task1 = executor.submit(get_html, (3)) task2 = executor.submit(get_html, (2)) # 获取已经成功的task的值 urls = [3, 2, 4, 6] # 批量提交 all_task = [executor.submit(get_html, (url)) for url in urls] # wait 等待执行完成在往下执行 wait(all_task) print("main") for future in as_completed(all_task): data = future.result() print(data) # 通过executor的map获取已经完成的task的值 # for data in executor.map(get_html, urls): # print(data) # done方法判断某个任务是否完成 # print(task1.done()) # result 返回执行结果 # print(task1.result()) """ as_completed源码分析: if timeout is not None: end_time = timeout + time.monotonic() fs = set(fs) total_futures = len(fs) with _AcquireFutures(fs): finished = set( f for f in fs if f._state in [CANCELLED_AND_NOTIFIED, FINISHED]) pending = fs - finished waiter = _create_and_install_waiters(fs, _AS_COMPLETED) finished = list(finished) 以上源码都用来获取已经完成的线程 """
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
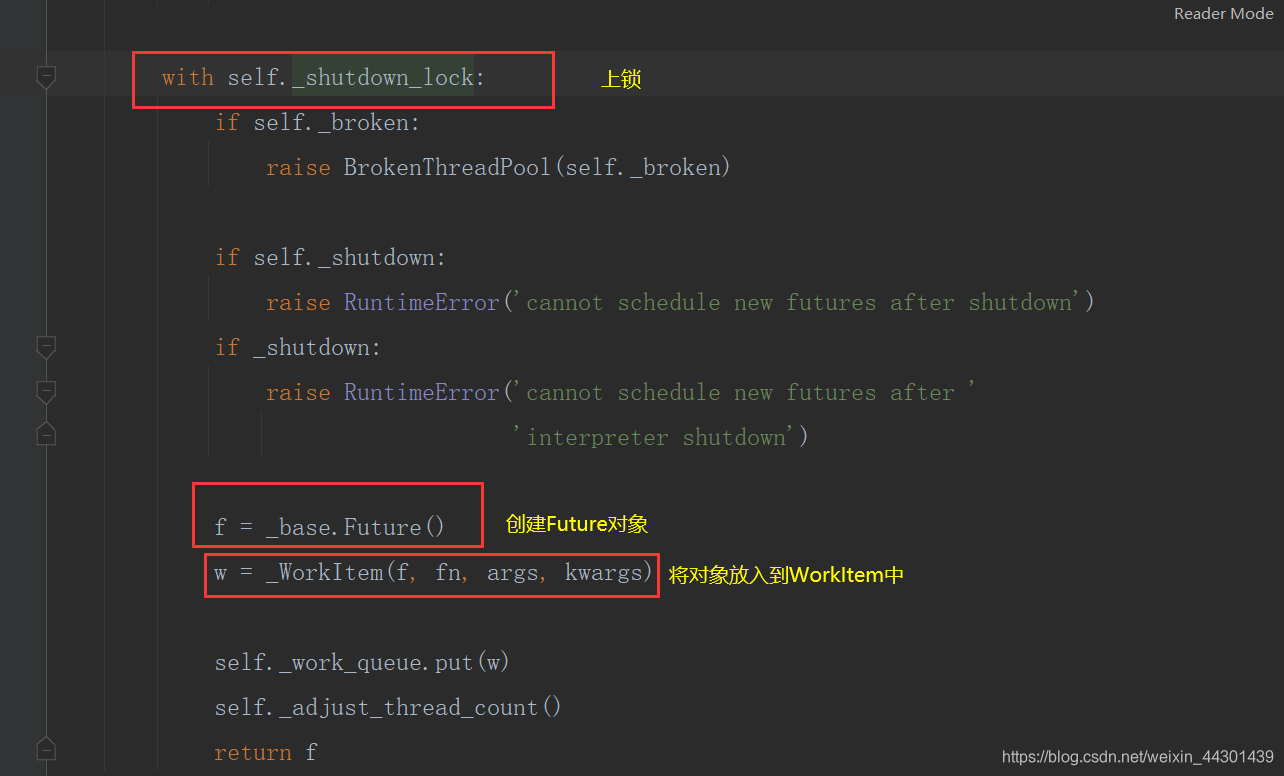
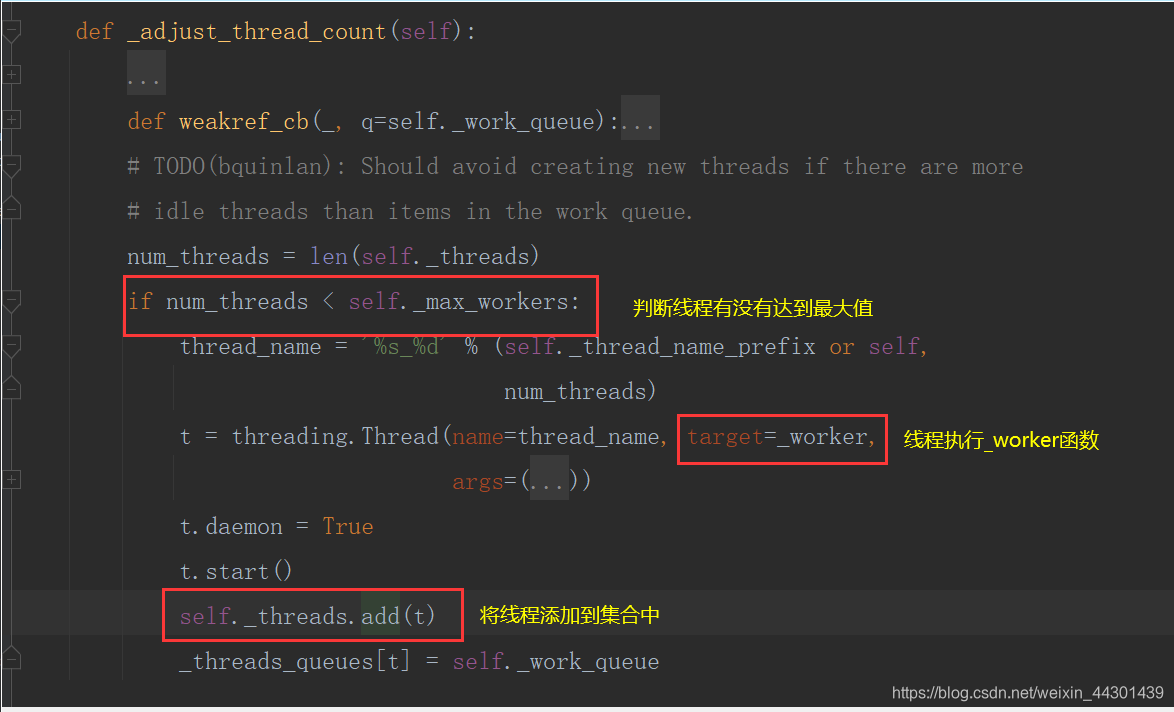
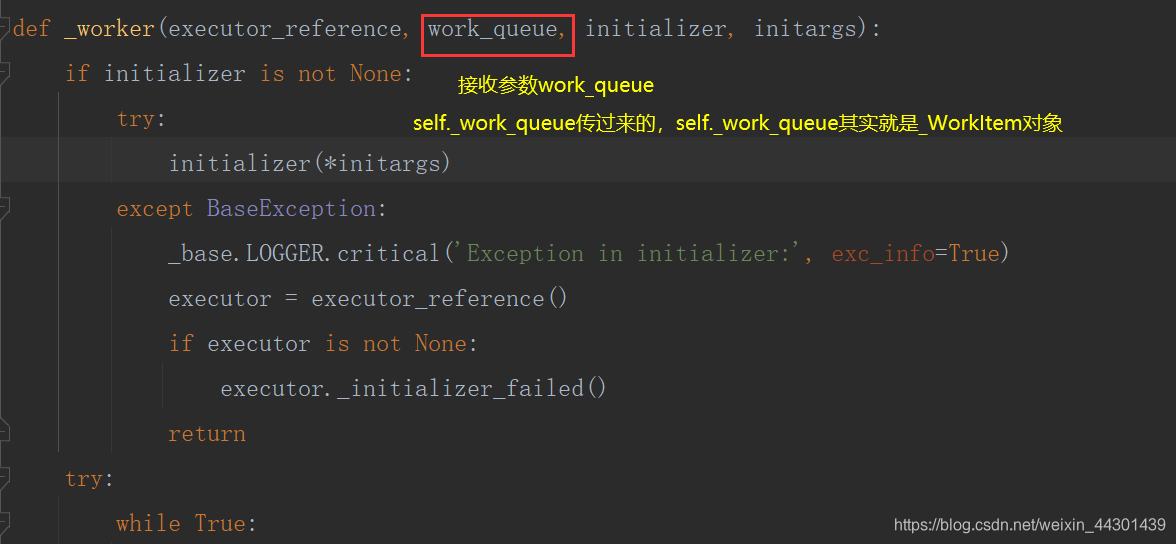
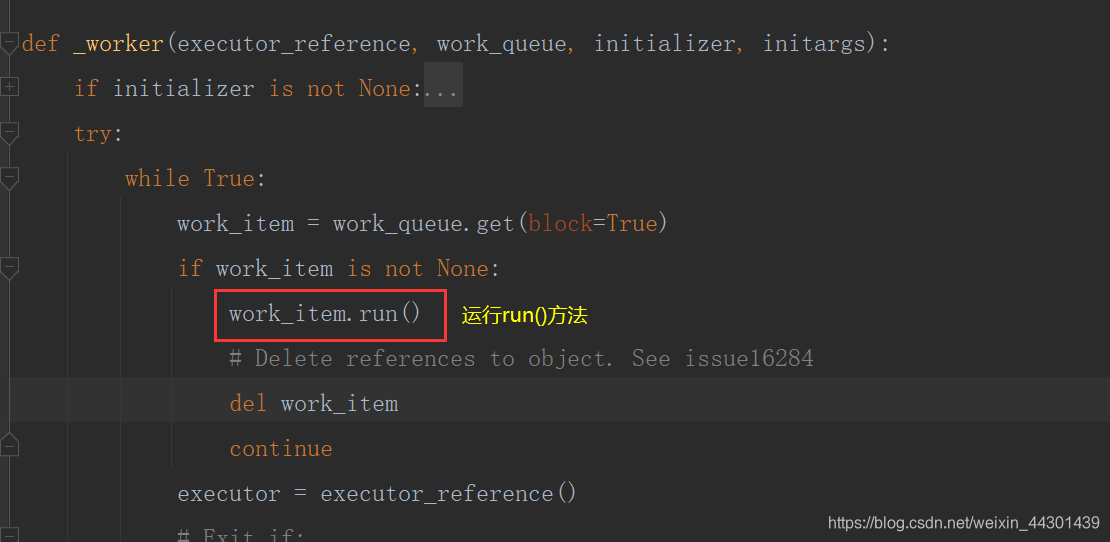
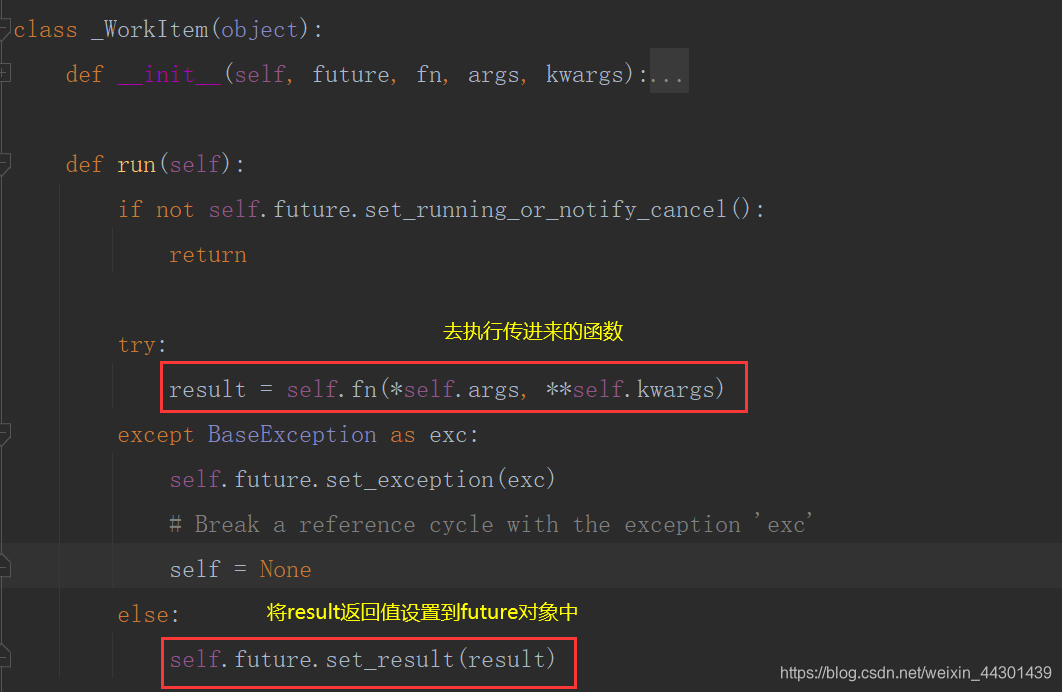
5.2、源码分析
六、多进程编程-multiprocessing
6.1、和多线程对比
- 多进程开销大,多线程开销小
- 耗CPU的操作,多进程编程比多线程编程好很多,对于IO操作来说,使用多线程操作比多进程好(线程切换比进程切换性能高)
6.2、对于耗CPU的操作(多进程优于多线程)
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor,as_completed import time def fib(n): if n<=2: return 1 return fib(n-2)+fib(n-1) if __name__=='__main__': #代码要放在这里面,不然可能抛异常 with ThreadPoolExecutor(3) as excutor: start_time=time.time() all_task=[excutor.submit(fib,num) for num in range(25,40)] for future in as_completed(all_task): data=future.result() print('结果:'+str(data)) print('多线程所需时间:'+str(time.time()-start_time)) ''' 多线程所需时间:72.10901117324829 ''' with ProcessPoolExecutor(3) as excutor: start_time=time.time() all_task=[excutor.submit(fib,num) for num in range(25,40)] for future in as_completed(all_task): data=future.result() print('结果:'+str(data)) print('多进程所需时间:'+str(time.time()-start_time)) ''' 多进程所需时间:43.14996862411499 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
6.3、对于IO操作,多线程由于多进程
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor,as_completed import time def random_sleep(n): time.sleep(n) return n if __name__=='__main__': #代码要放在这里面,不然可能抛异常 with ThreadPoolExecutor(3) as excutor: start_time=time.time() all_task=[excutor.submit(random_sleep,num) for num in [2]*30] for future in as_completed(all_task): data=future.result() print('休息:'+str(data)+'秒') print('多线程所需时间:'+str(time.time()-start_time)) ''' 多线程所需时间:20.010841131210327 ''' with ProcessPoolExecutor(3) as excutor: start_time=time.time() all_task=[excutor.submit(random_sleep,num) for num in [2]*30] for future in as_completed(all_task): data=future.result() print('休息:'+str(data)+'秒') print('多进程所需时间:'+str(time.time()-start_time)) ''' 20.755817651748657 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
6.4、进程池
......
pool=multiprocessing.Pool(3)
#异步提交任务
# result=pool.apply_async(get_html,args=(2,))
# #关闭不在进入进程池
# pool.close()
# pool.join()
# print(result.get())
#和执行顺序一样
for result in pool.imap(get_html,[1,5,3]):
print('{} sleep success'.format(result))
#和先后完成顺序一样
for result in pool.imap_unordered(get_html, [1, 5, 3]):
print('{} sleep success'.format(result))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
七.进程间通信
7.1、共享全局变量在多进程中不适用(会把数据复制到子进程中,数据是独立的,修改也不会影响),quue中的Queue也不行,需要做一些处理
from multiprocessing import Queue,Process import time def producer(queue): queue.put('a') time.sleep(2) def consumer(queue): time.sleep(2) data=queue.get() print(data) if __name__=='__main__': queue=Queue(10) pro_producer=Process(target=producer,args=(queue,)) pro_consumer=Process(target=consumer,args=(queue,)) pro_producer.start() pro_consumer.start() pro_producer.join() pro_consumer.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
7.2、multiprocessing中的Queue不能用于进程池(需要用到manager)
from queue import Queue——>用于多线程
from multiprocessing import Queue——>用于非进程池的多进程通信
from multiprocessing import Manager——>manager.Queue()用于进程池通信
- 1
- 2
- 3
7.3、通过Pipe进行进程间通信(管道),pipe只能适用于两个进程 ,Pipe性能高于queue
from multiprocessing import Pipe import time def producer(pipe): pipe.send('a') time.sleep(2) def consumer(pipe): time.sleep(2) data=pipe.recv() print(data) if __name__=='__main__': #通过Pipe进行进程间通信(管道),pipe只能适用于两个进程 recv_pipe,send_pipe=Pipe() queue=Manager().Queue(10) pro_producer=Process(target=producer,args=(send_pipe,)) pro_consumer=Process(target=consumer,args=(recv_pipe,)) pro_producer.start() pro_consumer.start() pro_producer.join() pro_consumer.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
7.4、进程间共享内存(Manager)
from multiprocessing import Process, Queue, Pipe, Pool, Manager import time # 共享全局变量不能适用于多进程编程,可以适用于多线程。 # multiprocess中的queue不能用于pool进程池。可以使用Manager def product(queue): queue.put("a") time.sleep(2) def consumer(queue): time.sleep(2) data = queue.get() print(data) # 进程共享变量 def process_dict(dic, key, value): dic[key] = value if __name__ == '__main__': # 进程共享变量 process_dict1 = Manager().dict() first_process = Process(target=process_dict, args=(process_dict1, "xiaohao1", 22)) second_process = Process(target=process_dict, args=(process_dict1, "xiaohao2", 23)) first_process.start() second_process.start() first_process.join() second_process.join() print(process_dict1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
推荐阅读
相关标签

