
- 1每日一题:Java实现单向链表的反转_java单链表反转
- 2Failed to execute goal org.springframework.boot:spring-boot-maven-plugin:2.6.3:repackage (repackage)
- 3基于深度学习的中文车牌识别与管理系统(含UI界面,Python代码)
- 4工作中安全风险评估
- 5[已解决]AttributeError: module ‘numpy‘ has no attribute ‘float‘_attributeerror: module 'numpy' has no attribute 'f
- 6GitHub two-factor authentication
- 7Android P 获取副摄像头调用权限_org.codeaurora.snapcam为什么能调用不同镜头
- 8机器人领域顶刊TRO,TASE及RAL的区别与关系_ral期刊
- 9华为ensp中nat server 公网访问内网服务器
- 10深度解析 PyTorch Autograd:从原理到实践_pytorch和有限差分
Guava教程-BloomFilter_com/google/common/hash/bloomfilter
赞
踩
在Google Guava library中Google为我们提供了一个布隆过滤器的实现:com.google.common.hash.BloomFilter。在正式使用之前我们先了解一下什么是布隆过滤器。
布隆过滤器介绍
Wiki上关于布隆过滤器介绍
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制矢量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
基本概念
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(\log n),O(n/k)。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。- 1
- 2
- 3
优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数(O(k))。另外, 散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
布隆过滤器可以表示全集,其它任何数据结构都不能;
k和m相同,使用同一组散列函数的两个布隆过滤器的交并差运算可以使用位操作进行。
缺点
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
另外,一般情况下不能从布隆过滤器中删除元素. 我们很容易想到把位数组变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全地删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
在降低误算率方面,有不少工作,使得出现了很多布隆过滤器的变种。
Guava用法
1.BloomFilter构造
BloomFilter提供了create静态方法来创建BloomFilter实例
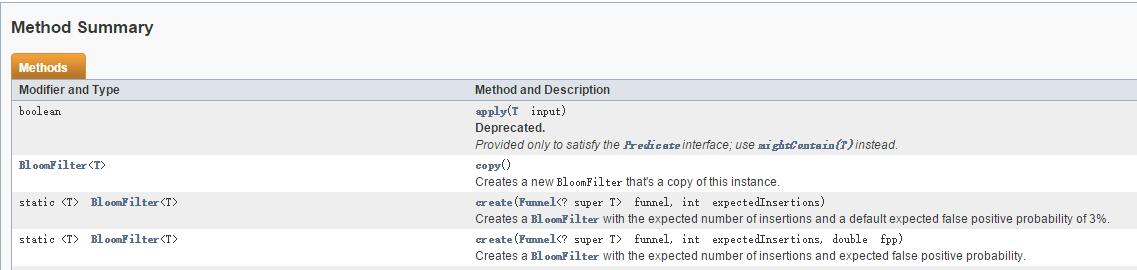
用法如下:
private final BloomFilter<String> dealIdBloomFilter = BloomFilter.create(new Funnel<String>() {
private static final long serialVersionUID = 1L;
@Override
public void funnel(String arg0, PrimitiveSink arg1) {
arg1.putString(arg0, Charsets.UTF_8);
}
}, 1024*1024*32);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
也可以指定fpp( false positive probability)
private final BloomFilter<String> dealIdBloomFilter = BloomFilter.create(new Funnel<String>() {
private static final long serialVersionUID = 1L;
@Override
public void funnel(String arg0, PrimitiveSink arg1) {
arg1.putString(arg0, Charsets.UTF_8);
}
}, 1024*1024*32, 0.0000001d);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
注意事项
正确估计预期插入数量是很关键的一个参数。当插入的数量接近或高于预期值的时候,布隆过滤器将会填满,这样的话,它会产生很多无用的误报点。
2.判断是否已经存在
public synchronized boolean containsDealId(String deal_id){
if(StringUtils.isEmpty(deal_id)){
mLogger.warn("deal_id is null");
return true;
}
boolean exists = dealIdBloomFilter.mightContain(deal_id);
if(!exists){
dealIdBloomFilter.put(deal_id);
}
return exists;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
通过BloomFilter mightContain 判断deal_id是否已经存在了,如果不存在则put到BloomFilter中。
应用场景
Goolge在BigTable中就使用了BloomFilter,以避免在硬盘中寻找不存在的条目。
另外,用爬虫抓取网页时对网页url去重也需要用到BloomFilter。
参考资料:
https://zh.wikipedia.org/wiki/%E5%B8%83%E9%9A%86%E8%BF%87%E6%BB%A4%E5%99%A8

