
- 1Mac系统IDEA-tomcat的配置_mac idea配置tomcat
- 2【git】git@github.com: Permission denied (publickey).报错问题_git permission denied (publickey).
- 3【学习记录】Open-WebUI 非Docker安装_openwebui 非容器化部署
- 4基于React的低代码开发:探索应用构建的新模式_react 实现低代码开发
- 5git(3)Git 分支
- 6华为云安装tomcat后配置安全组并且开放8080端口依然无法访问解决_华为云开放8080端口
- 72022高教社杯国赛B题C题如何解决?_2022国赛b题无人机遂行编队飞行中的纯方位无源定位数学建模范文
- 8git pull报错“您对下列文件的本地修改将被合并操作覆盖”_error: 您对下列文件的本地修改将被合并操作覆盖:
- 9Spring Boot整合Elasticsearch完整版之es索引库完整操作篇_springboot整合elasticsearch创建索引
- 107月10日币圈空投糖果推荐_18692296627
c语言字符集改为多字节,多字节与Unicode
赞
踩
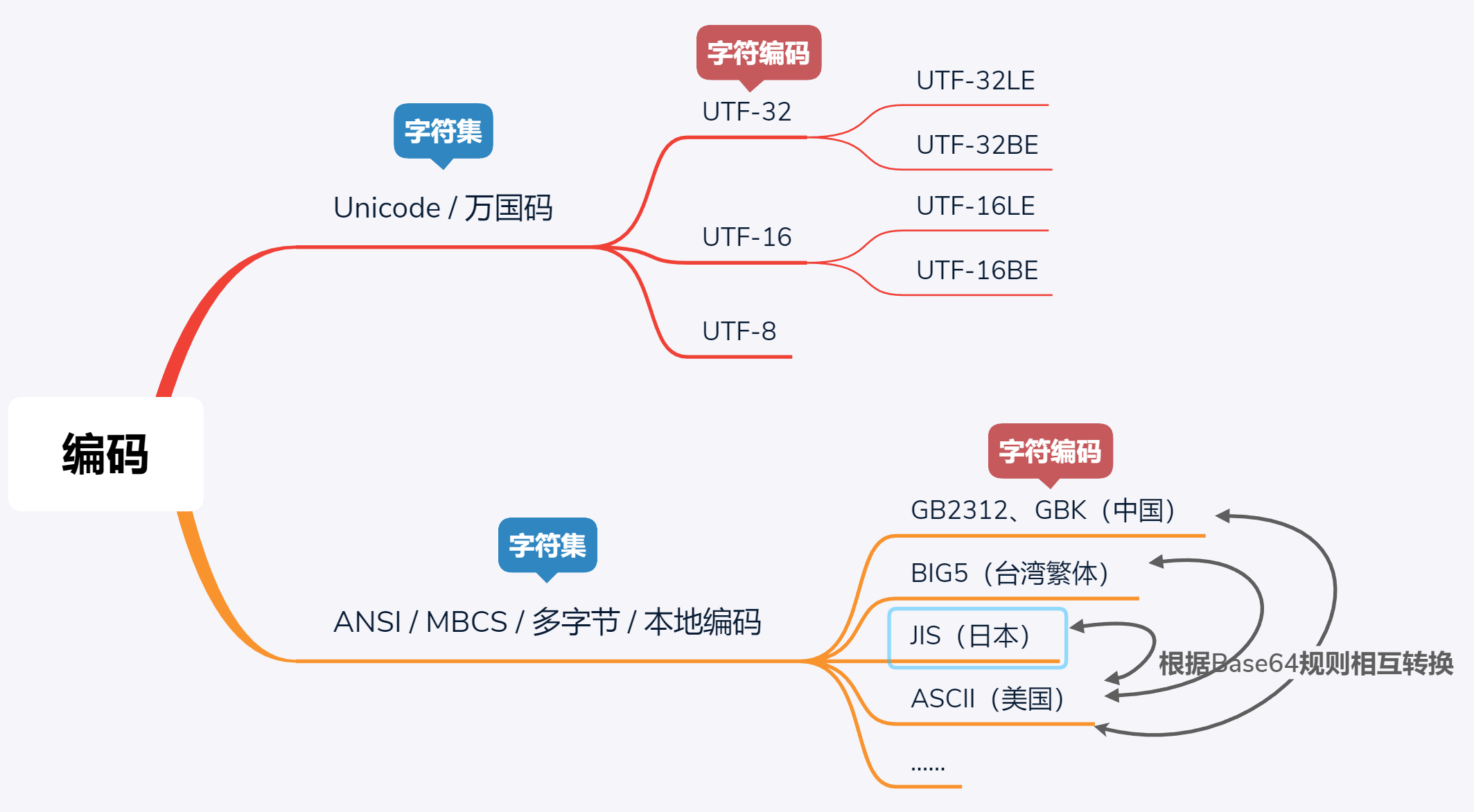
编码知识
一、Unicode与多字节(ANSI )
(1)Windows中,Unicode也称为宽字节,多字节也称为窄字节; VS中默认使用Unicode编码,在项目属性>>配置属性>>常规>>字符集中可选择Unicode字符集或者多字节字符集
(2) Unicode与多字节函数版本、字符、字符串类型的区别
Win32 API中大部分参数有字符串的函数都有两个版本
以A结尾,代表多字节版本
以W结尾,代表Unicode版本
根据版本自动选择的
如:CreateEventA
如:CreateEventW
如:CreateEvent
C运行库也有很多类似的函数
多字节版本
Unicode版本
自适应版本
strcpy
wcscpy
_tcscpy
strcat
wcscat
_tscscat
strlen
wcslen
_tcslen
函数有两种,所以字符也有两种
多字节字符
Unicode字符
自适应字符
char
wchar_t
TCHAR
(3) 常见Win32字符串类型
LPSTR、LPWSTR、LPTSTR、LPCTSTR
LP前缀,代表指针;STR后缀代表字符串
LPSTR:代表多字节
LPWSTR:代表Unicode
LPTSTR:T自适应
LPCTSTR:C代表const+T代表自适应
备注:变量类型使用自适应类型后如LPTSTR,相关字符串需要用TEXT()进行包裹
const char* str = "hello";
const wchar_t* wstr = L"hello";
const TCHAR* tstr = TEXT("hello");
(4)关于_T()
#ifdef _UNICODE
#define _T(X) L ## X //Unicode版本
#else
#define _T(X) X //多字节版本
#endif
(5)Unicode与多字节的选择
1.Unicode程序环境适应能力强,不会出现乱码问题
2.Unicode程序运行速度比多字节程序快。原因:Windows内部都是使用Unicode编码,多字节函数会将参数转码后交给Unicode函数
3.控制后台可使用多字节,GUI程序最好使用Unicode
二、Unicode
(1)Unicode实现方式:UTF-32
以4个byte为编码单元进行定长存储,调度器一次性下发4个byte进行存储任务
主要有两种方式:
大端法UTF-32BE:地址由小向大增加,而数据从高位往低位放 ,在网络上传输数据普遍采用的都是大端
小端法UTF-32LE:地址由小向大增加,而数据从低位往高位放,在英特尔处理器,Windows10操作系统,采用小端法。
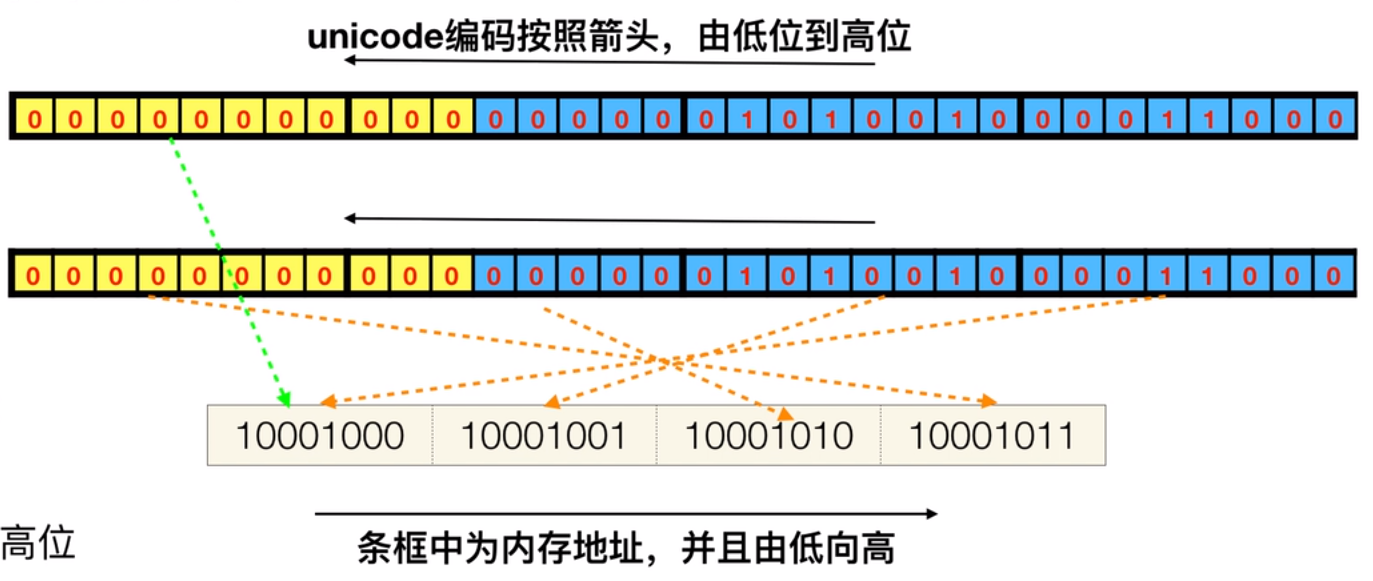
(2)UTF-16
也有大小端模式
UTF-16 LE是windows上默认的Unicode编码方式,使用wchar_t表示。所有wchar_t *类型的字符串(包括硬编码在.h/.cpp里的字符串字面值)
char chinese[] = "你";
//大小为3个byte,一个char存储结束符,两个char存储汉字字符‘你’ 1char:1byte
wchar_t wchinese[] = L"你";
//大小为4个byte, 一个wchar_t存储结束符,一个wchar_t存储汉字字符‘你’ 1wchar_t:2byte(window下)
auto size = sizeof(chinese); // 3 byte
auto wsize = sizeof(wchinese); // 4 byte
auto len = strlen(chinese); // 2个字符(除去结束符)
auto wlen = wcslen(wchinese); // 1个字符(除去结束符)
优势:就是大多数情况下一个wchar_t表示一个字符(包括中文字符)
坑:char *类型的字面值,最终内存使用何种编码方式完全取决于当前文件的编码方式
备注:在Windows上应该铭记没有char / std::string这种类型的字符/字符串,只有wchar_t / char16_t / std::wstring / std::u16string
(3)UTF-8
优势:无字节序的概念,不用考虑大小端问题,适用与字符串的网络数据传输
劣势:如上代码,一个char并不能表示一个汉字字符,往往需要两个char
三、ANSI
(1)概念
可以认为ANSI / MBCS (多字节字符集) / 本地编码是同一个概念,不同的国家和地区制定了不同的标准,有GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的编码标准,ASCII就是美国国家的ANSI标准,一个国家的代码到另一个国家使用,有可能由于编码标准不一致,导致乱码,于是才有了万国码Unicode,各国通用。
总结
Dll的多字节和Unicode
Dll的多字节和Unicode 分类: MFC2013-10-17 13:00 28人阅读 评论(0) 收藏 举报 dll字符集字符集多字节Unicode 我们定义dll的时候会区分: 字符集:使用多 ...
宽字符、多字节、unicode、utf-8、gbk编码转化
今天遇到一个编码的问题,困惑了我很长时间,所以就简要的的了解了一下常用的编码类型. 我们最常见的是assic编码,它是一种单字节编码,对多容纳256个字符. 我们在编程的时候经常遇到unicode,u ...
编程中的多字节和Unicode
在编译许多程序的时候,我们常常会出现诸如指针转换错误或者const char[] 不能转换成XX的错误,这时很可能就是项目编码的问题了,如果您使用的是VS编程环境,那么打开工程属性,里面就有个选项是给 ...
_bstr_t可接受多字节、UNICODE字符串,方便用以字符集转换
使用_bstr_t需要包含的头文件: #include #include // test.cpp : 定义控制台应用程序的入口点. ...
转:Unicode字符集和多字节字符集关系

